Clear Sky Science · en
High-entropy advantage in neural networks' generalizability
Why this matters for everyday AI
Modern artificial intelligence systems can recognize faces, translate languages, and predict house prices with uncanny accuracy—yet we still don’t fully understand why they work so well on new, unseen data. This paper tackles that mystery using ideas borrowed from physics. The authors show that the most reliable neural networks are not just those that fit the training data, but those that live in "roomy" regions of their internal parameter space, a property they call a high-entropy advantage.
A new way to look inside neural networks
Instead of treating a neural network as a black box, the researchers imagine every possible setting of its internal weights as a point in a vast landscape. Many different points can fit the training data equally well, but some of those solutions generalize to new data and others do not. Drawing on statistical physics, they treat each specific weight configuration as a microstate and its overall performance—training loss and test accuracy—as macroscopic properties. The key quantity they study is entropy, which here measures how large a region of parameter space corresponds to a given level of training and test performance.
Borrowing tools from molecular simulations
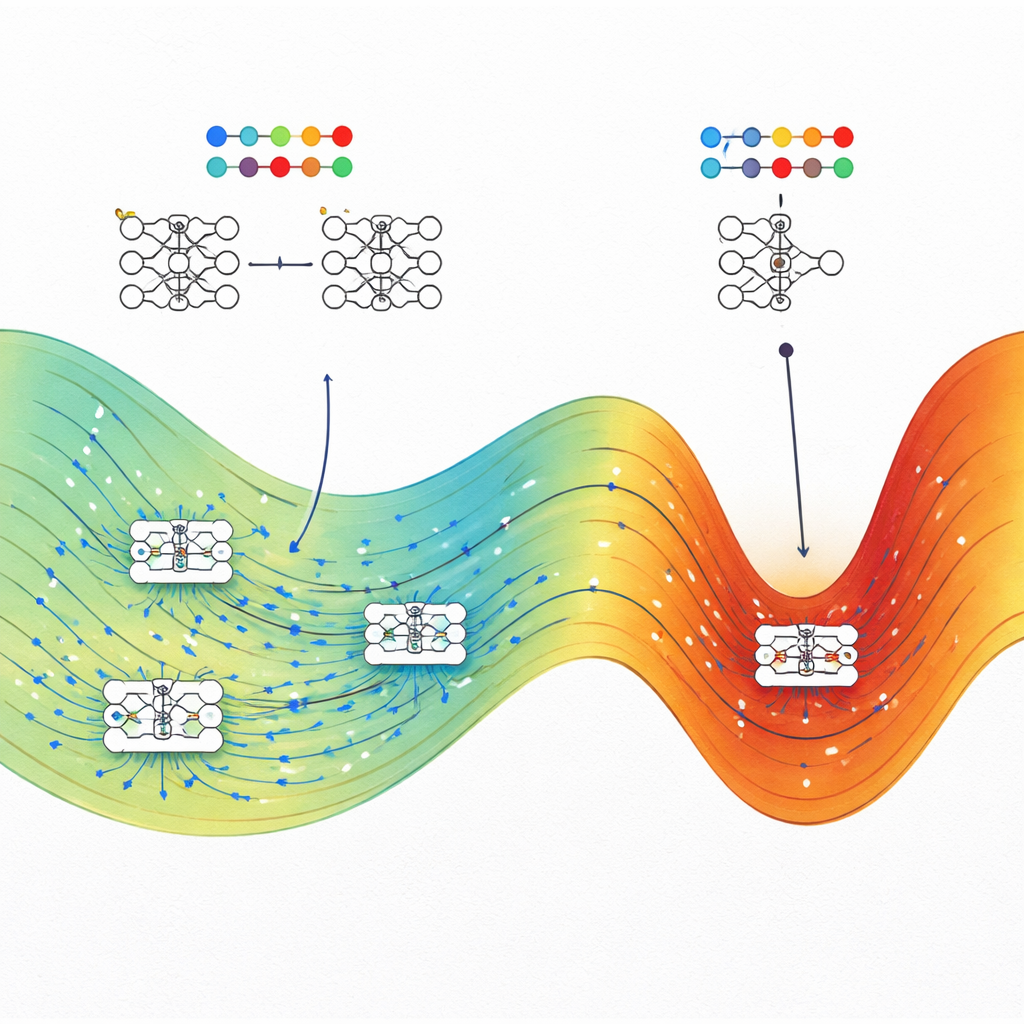
Directly counting how many network configurations achieve a particular performance is impossible, because there are infinitely many continuous weight settings. To get around this, the authors adapt algorithms originally developed to study molecules, known as Wang–Landau Monte Carlo and Wang–Landau Molecular Dynamics. In their analogy, each network weight acts like an atomic coordinate, and the loss function plays the role of potential energy. These sampling methods allow them to map out an "entropy landscape" that shows, for each combination of training loss and test accuracy (or test loss), how much of parameter space is occupied.
High-entropy states win across many tasks
The team applies this framework to four very different problems: a toy spiral classification task, predicting house prices from tabular data, recognizing handwritten digits from a reduced MNIST dataset, and predicting polymer bandgap energies from chemical strings. In each case, they compare typical networks trained with standard optimizers, such as stochastic gradient descent (or Adam in one regression task), to the highest-entropy states found at the same training loss. Consistently, the high-entropy states match or outperform the conventionally trained networks on test data, often by a wide margin when the training loss is low. In classification problems, high-entropy states at high loss behave like random guessers, while at low loss they concentrate near the best achievable accuracy, reinforcing the physical consistency of the approach.
Why smaller networks show a stronger effect
To understand when this advantage is most pronounced, the authors vary the width of neural networks on a spiral regression task and related benchmarks. They find that as networks become wider—approaching the regime where theory says they behave like Gaussian processes—the high-entropy advantage steadily shrinks and can even disappear for very wide models. Narrower, still overparameterized networks exhibit a clear gap: high-entropy states generalize noticeably better than the states reached by standard training. This suggests that in realistic, finite-width networks, the structure of the parameter space and the way training algorithms explore it both matter for generalization.
What this means for building better AI
The central message for non-specialists is that good generalization in neural networks is not an accident. The authors show that, at a given level of training performance, well-generalizing solutions typically occupy a much larger "volume" of possible parameter settings than brittle, overfitted ones. Training methods like stochastic gradient descent tend to land in these large regions, explaining why today's overparameterized models can still perform well without heavy-handed regularization. The work also hints at practical strategies: by deliberately steering training toward maximum-entropy regions—using physics-inspired optimization methods—engineers may be able to make AI systems more robust and reliable without redesigning their architectures from scratch.
Citation: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Keywords: neural network generalization, entropy in machine learning, loss landscape, overparameterized models, statistical physics of AI