Clear Sky Science · nl
Voordeel van hoge entropie voor de generaliseerbaarheid van neurale netwerken
Waarom dit belangrijk is voor alledaagse AI
Moderne kunstmatige intelligentiesystemen kunnen gezichten herkennen, talen vertalen en huizenprijzen voorspellen met opvallende nauwkeurigheid—maar we begrijpen nog steeds niet helemaal waarom ze zo goed presteren op nieuwe, niet eerder geziene gegevens. Dit artikel pakt dat raadsel aan met ideeën uit de natuurkunde. De auteurs laten zien dat de meest betrouwbare neurale netwerken niet alleen diegene zijn die de trainingsdata passen, maar diegene die zich bevinden in "ruimtelijke" gebieden van hun interne parameters, een eigenschap die zij het voordeel van hoge entropie noemen.
Een nieuwe manier om binnenin neurale netwerken te kijken
In plaats van een neurale netwerk als een zwarte doos te behandelen, stellen de onderzoekers zich elke mogelijke instelling van de interne gewichten voor als een punt in een uitgestrekt landschap. Veel verschillende punten kunnen de trainingsdata even goed passen, maar sommige van die oplossingen generaliseren naar nieuwe data en andere niet. Geput uit de statistische fysica behandelen ze elke specifieke gewichtsconfiguratie als een microtoestand en de algehele prestatie—trainingsverlies en testnauwkeurigheid—als macroscopische eigenschappen. De sleutelgrootheid die ze bestuderen is entropie, die hier meet hoe groot een gebied in de parameterruimte is dat overeenkomt met een bepaald niveau van training- en testprestatie.
Gereedschap lenen uit moleculaire simulaties
Het direct tellen hoeveel netwerkconfiguraties een bepaalde prestatie bereiken is onmogelijk, omdat er oneindig veel continue gewichtinstellingen zijn. Om dit te omzeilen passen de auteurs algoritmen aan die oorspronkelijk zijn ontwikkeld om moleculen te bestuderen, bekend als Wang–Landau Monte Carlo en Wang–Landau Molecular Dynamics. In hun analogie gedraagt elk netwerkgewicht zich als een atomaire coördinaat, en fungeert de verliesfunctie als potentiële energie. Deze steekproefmethoden stellen hen in staat een "entropielandschap" in kaart te brengen dat laat zien hoeveel van de parameterruimte wordt ingenomen voor elke combinatie van trainingsverlies en testnauwkeurigheid (of testverlies).
Hoog-entropie toestanden winnen in veel taken
Het team past dit kader toe op vier zeer verschillende problemen: een illustratieve spiraalclassificatietaak, het voorspellen van huizenprijzen uit tabelgegevens, het herkennen van handgeschreven cijfers uit een verkleinde MNIST-dataset, en het voorspellen van bandgapenegergieën van polymeren uit chemische reeksen. In elk geval vergelijken ze typische netwerken die met standaardoptimalisatoren zijn getraind, zoals stochastic gradient descent (of Adam in één regressietaak), met de hoogst-entropische toestanden die bij hetzelfde trainingsverlies zijn gevonden. Consistent presteren de hoog-entropische toestanden gelijk aan of beter dan de conventioneel getrainde netwerken op testdata, vaak met een ruime marge wanneer het trainingsverlies laag is. Bij classificatieproblemen gedragen hoog-entropie toestanden zich bij hoog verlies als willekeurige gokkers, terwijl ze bij laag verlies concentreren rond de best haalbare nauwkeurigheid, wat de fysische consistentie van de benadering versterkt.
Waarom kleinere netwerken een sterker effect laten zien
Om te begrijpen wanneer dit voordeel het sterkst is, variëren de auteurs de breedte van neurale netwerken in een spiraalregressietaak en aanverwante benchmarks. Ze vinden dat naarmate netwerken breder worden—en de regime naderen waarin de theorie zegt dat ze zich als Gaussiaanse processen gedragen—het hoog-entropie voordeel gestaag afneemt en bij zeer brede modellen zelfs kan verdwijnen. Smallere, nog steeds overgeparametriseerde netwerken vertonen een duidelijk verschil: hoog-entropie toestanden generaliseren merkbaar beter dan de toestanden die door standaardtraining worden bereikt. Dit suggereert dat in realistische netwerken met eindige breedte zowel de structuur van de parameterruimte als de manier waarop trainingsalgoritmen deze verkennen van belang zijn voor generalisatie.
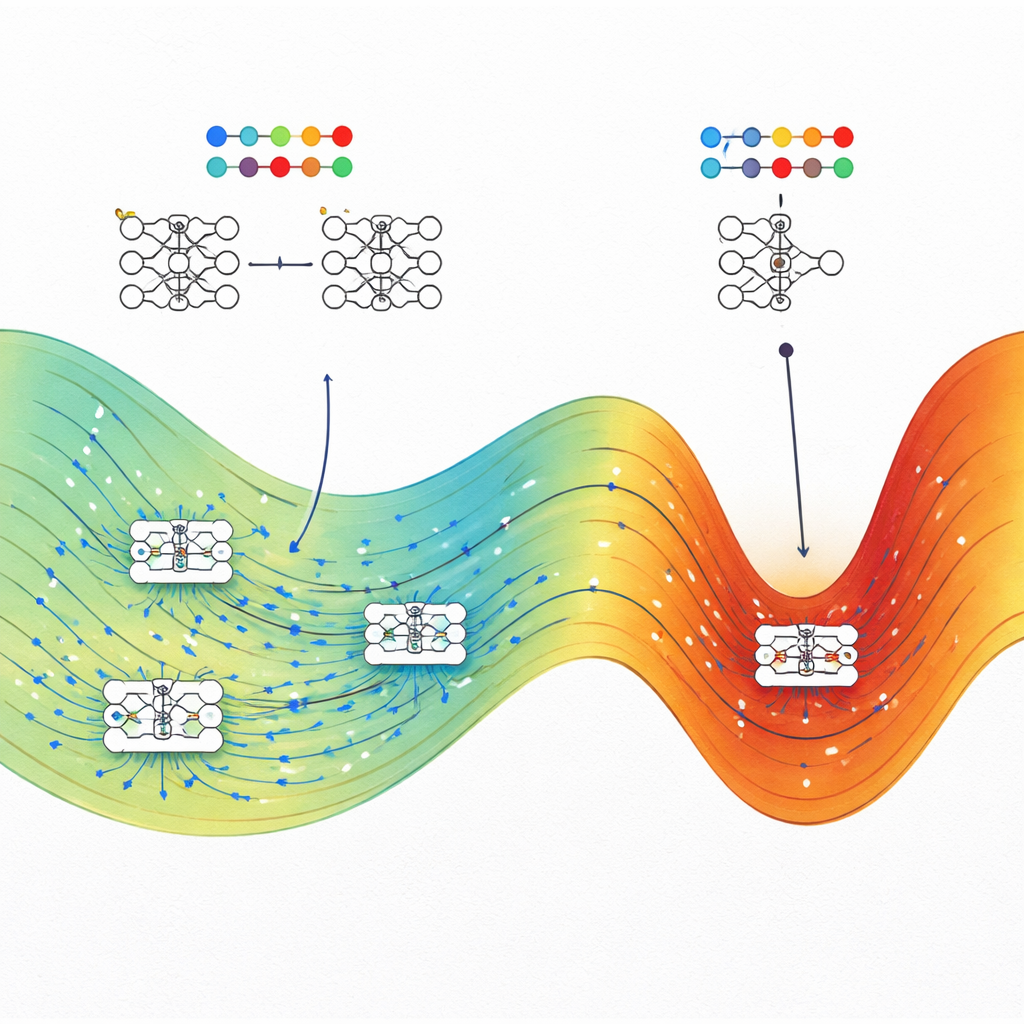
Wat dit betekent voor het bouwen van betere AI
De kernboodschap voor niet-specialisten is dat goede generalisatie in neurale netwerken geen toeval is. De auteurs tonen aan dat, bij een gegeven niveau van trainingsprestatie, goed-generaliserende oplossingen typisch een veel groter "volume" van mogelijke parameterinstellingen bezetten dan fragiele, overgefitte oplossingen. Trainingsmethoden zoals stochastic gradient descent belanden vaak in deze grote regio's, wat verklaart waarom de huidige overgeparametriseerde modellen nog steeds goed kunnen presteren zonder ingrijpende regularisatie. Het werk wijst ook op praktische strategieën: door het trainen doelbewust naar maximale-entropie regio's te sturen—met fysica-geïnspireerde optimalisatiemethoden—kunnen ingenieurs AI-systemen robuuster en betrouwbaarder maken zonder hun architecturen volledig te herontwerpen.
Bronvermelding: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Trefwoorden: generaliseerbaarheid van neurale netwerken, entropie in machine learning, verlieslandschap, overgeparametriseerde modellen, statistische fysica van AI