Clear Sky Science · ru
Преимущество высокой энтропии в обобщающей способности нейронных сетей
Почему это важно для повседневного ИИ
Современные системы искусственного интеллекта умеют распознавать лица, переводить языки и предсказывать цены на дома с поразительной точностью — тем не менее мы по‑прежнему не до конца понимаем, почему они хорошо работают на новых, невиденных данных. В этой работе эту загадку исследуют с опорой на идеи из физики. Авторы показывают, что наиболее надёжные нейронные сети — не просто те, что подгоняют тренировочные данные, а те, которые «обитают» в просторных регионах внутреннего пространства параметров; это свойство они называют преимуществом высокой энтропии.
Новый взгляд внутрь нейронных сетей
Вместо того чтобы рассматривать нейронную сеть как «чёрный ящик», исследователи представляют каждую возможную конфигурацию весов как точку в огромном ландшафте. Многие разные такие точки могут одинаково хорошо подгонять тренировочные данные, но некоторые из этих решений обобщаются на новые данные, а другие — нет. Пользуясь подходами статистической физики, они рассматривают каждую конкретную конфигурацию весов как микросостояние, а её общую производительность — тренировочный убыток и тестовую точность — как макроскопические характеристики. Ключевая величина исследования — энтропия, которая здесь измеряет, насколько большая область пространства параметров соответствует заданному уровню тренировочной и тестовой производительности.
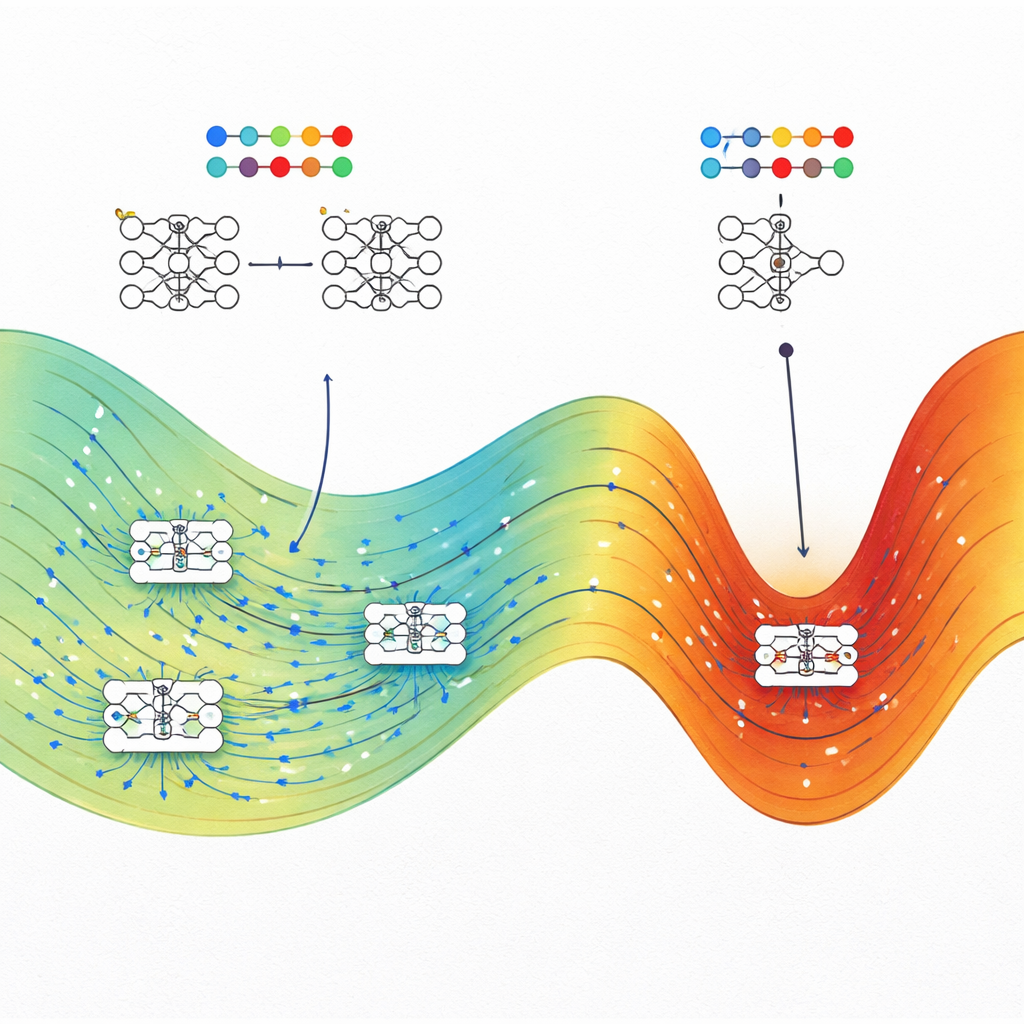
Заимствование инструментов у молекулярных симуляций
Непосредственно пересчитать, сколько конфигураций сети достигают определённой производительности, невозможно, поскольку существует бесконечное множество непрерывных настроек весов. Чтобы обойти это, авторы адаптируют алгоритмы, разработанные для изучения молекул, известные как метод Ванга–Ландау Монте‑Карло и Ванга–Ландау молекулярной динамики. В их аналогии каждый вес сети ведёт себя как координата атома, а функция потерь играет роль потенциальной энергии. Эти методы выборки позволяют построить «ландшафт энтропии», показывающий, для каждой комбинации тренировочного убытка и тестовой точности (или тестовой функции потерь), какая доля пространства параметров занята.
Состояния с высокой энтропией побеждают в разных задачах
Команда применяет эту методику к четырём весьма разным задачам: игрушечной задаче классификации спирали, предсказанию цен на дома по табличным данным, распознаванию рукописных цифр на уменьшенном наборе MNIST и предсказанию полос запрещённой зоны (bandgap) полимеров по химическим строкам. В каждом случае они сравнивают типичные сети, обученные стандартными оптимизаторами (например, стохастическим градиентным спуском или Adam в одной задаче регрессии), с наиболее высокоэнтропийными состояниями при том же тренировочном убытке. Последовательно оказывается, что состояния с высокой энтропией совпадают или превосходят по тестовой производительности обычные обученные сети, часто с заметным отрывом при низком тренировочном убытке. В задачах классификации состояния с высокой энтропией при большом убытке ведут себя как случайные угадыватели, тогда как при низком убытке они концентрируются рядом с наилучшей достижимой точностью, что подтверждает физическую согласованность подхода.
Почему эффект сильнее в меньших сетях
Чтобы понять, когда преимущество наиболее заметно, авторы варьируют ширину сетей на задаче регрессии спирали и связанных бенчмарках. Они обнаруживают, что по мере расширения сетей — приближаясь к режиму, где теория предсказывает поведение как гауссовских процессов — преимущество высокой энтропии постепенно уменьшается и может вовсе исчезнуть для очень широких моделей. Уже, но всё ещё избыточно параметризованные сети демонстрируют явный разрыв: состояния с высокой энтропией обобщают заметно лучше, чем состояния, достигаемые стандартным обучением. Это указывает на то, что в реалистичных сетях конечной ширины структура пространства параметров и способы его обхода алгоритмами обучения оба важны для обобщения.
Что это значит для создания лучшего ИИ
Главная мысль для неспециалистов: хорошее обобщение в нейронных сетях — не случайность. Авторы показывают, что при заданном уровне тренировочной производительности хорошо обобщающие решения обычно занимают гораздо больший «объём» возможных настроек параметров, чем хрупкие, переобученные решения. Методы обучения вроде стохастического градиентного спуска склонны попадать в эти объёмные регионы, что объясняет, почему современные избыточно параметризованные модели могут хорошо работать без жёсткой регуляризации. Работа также намекает на практические стратегии: целенаправленное ведение обучения к областям максимальной энтропии — с помощью оптимизаций, вдохновлённых физикой — может позволить инженерам сделать ИИ более устойчивым и надёжным, не перестраивая архитектуры с нуля.
Цитирование: Yang, E., Zhang, X., Shang, Y. et al. High-entropy advantage in neural networks' generalizability. npj Artif. Intell. 2, 44 (2026). https://doi.org/10.1038/s44387-026-00100-7
Ключевые слова: обобщение нейронных сетей, энтропия в машинном обучении, ландшафт функции потерь, переобученные модели с избыточными параметрами, статистическая физика ИИ