Clear Sky Science · tr
SPARTAN: gelişmiş OpenCV sezgileri ve OCR teknikleri kullanarak belgelerden otomatik tablo tespiti ve çıkarımı
Neden akıllı tablolar önemlidir
Günümüz iş ve araştırma süreçlerini döndüren bilgilerin büyük kısmı; ürün değişiklik bildirimlerinden bilimsel makalelere ve sertifikalara kadar PDF dosyalarındaki tablolarda saklanır. Bu tablolar insan gözüne düzenli görünse de, milyonlarca sayfanın otomatik olarak işlenmesi gerektiğinde bilgisayarlar için okunmaları zordur. Bu makale, sıradan PDF’lerden temiz, kullanılabilir tabloları hızlı, güvenilir ve maliyetli yapay zeka donanımı gerektirmeden çıkarmayı amaçlayan açık kaynaklı bir sistem olan SPARTAN’ı tanıtıyor.
Bugünün dijital evrak işlerinin sorunu
PDF’ler raporlar, bildirimler ve teknik belgeler için yatay formatlardır çünkü herhangi bir ekranda veya yazıcıda aynı görünürler. Bu görsel tutarlılık gizli bir maliyetle gelir: PDF’ler genellikle içeriklerinin yapısına dair ipuçlarından yoksundur. Düz metin nispeten kolay çıkarılabilirken tablolar çok daha karmaşıktır. Farklı düzenler, eksik sınırlar, birleştirilmiş hücreler ve çok seviyeli başlıklar vardır; hatta tablolar görüntü olarak gömülmüş olabilir. Satırlar ve boşluk gibi basit ipuçlarına dayanan önceki kural tabanlı araçlar hızlıydı ama basit ızgaraların ötesinde başarısız oluyordu. Yeni derin öğrenme yaklaşımları karmaşık tabloları daha iyi tanır, ancak geniş etiketli veri setleri, güçlü GPU’lar gerektirir ve kara kutu davranışları nedeniyle maliyetli ve güvenilmesi zor olabilir.
Tabloları okumanın farklı bir yolu
SPARTAN (Structured Parsing and Relevant Table Analysis), ağır sinir ağları yerine özenle hazırlanmış görüntü işleme kuralları kullanarak orta yolu seçer. Python ile yazıldı ve OpenCV ile optik karakter tanımaya (OCR) dayanır; sıradan CPU’larda çalışır ve herhangi bir eğitim adımı veya devasa veri seti gerektirmez. Sistem her PDF sayfasını standartlaştırılmış gri tonlamalı bir görüntüye dönüştürerek ve metin, tablolar ile arka plan arasındaki kontrastı artırarak başlar. İsteğe bağlı bir sütun algılama adımı, bilimsel makaleler gibi çok sütunlu düzenlere sahip sayfaları böler, böylece sonraki aşamalar metin sütunlarını tablo sütunlarıyla karıştırmaz. Bu dikkatli hazırlık, boru hattının geri kalanının tutarlı, gürültü azaltılmış görüntüler üzerinde çalışmasını sağlar.
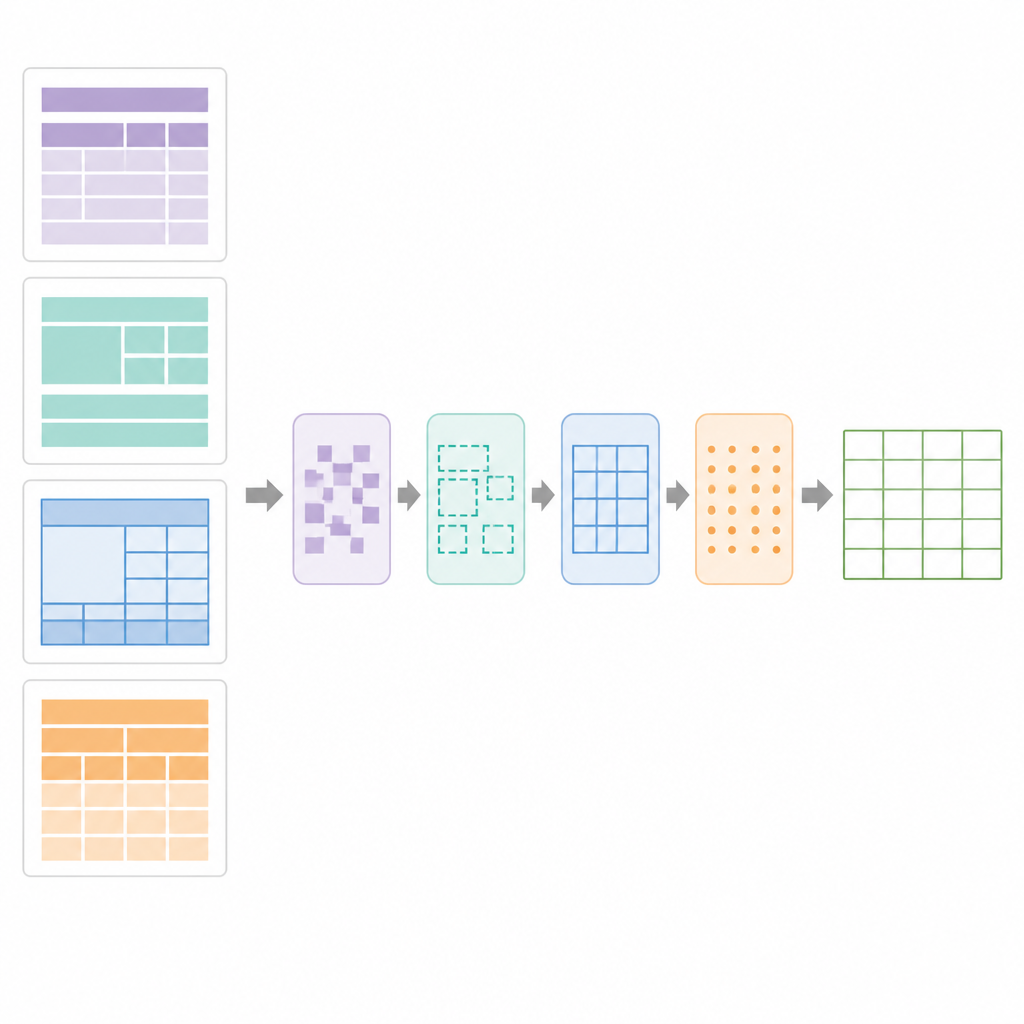
SPARTAN tabloları nasıl bulur ve yeniden kurar
SPARTAN’ın merkezinde, her sayfayı dört bölgeye ayıran bir bölge segmentasyonu stratejisi vardır: ilk tablodan önceki metin, tablolar arasındaki metin, son tablodan sonraki metin ve tablo alanları. Görünür çerçeveli tablolar için sistem çizgileri tespit eder, hücre biçimindeki konturları gruplar ve bunları aday tablolar halinde kümeler. Çerçevesiz tablolar için kelimelerin dikey ve yatay hizalanma düzenlerine bakar, hizalamadan sütunları ve satırları çıkarır ve sonraki adımların bunları normal ızgaralar gibi işlemelerine izin vermek için “sözde” sınırlar çizer. Bir düzeltme aşaması kırık sınırları onarmak, yabancı çizgileri kaldırmak ve geçerli tablo ızgaralarını doğrulamak için hassas çizgi-segment tespiti kullanır. Ardından, bir veri kürasyonu modülü anahtar–değer tabloları, normal satır-sütun tablolarını, iç içe başlıkları ve birleştirilmiş hücreleri tespit etmek için ızgarayı analiz eder. Daha sonra OCR'nin akıllıca uygulanabilmesi için hangi hücrelerin birden çok satır veya sütunu kapsadığını kaydeden dijital bir plan oluşturur.
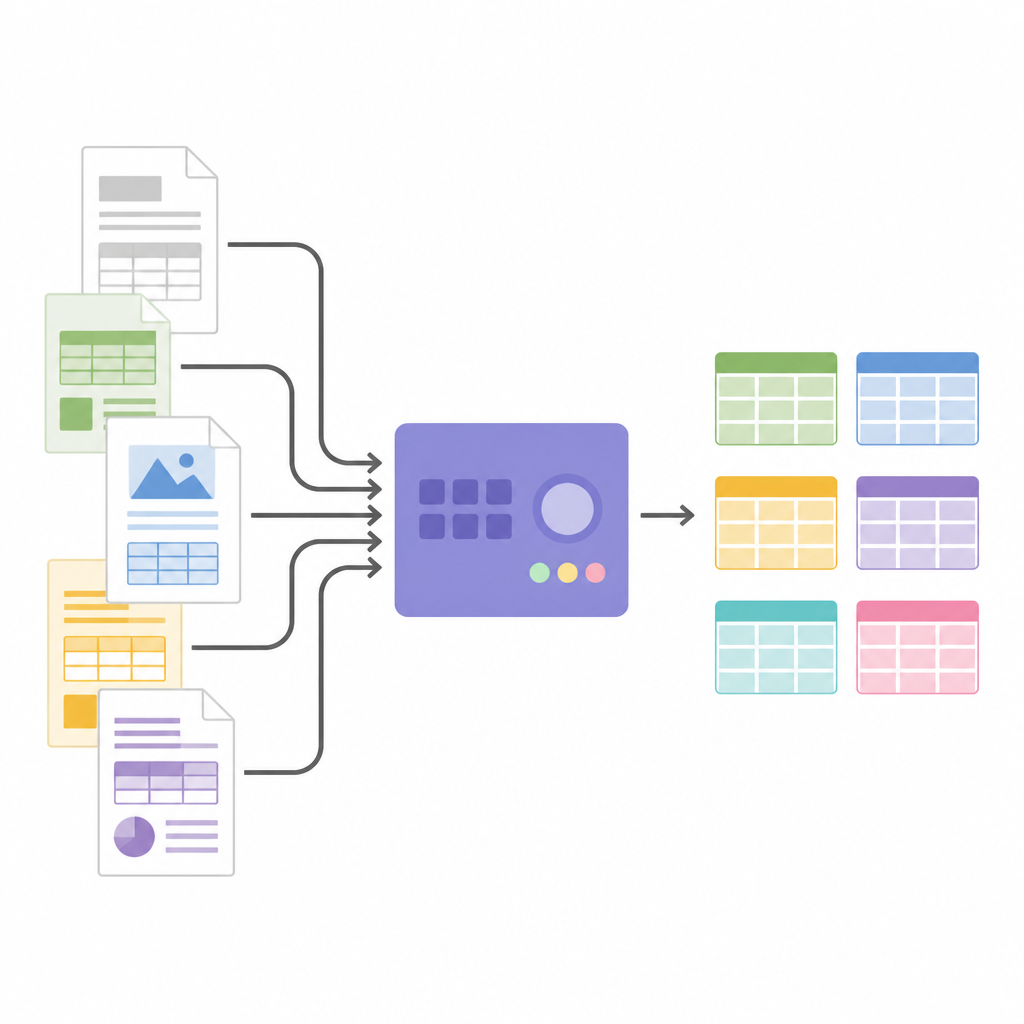
Görüntüleri yapılandırılmış verilere dönüştürmek
Tablo yapısı belirlendikten sonra SPARTAN hücre görüntülerini kırpar ve bunları bir OCR motoruna gönderir. İki stratejiyi destekler: maksimum doğruluk için her hücreyi tek tek okumak veya tablolar büyük olduğunda işlemi hızlandırmak için hücre gruplarını birlikte okumak. Her kırpmayı biraz küçültmek ve hücreler arasında görünmez ayırıcı görüntüler kullanmak gibi kurnaz yöntemler yaygın OCR hatalarından kaçınmaya ve satırların hizasını korumaya yardımcı olur. Sistem sayfalar arasında ilişkili tabloları birleştirebilir ve her şeyi analiz veya diğer yazılımlara besleme için hazır JSON veya CSV olarak dışa aktarır. Mimari modüler olduğu için kullanıcılar OCR motorlarını değiştirebilir, eşik değerleri ayarlayabilir veya çekirdek tablo bulma mantığını değiştirmeden sütunları etiketlemek, bilgi grafikleri oluşturmak veya belirli gerçekleri çıkarmak için son aşamada büyük dil modelleri takabilirler.
Gerçek dünyada ne kadar iyi çalışıyor
Yazarlar SPARTAN’ı elektronik ürün değişiklik bildirimleri, bilimsel dergiler, sertifikalar ve veri sayfalarından alınan yirmi binden fazla sayfada test ettiler; bunların arasında zorlu çerçevesiz ve iç içe tablolar da vardı. Tabula, TabbyPDF, Deepdoctection ve EMbTTBF gibi popüler araçlarla karşılaştırıldığında, SPARTAN tablo tespitinde daha yüksek doğruluk, duyarlılık ve genel F1 skorları elde etti; OCR sonrası karakter doğruluğunda da daha iyi sonuçlar verdi. Ayrıca çoğu derin öğrenme tabanlı sistemden daha hızlı çalıştı ve çok daha az bellek kullandı; tipik bir sayfayı standart bir dizüstü bilgisayarda birkaç saniyede tamamladı. Ana zayıf yönler çok düşük kaliteli taramalarda veya son derece dekoratif düzenlerde ortaya çıktı; sistem şüpheli tabloları yanlış pozitiflerle doldurmak yerine kaçırmayı tercih ediyor.
Günlük kullanıcılar için anlamı nedir
Büyük AI altyapılarına yatırım yapamayan küçük ve orta ölçekli kuruluşlar için SPARTAN, iyi tasarlanmış kurallar ve modern görüntü analizinin hâlâ güçlü araçlar olduğunu gösteriyor. Günlük PDF’lerden tabloları açığa çıkarmak ve bunları elektronik tabloların, veritabanlarının ve analiz araçlarının anlayabileceği yapılandırılmış verilere dönüştürmek için şeffaf ve ayarlanabilir bir yol sunuyor. Bunu yaparken basit, kırılgan betikler ile ağır sinir ağları arasındaki uçurumu daraltarak karmaşık belgelerle çalışan herkes için büyük ölçekli, açıklanabilir tablo çıkarımını daha erişilebilir kılıyor.
Atıf: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Anahtar kelimeler: PDF tabloları, belge analizi, tablo çıkarımı, OCR, OpenCV