Clear Sky Science · ja
SPARTAN: 高度な OpenCV ヒューリスティクスと OCR 技術を用いた文書からの自動表検出および抽出
スマートな表が重要な理由
現代のビジネスや研究で利用される情報の多くは、製品変更通知や学術論文、証明書などの PDF ファイル内の表に収められています。これらの表は人間の目には整って見えますが、特に何百万ページもの処理が必要な場合、コンピュータが自動的に読み取るのは困難です。本論文は、日常的な PDF から素早く信頼性高く、そして高価な AI ハードウェアなしで使えるクリーンな表を抽出するオープンソースシステム SPARTAN を紹介します。
今日のデジタル文書が抱える問題
PDF はレポート、請求書、技術文書の実働フォーマットであり、どの画面やプリンタでも同じ見え方をします。その視覚的一貫性には見えない代償があります。PDF は通常、内容の構造を示す手がかりを欠いています。プレーンテキストは比較的容易に抽出できますが、表ははるかに厄介です。異なるレイアウト、欠けた罫線、結合セルや多層ヘッダー、さらには画像として埋め込まれている場合もあります。以前の単純な線や空白に依存するルールベースのツールは高速でしたが、単純なグリッドを超えると脆弱でした。近年のディープラーニング手法は複雑な表をよりよく認識しますが、大量のラベル付きデータ、強力な GPU を必要とし、ブラックボックス的で信頼や費用の面で課題があります。
表を読むための別の道筋
SPARTAN(Structured Parsing and Relevant Table Analysis)は、重厚なニューラルネットワークの代わりに巧妙に設計された画像処理ルールを用いることで中道を取ります。Python で実装され、OpenCV と光学文字認識(OCR)上に構築されているため、普通の CPU 上で動作し、学習ステップや巨大なデータセットを必要としません。システムはまず各 PDF ページを標準化されたグレースケール画像に変換し、テキスト、表、背景のコントラストを強調します。オプションのカラム検出ステップは、学術論文のような複数カラムのレイアウトを分割して、後続の段階が本文の列と表の列を混同しないようにします。この入念な前処理により、パイプラインの残りが一貫性のあるノイズ低減済みの画像で動作できるようになります。
SPARTAN が表を見つけ再構築する方法
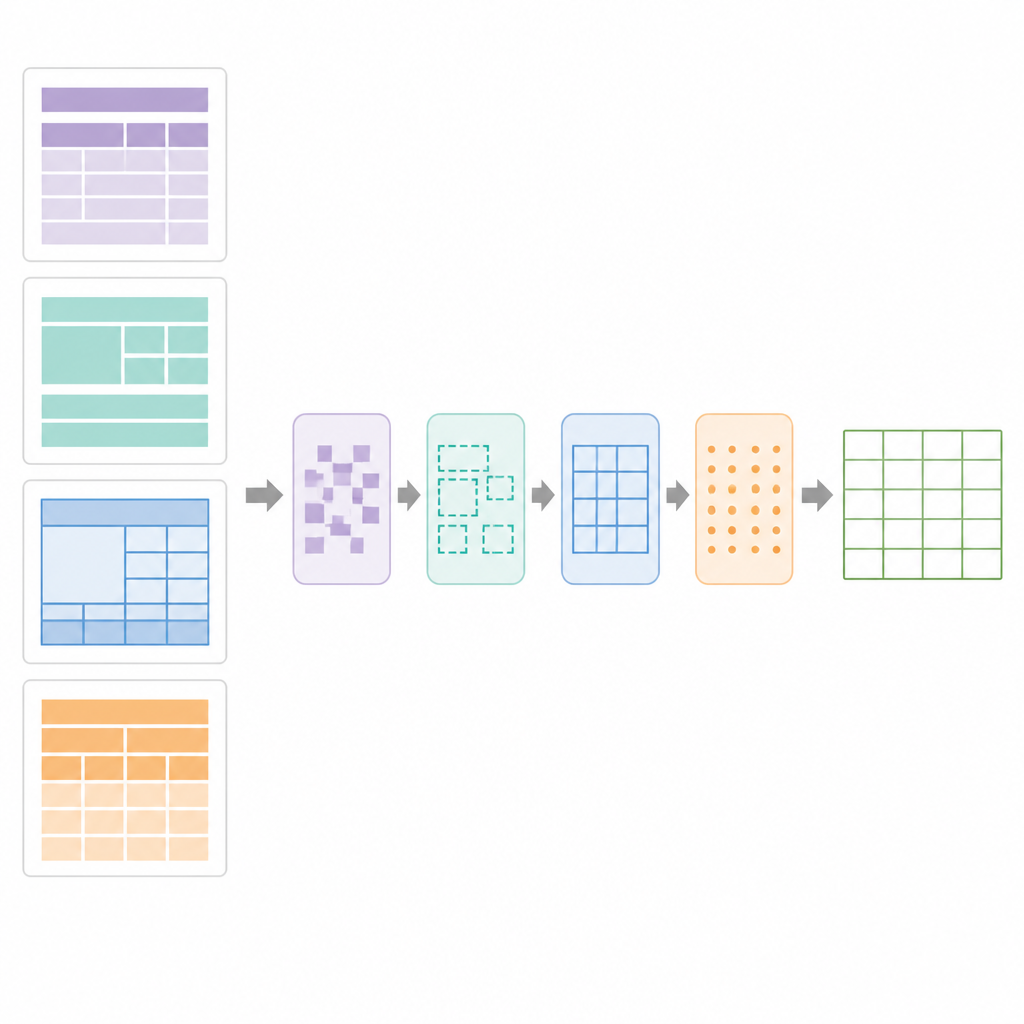
SPARTAN の中核は領域分割戦略で、各ページを 4 つのゾーンに分けます:最初の表の前のテキスト、表間のテキスト、最後の表の後のテキスト、そして表領域自体です。罫線のある表では、システムは線を検出し、セル状の輪郭をグルーピングして候補表にクラスタリングします。罫線のない表では、単語の垂直・水平の整列を調べ、整列パターンから列と行を推定し、後続処理が通常のグリッドとして扱えるように「擬似」境界を引きます。精緻化段階では、正確な線分検出を用いて壊れた罫線を修復し、不要な線を除去し、有効な表グリッドを確認します。次にデータキュレーションモジュールがグリッドを解析し、キー–バリュー型表、通常の行列表、ネストされたヘッダーや結合セルを検出します。そして、どのセルが複数行または複数列に跨るかを記録したデジタル設計図を作成し、OCR を賢く適用できるようにします。
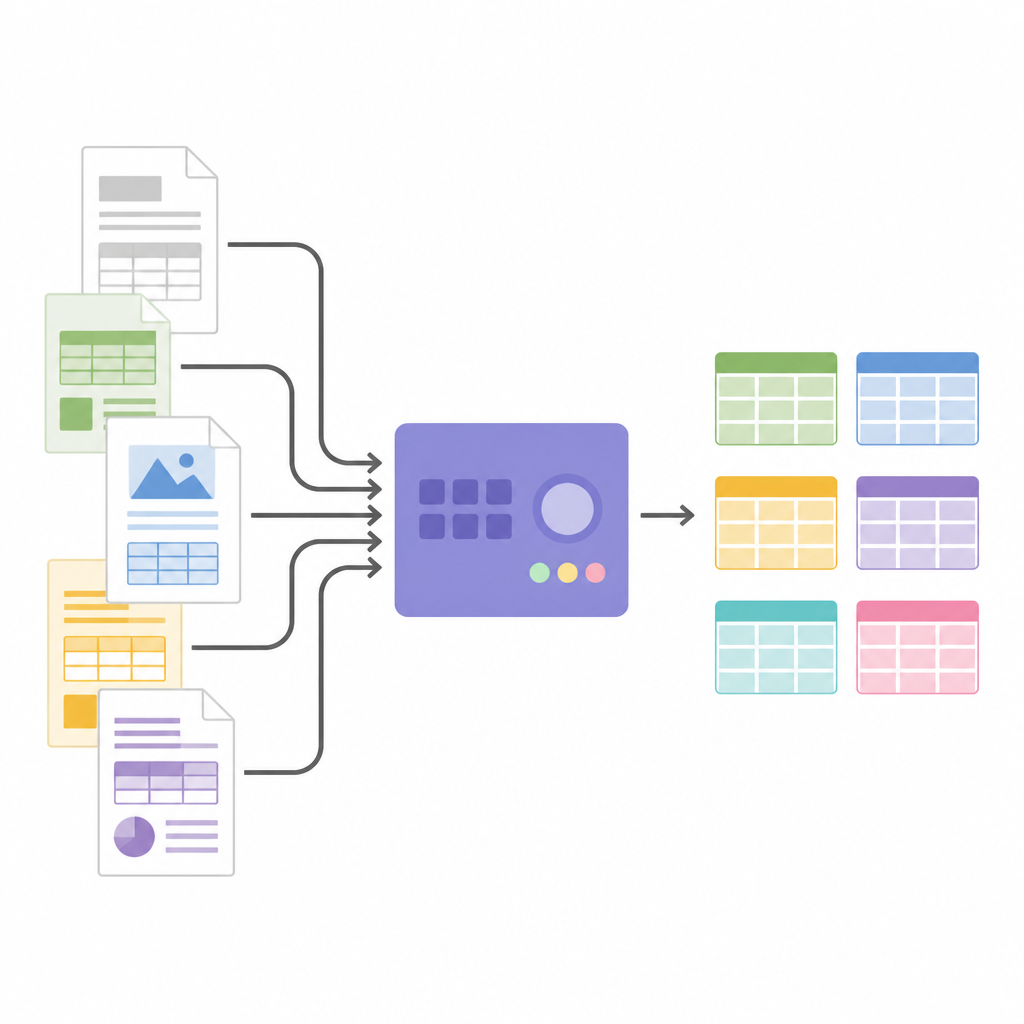
画像を構造化データに変える
表の構造が分かると、SPARTAN はセル画像を切り出して OCR エンジンに送ります。サポートする戦略は二つあります:最大の精度を目指してセルを一つずつ読む方法、または表が大きいときに処理を高速化するためにセル群をまとめて読む方法です。各切り出しをわずかに縮めたり、セル間に透明な区切り画像を挿入するような工夫により、一般的な OCR エラーを避け、行の整列を保ちます。システムは複数ページにまたがる関連表を結合でき、すべてを JSON または CSV としてエクスポートして解析や他のソフトウェアへの投入に備えます。アーキテクチャはモジュール式であるため、ユーザーは OCR エンジンを入れ替えたり、閾値を調整したり、最後に大規模言語モデルを差し込んで列にラベル付けしたりナレッジグラフを構築したり特定の事実を抽出したりできますが、表検出の主要ロジックを変更する必要はありません。
現実世界での性能
著者らは、電子製品の変更通知、学術誌、証明書、データシートから抽出した 2 万ページ以上で SPARTAN を評価しました。そこには罫線のない表やネストされた表が多数含まれていました。Tabula、TabbyPDF、Deepdoctection、EMbTTBF といった一般的なツールと比較して、SPARTAN は表検出の精度、再現率、総合 F1 スコアで高い成績を示し、OCR 後の文字精度も優れていました。また、ほとんどのディープラーニングベースのシステムより高速でメモリ使用量も少なく、標準的なノートパソコン上で典型的なページを数秒で処理しました。主な弱点は非常に低品質なスキャンや装飾の多いレイアウトで現れ、そうした場合は誤検出で出力を溢れさせるよりも疑わしい表を見逃す方を優先します。
日常の利用者にとっての意味
大規模な AI インフラを導入できない中小組織にとって、SPARTAN は、適切に設計されたルールと最新の画像解析が依然として強力なツールであることを示しています。日常的な PDF から表を取り出してスプレッドシート、データベース、分析ツールが理解できる構造化データに変える、透明で調整可能な手段を提供します。これにより、単純で壊れやすいスクリプトと重量級のニューラルネットワークの間のギャップを埋め、複雑な文書を扱う誰にとっても大規模で説明可能な表抽出をより身近にします。
引用: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
キーワード: PDF 表, 文書解析, 表抽出, OCR, OpenCV