Clear Sky Science · he
SPARTAN: זיהוי וחילוץ טבלאות אוטומטי מתוך מסמכים באמצעות היוריסטיקות המתקדמות של OpenCV וטכניקות OCR
מדוע טבלאות חכמות חשובות
רוב המידע שמניע עסקים ומחקר מודרני שוכן בתוך טבלאות בקבצי PDF, החל מהודעות על שינויי מוצרים ועד מאמרים מדעיים ותעודות. טבלאות אלה נראות מסודרות לעין אנושית, אך מחשבים נתקלים בקושי בקריאתן באופן אוטומטי, במיוחד כשיש צורך לעבד מיליוני עמודים. המאמר מביא את SPARTAN, מערכת קוד‑פתוח שנועדה לחלץ במהירות, באמינות וללא חומרה יקרה מבוססת בינה מלאכותית טבלאות נקיות ושימושיות מתוך PDF יומיומיים.
הבעיה בניירת הדיגיטלית של היום
PDF הם פורמט העבודה לדו"חות, דפי חשבון ומסמכים טכניים מכיוון שהם נראים אותו הדבר בכל מסך או מדפסת. אמון זה בוויזואליות מסתיר עלות: קבצי PDF בדרך כלל חסרים רמזים על מבנה התוכן. בעוד שטקסט פשוט ניתן לחילוץ יחסית בקלות, טבלאות מורכבות יותר. הן מגיעות בפריסות שונות, עם גבולות חסרים, תאי מיזוג וכותרות רב‑שכבתיות, ולעתים אף מוטמעות כתמונות. כלים מבוססי חוקים ישנים שהתמקדו בקווים וריווח היו מהירים אך נשברו מול כל פריסה מעבר לרשתות פשוטות. גישות חדשות מבוססות‑למידה עמוקה מזהות טבלאות מורכבות טוב יותר, אך הן דורשות מערכי נתונים מתוייגים גדולים, GPUs חזקים ופועלות כקופסאות שחורות—מה שהופך אותן ליקרות וקשות לאמינה.
דרך שונה לקריאת טבלאות
SPARTAN (Structured Parsing and Relevant Table Analysis) לוקח נתיב ביניים באמצעות כללי עיבוד‑תמונה מעוצבים בקפידה במקום רשתות עצביות כבדות. כתוב בפייתון ובנוי על OpenCV וזיהוי תווים אופטי (OCR), הוא רץ על CPUs רגילים ואינו דורש שלב אימון או מאגרי נתונים עצומים. המערכת מתחילה בהמרת כל עמוד PDF לתמונה אפורה סטנדרטית ומחדדת את הניגודיות בין טקסט, טבלאות ורקע. שלב אופציונלי לגילוי עמודות מפרק דפים בעלי פריסות רב‑עמודות, כמו מאמרים מדעיים, כדי שמספרי השלבים שלאחר מכן לא יתבלבלו בין עמודות טקסט לעמודות טבלה. ההכנה הזו מאפשרת לשאר צינור העיבוד לפעול על תמונות עקביות ומפחיתות רעש.
כיצד SPARTAN מוצא ומבנה מחדש טבלאות
בלב SPARTAN נמצאת אסטרטגיית סגמנטציה שמחלקת כל עמוד לארבעה אזורים: הטקסט לפני הטבלה הראשונה, הטקסט בין טבלאות, הטקסט אחרי הטבלה האחרונה ואז אזורי הטבלאות עצמם. עבור טבלאות עם גבולות נראים, המערכת מזהה קווים, מאגדת קווי מתאר בצורת תאים ומקבצת אותם לטבלאות מועמדות. עבור טבלאות ללא גבולות, היא בוחנת כיצד מילים מסודרות בהקמה אנכית ואופקית, מסיקה עמודות ושורות מתוך דפוסי יישור ואז מציירת גבולות "פסאודו" כדי ששאר השלבים יטפלו בהן כרשתות רגילות. שלב של שיפור משתמש בגילוי מקטעי קווים מדויקים לתיקון גבולות שבורים, הסרת קווים מיותרים ואישור רשתות טבלה תקפות. לאחר מכן מודול סידור‑הממצאים (data‑curation) מנתח את הרשת לזהות טבלאות מפתח‑ערך, טבלאות רגילות שורה‑עמודה, כותרות מקוננות ותאי מיזוג. הוא בונה שרטוט דיגיטלי של הטבלה, מתעד אילו תאים משתרעים על מספר שורות או עמודות כדי ש‑OCR יתבצע בצורה חכמה.
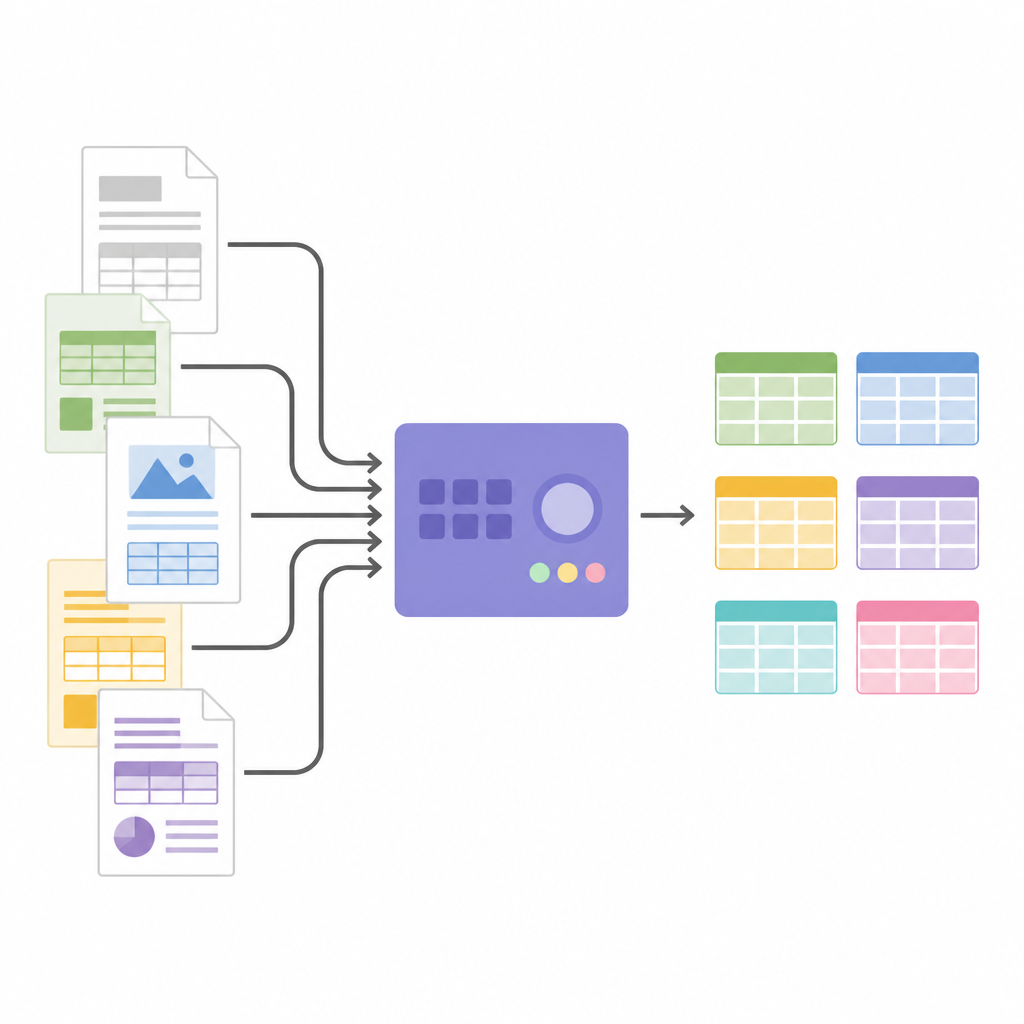
הפיכת תמונות לנתונים ממוסדים
כאשר מבנה הטבלה ידוע, SPARTAN גוזר תמונות של תאים ושולח אותן למנוע OCR. הוא תומך בשתי אסטרטגיות: קריאת כל תא בנפרד למקסימום דיוק, או קריאת קבוצות תאים יחד להאצת העיבוד כאשר הטבלאות גדולות. תחבולות חכמות, כגון כיווץ קל של כל חיתוך ושימוש בתמונות מפרידות בלתי נראות בין תאים, מסייעות להימנע מטעויות OCR נפוצות ולשמור על יישור השורות. המערכת יכולה לאחד טבלאות קשורות על פני עמודים ולייצא הכל כ‑JSON או CSV, מוכן לניתוח או להזנה לתוכנות אחרות. בזכות ארכיטקטורה מודולרית ניתן להחליף מנועי OCR, לכוונן ספים או לחבר מודלים לשפה גדולים בסוף לצורך תיוג עמודות, בניית גרפי ידע או חילוץ עובדות ספציפיות מבלי לשנות את הלוגיקה המרכזית של מציאת הטבלאות.
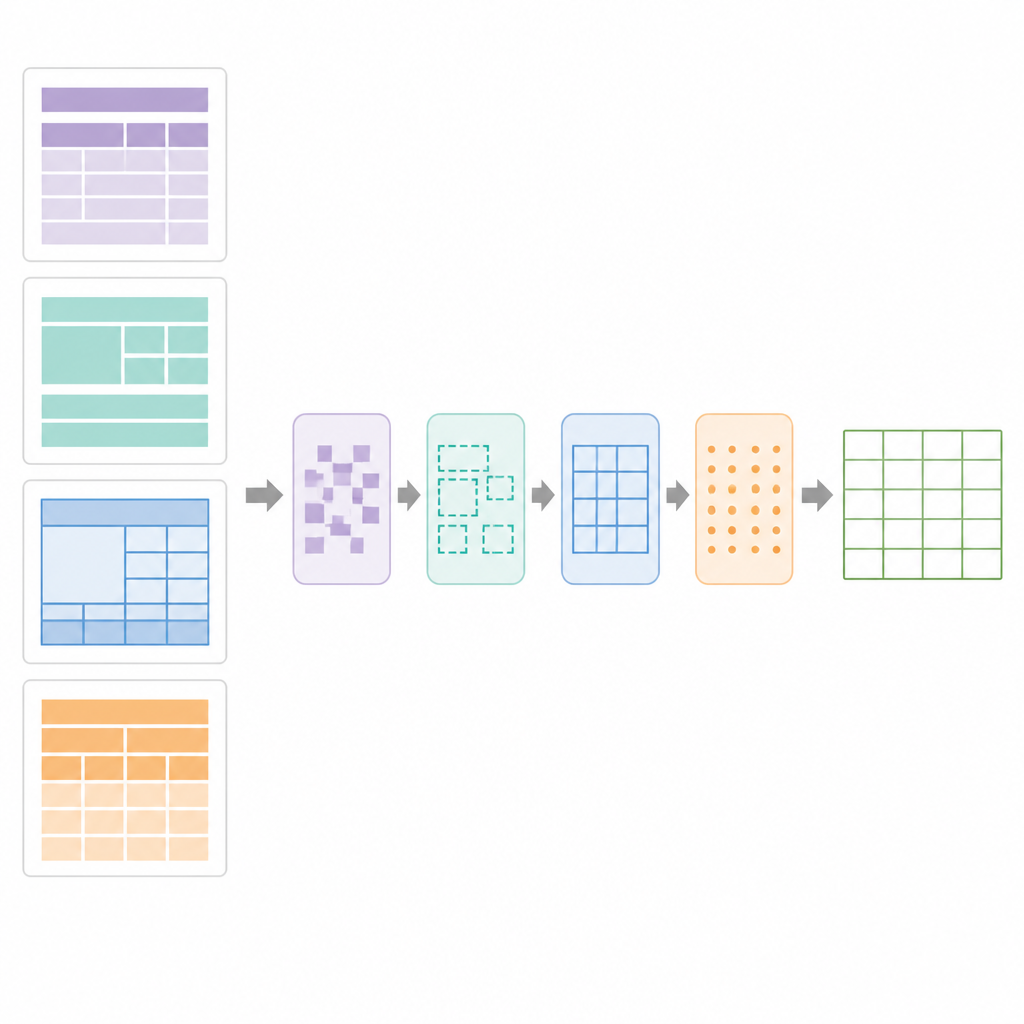
כמה טוב זה עובד בעולם האמיתי
המחברים בחנו את SPARTAN על יותר מעשרים אלף עמודים שנלקחו מהודעות שינוי מוצר אלקטרוניות, כתבי עת מדעיים, תעודות וגיליונות נתונים, כולל טבלאות רבות חסרות גבולות ומקוננות. בהשוואה לכלים נפוצים כגון Tabula, TabbyPDF, Deepdoctection ו‑EMbTTBF, SPARTAN השיג דיוק, אחזור וניקוד F1 גבוהים יותר בזיהוי טבלאות, יחד עם דיוק תווים משופר לאחר OCR. הוא גם רץ מהר יותר מרוב המערכות המבוססות למידה עמוקה והשתמש בזיכרון הרבה פחות, כאשר עיבוד עמוד טיפוסי הושלם בכמה שניות על מחשב נייד סטנדרטי. נקודות התורפה העיקריות הופיעו בסריקות באיכות נמוכה מאוד או בפריסות דקורטיביות מאוד, שם המערכת מעדיפה לפספס טבלאות ספקולטיביות מאשר להציף את הפלט בתוצאות שגויות.
מה זה אומר למשתמשים היומיומיים
לארגונים קטנים ובינוניים שאינם יכולים להרשות לעצמם תשתיות AI גדולות, SPARTAN מראה כי חוקים מיועדים היטב וניתוח תמונה מודרני עדיין הם כלים רבי‑עוצמה. הוא מציע דרך שקופה וכווננת לשחרור טבלאות מתוך PDF יומיומיים ולהפיכתן לנתונים ממוסדים שנקלטים על ידי גיליונות אלקטרוניים, מסדי נתונים וכלי אנליטיקה. בכך הוא מצמצם את הפער בין סקריפטים פשוטים ופריכים לבין רשתות עצביות כבדות, ומנגיש חילוץ טבלאות בקנה‑מידה גדול ובר־הסבר לכל מי שעובד עם מסמכים מורכבים.
ציטוט: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
מילות מפתח: טבלאות PDF, ניתוח מסמכים, חילוץ טבלאות, OCR, OpenCV