Clear Sky Science · pt
SPARTAN: detecção e extração automatizada de tabelas em documentos usando heurísticas avançadas do OpenCV e técnicas de OCR
Por que tabelas inteligentes importam
Muita da informação que move negócios e pesquisas modernas vive dentro de tabelas em arquivos PDF, desde avisos de alteração de produto até artigos científicos e certificados. Essas tabelas parecem organizadas para olhos humanos, mas computadores têm dificuldade em lê-las automaticamente, especialmente quando milhões de páginas precisam ser processadas. Este artigo apresenta o SPARTAN, um sistema open-source projetado para extrair rapidamente e com confiabilidade tabelas limpas e utilizáveis de PDFs do dia a dia, sem exigir hardware caro de inteligência artificial.
O problema com a papelada digital atual
PDFs são o formato padrão para relatórios, demonstrativos e documentos técnicos porque aparecem iguais em qualquer tela ou impressora. Essa confiabilidade visual tem um custo oculto: PDFs geralmente não fornecem pistas sobre a estrutura do conteúdo. Enquanto texto simples pode ser extraído com relativa facilidade, tabelas são muito mais complexas. Elas apresentam layouts variados, bordas ausentes, células mescladas e cabeçalhos em múltiplos níveis, e podem até estar incorporadas como imagens. Ferramentas antigas baseadas em regras que dependiam de pistas simples como linhas e espaços funcionavam rápido, mas quebravam diante de tudo além de grades simples. Abordagens mais recentes com deep learning reconhecem tabelas complexas melhor, mas exigem grandes conjuntos rotulados, GPUs poderosas e se comportam como caixas-pretas, tornando-as caras e difíceis de confiar.
Um caminho diferente para ler tabelas
O SPARTAN (Structured Parsing and Relevant Table Analysis) segue uma via intermediária ao usar regras de processamento de imagem cuidadosamente projetadas em vez de redes neurais pesadas. Implementado em Python e construído sobre OpenCV e reconhecimento ótico de caracteres (OCR), roda em CPUs comuns e não precisa de etapa de treinamento nem de conjuntos massivos de dados. O sistema começa convertendo cada página do PDF em uma imagem padrão em tons de cinza e realçando o contraste entre texto, tabelas e fundo. Uma etapa opcional de detecção de colunas divide páginas com layouts multicolonas, como artigos científicos, para que estágios posteriores não confundam colunas de texto com colunas de tabela. Essa preparação cuidadosa configura o restante do pipeline para trabalhar com imagens consistentes e com ruído reduzido.
Como o SPARTAN encontra e reconstrói tabelas
No coração do SPARTAN está uma estratégia de segmentação de região que divide cada página em quatro zonas: o texto antes da primeira tabela, o texto entre tabelas, o texto após a última tabela e as próprias áreas de tabela. Para tabelas com bordas visíveis, o sistema detecta linhas, agrupa contornos em forma de células e as clusteriza em tabelas candidatas. Para tabelas sem bordas, ele avalia o alinhamento vertical e horizontal das palavras, inferindo colunas e linhas a partir dos padrões de alinhamento e então desenhando limites “pseudo” para que etapas posteriores possam tratá-las como grades normais. Uma fase de refinamento usa detecção precisa de segmentos de linha para reparar bordas quebradas, remover linhas soltas e confirmar grades de tabela válidas. Em seguida, um módulo de curadoria de dados analisa a grade para identificar tabelas chave–valor, tabelas normais por linha e coluna, cabeçalhos aninhados e células mescladas. Ele então constrói um projeto digital da tabela, registrando quais células ocupam múltiplas linhas ou colunas para que o OCR seja aplicado de forma inteligente.
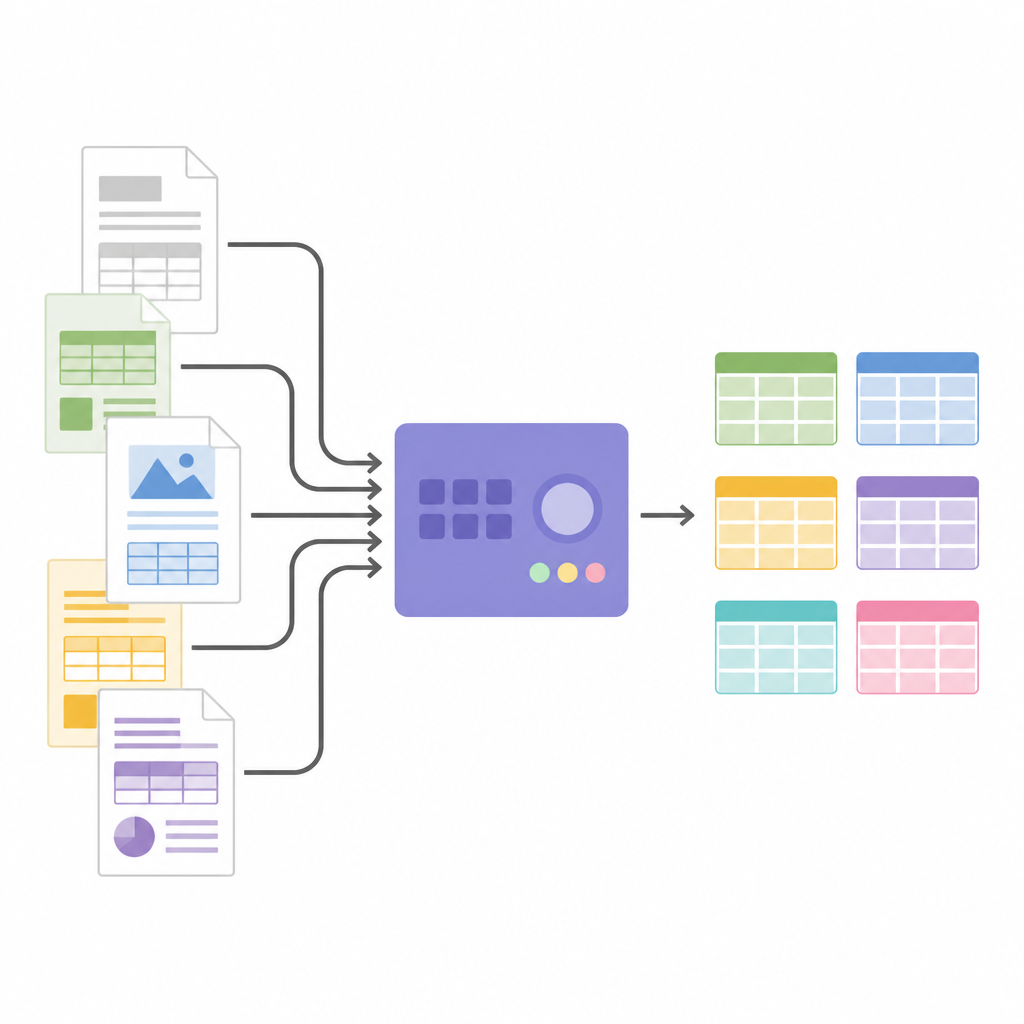
Transformando imagens em dados estruturados
Uma vez conhecida a estrutura da tabela, o SPARTAN recorta as imagens das células e as envia para um motor de OCR. Suporta duas estratégias: ler cada célula individualmente para máxima precisão, ou ler grupos de células juntos para acelerar o processamento quando as tabelas são grandes. Truques inteligentes, como encolher ligeiramente cada recorte e usar imagens separadoras invisíveis entre células, ajudam a evitar erros comuns de OCR e mantêm as linhas alinhadas. O sistema pode mesclar tabelas relacionadas em várias páginas e exporta tudo em JSON ou CSV, pronto para análise ou para alimentar outros softwares. Como a arquitetura é modular, usuários podem trocar motores de OCR, ajustar limiares ou conectar modelos de linguagem grandes no final para rotular colunas, construir grafos de conhecimento ou extrair fatos específicos sem alterar a lógica central de identificação de tabelas.
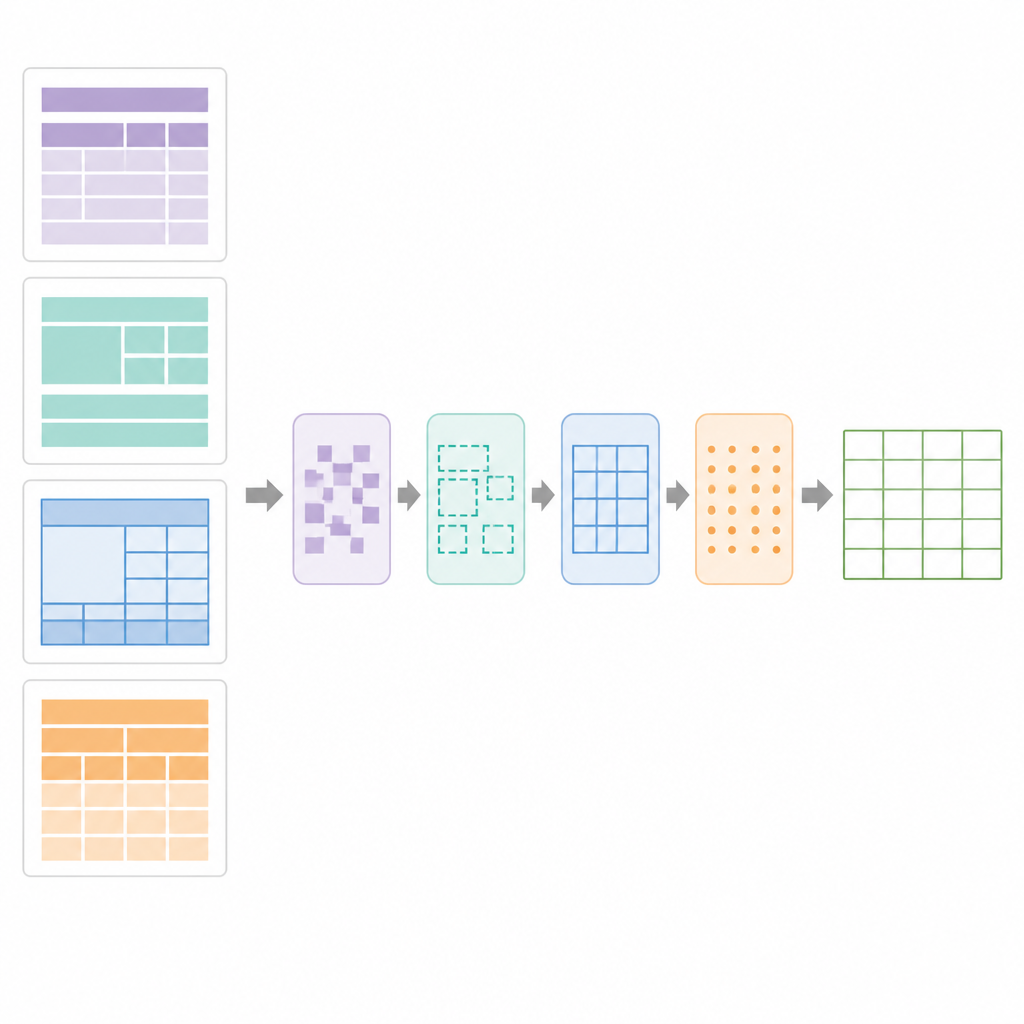
Como ele se sai no mundo real
Os autores testaram o SPARTAN em mais de vinte mil páginas provenientes de avisos eletrônicos de alteração de produto, periódicos científicos, certificados e folhas de dados, incluindo muitas tabelas complicadas sem bordas e com estruturas aninhadas. Em comparação com ferramentas populares como Tabula, TabbyPDF, Deepdoctection e EMbTTBF, o SPARTAN alcançou maior precisão, recall e pontuação F1 geral na detecção de tabelas, juntamente com melhor acurácia de caracteres após o OCR. Também foi mais rápido que a maioria dos sistemas baseados em deep learning e consumiu muito menos memória, completando uma página típica em alguns segundos em um laptop padrão. Os principais pontos fracos apareceram em digitalizações de qualidade muito baixa ou layouts altamente decorativos, onde o sistema prefere deixar de identificar tabelas duvidosas a inundar a saída com falsos positivos.
O que isso significa para usuários cotidianos
Para organizações pequenas e médias que não podem arcar com grandes infraestruturas de IA, o SPARTAN mostra que regras bem desenhadas e análise moderna de imagem ainda são ferramentas poderosas. Oferece uma forma transparente e ajustável de extrair tabelas de PDFs do dia a dia e transformá‑las em dados estruturados que planilhas, bancos de dados e ferramentas analíticas conseguem entender. Ao fazer isso, reduz a lacuna entre scripts simples e frágeis e redes neurais pesadas, tornando a extração de tabelas em larga escala e explicável mais acessível a quem trabalha com documentos complexos.
Citação: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Palavras-chave: tabelas em PDF, análise de documentos, extração de tabelas, OCR, OpenCV