Clear Sky Science · sv
SPARTAN: automatisk tabellidentifiering och extraktion från dokument med avancerade OpenCV-heuristiker och OCR-tekniker
Varför smarta tabeller spelar roll
Mycket av den information som driver dagens företag och forskning ligger i tabeller i PDF-filer, från produktändringsmeddelanden till vetenskapliga artiklar och intyg. Dessa tabeller ser prydliga ut för människans öga, men datorer har svårt att läsa dem automatiskt, särskilt när miljontals sidor behöver bearbetas. Denna artikel presenterar SPARTAN, ett öppen källkods-system utformat för att snabbt, pålitligt och utan dyr AI-hårdvara dra ut rena, användbara tabeller ur vardagliga PDF:er.
Problemet med dagens digitala pappersarbete
PDF är arbetshästen för rapporter, utskrifter och tekniska dokument eftersom de ser likadana ut på alla skärmar och skrivare. Den visuella pålitligheten har en dold kostnad: PDF-filer saknar ofta ledtrådar om innehållets struktur. Medan ren text går att extrahera ganska enkelt, är tabeller betydligt knepigare. De förekommer i olika layouter, med saknade ramar, sammanslagna celler och flernivåhuvuden, och kan till och med vara inbäddade som bilder. Tidigare regelbaserade verktyg som förlitade sig på enkla tecken som linjer och mellanrum var snabba men brast utanför enkla rutnätsmallar. Nyare djupinlärningsmetoder känner igen komplexa tabeller bättre, men kräver stora etiketterade datamängder, kraftfulla GPU:er och beter sig som svarta lådor, vilket gör dem kostsamma och svåra att lita på.
En annan väg för att läsa tabeller
SPARTAN (Structured Parsing and Relevant Table Analysis) tar en mittväg genom att använda omsorgsfullt utformade bildbehandlingsregler istället för tunga neurala nätverk. Skrivet i Python och byggt på OpenCV och optisk teckenigenkänning (OCR), körs det på vanliga CPU:er och kräver ingen träningsfas eller massiva datamängder. Systemet börjar med att konvertera varje PDF-sida till en standardiserad gråskalebild och förstärker kontrasten mellan text, tabeller och bakgrund. Ett valfritt kolumnupptäcktssteg delar sidor med flerkolumnslayouter, som vetenskapliga artiklar, så att senare steg inte förväxlar textkolumner med tabellkolumner. Denna noggranna förberedelse sätter upp resten av pipeline:en att arbeta på konsekventa, brusreducerade bilder.
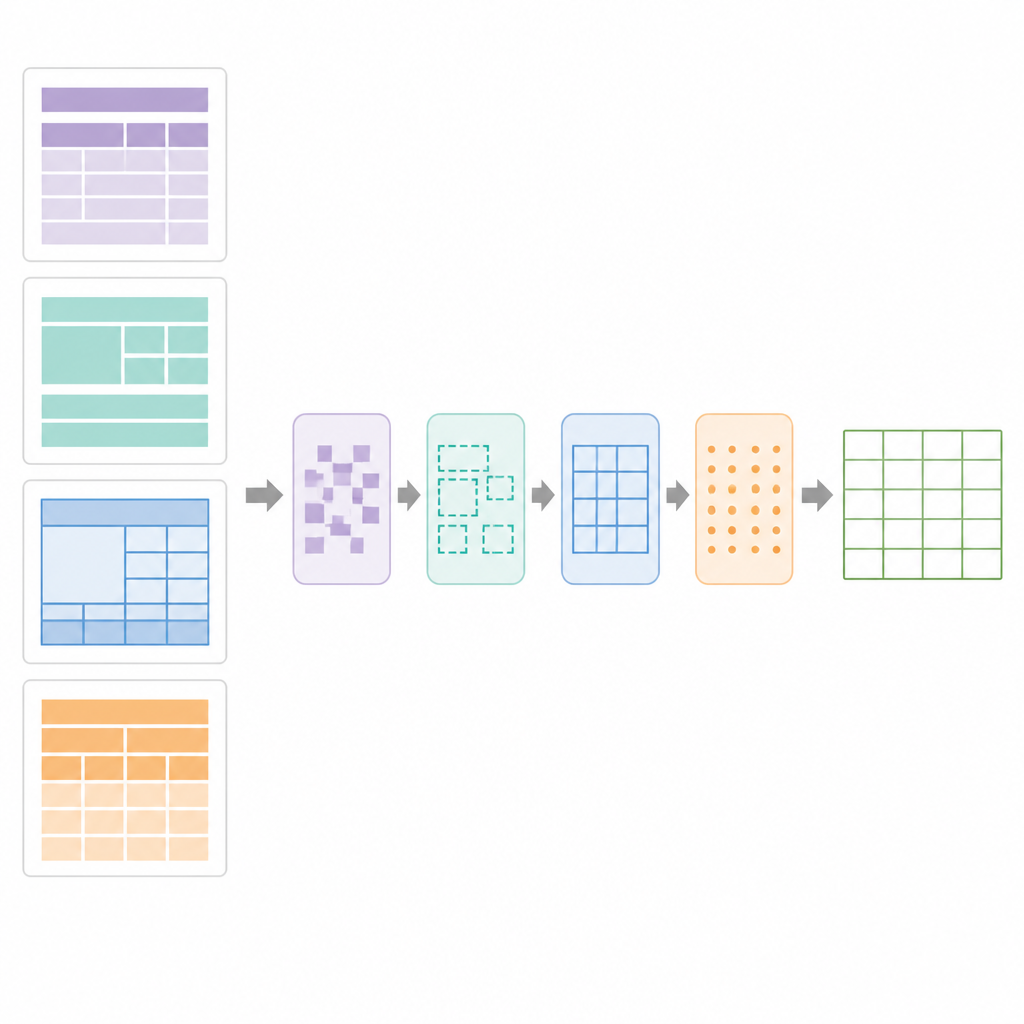
Hur SPARTAN hittar och bygger upp tabeller
I hjärtat av SPARTAN finns en regionssegmenteringsstrategi som delar varje sida i fyra zoner: texten före den första tabellen, texten mellan tabeller, texten efter den sista tabellen och själva tableområdena. För tabeller med synliga ramar detekterar systemet linjer, grupperar cellformade konturer och klustrar dem till kandidat-tabeller. För ramlösa tabeller tittar det på hur ord linjerar vertikalt och horisontellt, härleder kolumner och rader från justeringsmönster och ritar sedan ”pseudo”-gränser så att senare steg kan behandla dem som vanliga rutnät. Ett förfiningssteg använder exakt linjesegmentdetektion för att reparera brutna ramar, ta bort lösa linjer och bekräfta giltiga tabellrutnät. Därefter analyserar en data-kureringsmodul rutnätet för att hitta nyckel–värde-tabeller, normala rad- och kolumntabeller, inbäddade rubriker och sammanslagna celler. Den bygger sedan en digital ritning av tabellen och registrerar vilka celler som spänner över flera rader eller kolumner så att OCR kan tillämpas intelligent.
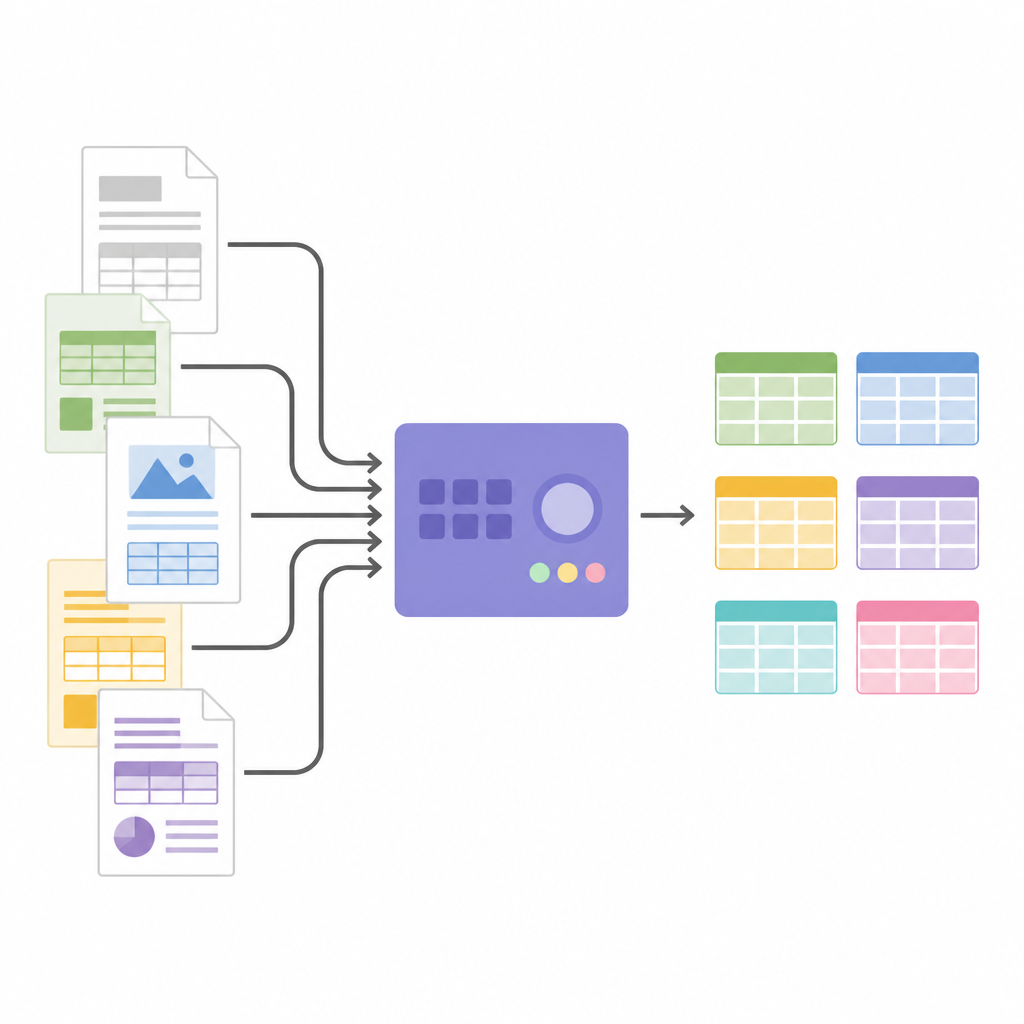
Från bilder till strukturerade data
När tabellstrukturen är känd beskär SPARTAN cellbilder och skickar dem till en OCR-motor. Den stöder två strategier: läsa varje cell en och en för maximal noggrannhet, eller läsa grupper av celler tillsammans för att snabba upp bearbetningen när tabeller är stora. Smarta knep, som att krympa varje utsnitt något och använda osynliga separatorbilder mellan celler, hjälper till att undvika vanliga OCR-misstag och hålla raderna i linje. Systemet kan slå samman relaterade tabeller över sidor och exporterar allt som JSON eller CSV, redo för analys eller inmatning i annan programvara. Eftersom arkitekturen är modulär kan användare byta OCR-motorer, finjustera tröskelvärden eller koppla in stora språkmodeller i slutet för att etikettera kolumner, bygga kunskapsgrafer eller extrahera specifika fakta utan att ändra den grundläggande tabellidentifieringslogiken.
Hur väl det fungerar i verkligheten
Författarna testade SPARTAN på mer än tjugotusen sidor hämtade från elektroniska produktändringsmeddelanden, vetenskapliga tidskrifter, intyg och datablad, inklusive många knepiga ramlösa och inbäddade tabeller. Jämfört med populära verktyg som Tabula, TabbyPDF, Deepdoctection och EMbTTBF uppnådde SPARTAN högre precision, återkallelse och totalt F1-värde för tabelldetektering, tillsammans med bättre teckenaccuracy efter OCR. Det kördes också snabbare än de flesta djupinlärningsbaserade system och använde mycket mindre minne, och behandlade en typisk sida på några sekunder på en standardlaptop. De huvudsakliga svagheterna visade sig vid mycket lågkvalitativa skanningar eller mycket dekorativa layouter, där systemet föredrar att missa tvivelaktiga tabeller snarare än att fylla ut resultatet med falska träffar.
Vad detta innebär för vardagsanvändare
För små och medelstora organisationer som inte har råd med stora AI-infrastrukturer visar SPARTAN att välutformade regler och modern bildanalys fortfarande är kraftfulla verktyg. Det erbjuder ett transparent och justerbart sätt att låsa upp tabeller från vardagliga PDF:er och förvandla dem till strukturerade data som kalkylblad, databaser och analystverktyg kan förstå. På så vis minskar det klyftan mellan enkla, spröda skript och tunga neurala nätverk och gör storskalig, förklarbar tabulärextraktion mer tillgänglig för alla som arbetar med komplexa dokument.
Citering: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Nyckelord: PDF-tabeller, dokumentanalys, tabulärextraktion, OCR, OpenCV