Clear Sky Science · nl
SPARTAN: geautomatiseerde detectie en extractie van tabellen uit documenten met geavanceerde OpenCV-heuristieken en OCR-technieken
Waarom slimme tabellen ertoe doen
Veel van de informatie die moderne bedrijven en onderzoek aandrijft, staat in tabellen in PDF-bestanden: van productwijzigingsmeldingen tot wetenschappelijke artikelen en certificaten. Voor mensen zien die tabellen er netjes uit, maar computers hebben moeite ze automatisch te lezen, zeker wanneer miljoenen pagina’s verwerkt moeten worden. Dit artikel presenteert SPARTAN, een open-source systeem dat snel, betrouwbaar en zonder dure AI-hardware schone, bruikbare tabellen uit alledaagse PDF’s trekt.
Het probleem met het huidige digitale papierwerk
PDF’s zijn het werkpaard voor rapporten, overzichten en technische documenten omdat ze er op elk scherm of elke printer hetzelfde uitzien. Die visuele betrouwbaarheid heeft een verborgen prijs: PDF’s missen meestal aanwijzingen over de structuur van hun inhoud. Terwijl platte tekst vrij eenvoudig te extraheren is, zijn tabellen veel moeilijker. Ze hebben uiteenlopende lay-outs, ontbrekende randen, samengevoegde cellen en meerlaagse koppen, en kunnen zelfs als afbeeldingen ingesloten zijn. Eerdere regelgebaseerde tools die op simpele signalen zoals lijnen en witruimte vertrouwden waren snel, maar faalden bij alles wat verder ging dan eenvoudige rasters. Nieuwere deep-learningbenaderingen herkennen complexere tabellen beter, maar vragen om grote gelabelde datasets, krachtige GPU’s en werken als zwarte dozen, waardoor ze duur en moeilijk te vertrouwen zijn.
Een andere weg naar het lezen van tabellen
SPARTAN (Structured Parsing and Relevant Table Analysis) kiest een middenweg door zorgvuldig ontworpen beeldverwerkingsregels te gebruiken in plaats van zware neurale netwerken. Het is geschreven in Python en gebouwd op OpenCV en optische tekenherkenning (OCR); het draait op gewone CPU’s en vereist geen trainingsstap of enorme datasets. Het systeem begint met het omzetten van elke PDF-pagina in een gestandaardiseerde grijswaardenafbeelding en het verscherpen van het contrast tussen tekst, tabellen en achtergrond. Een optionele kolomdetectiestap splitst pagina’s met meerkolomsindelingen, zoals wetenschappelijke artikelen, zodat latere stappen tekstkolommen niet verwarren met tabelkolommen. Deze zorgvuldige voorbereiding zet de rest van de pijplijn op consistente, ruisgereduceerde beelden.
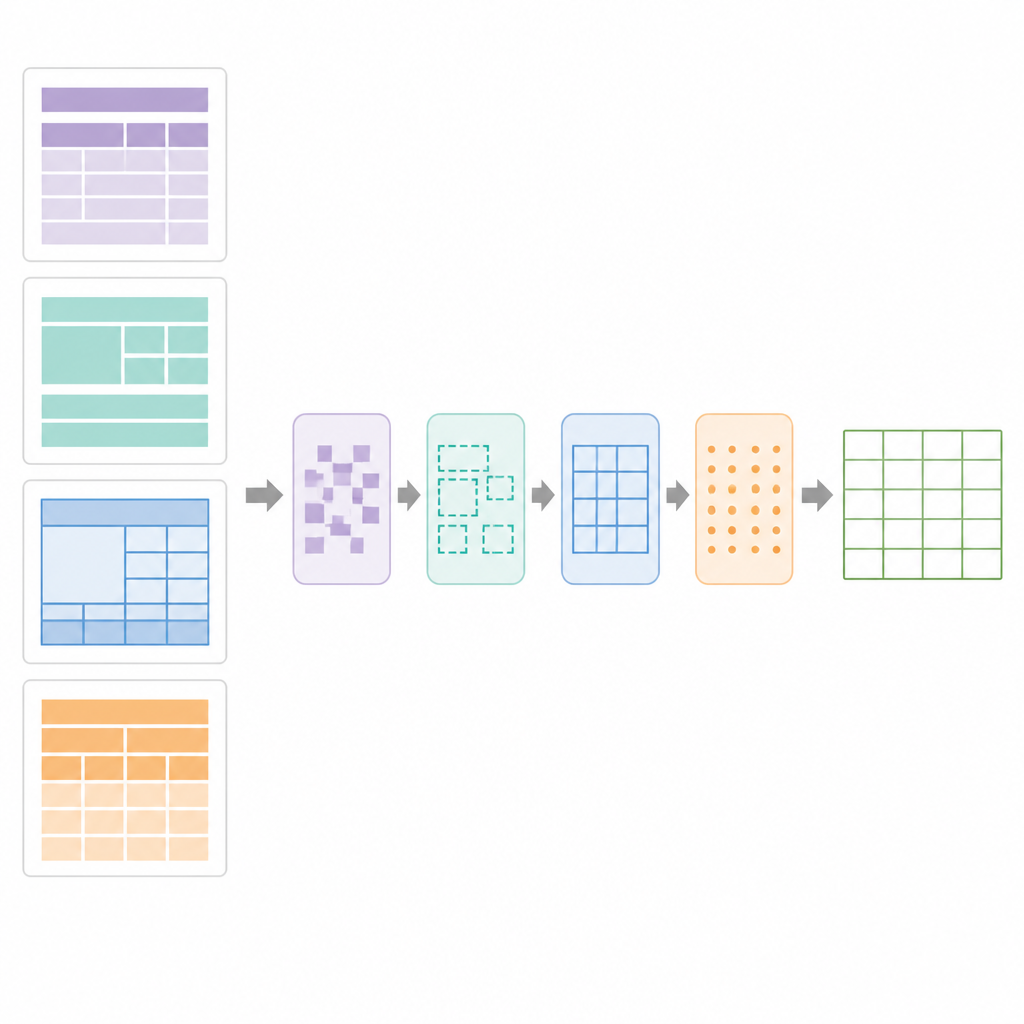
Hoe SPARTAN tabellen vindt en herbouwt
Centraal in SPARTAN staat een regiemechanisme dat elke pagina in vier zones verdeelt: de tekst voor de eerste tabel, de tekst tussen tabellen, de tekst na de laatste tabel en de tablegebieden zelf. Voor tabellen met zichtbare randen detecteert het systeem lijnen, groepeert celachtige contouren en clustert ze tot kandidaat-tabellen. Voor randloze tabellen kijkt het naar hoe woorden verticaal en horizontaal uitgelijnd zijn, inferreert kolommen en rijen uit uitlijningspatronen en tekent vervolgens “pseudo”-grenzen zodat latere stappen ze als normale rasters kunnen behandelen. Een verfijningsfase gebruikt precieze lijnsegmentdetectie om gebroken randen te herstellen, losgeslagen lijnen te verwijderen en geldige tabelrasters te bevestigen. Vervolgens analyseert een data-curatiemodule het raster om key–value-tabellen, normale rij-en-kolomtabellen, geneste koppen en samengevoegde cellen te herkennen. Daarna bouwt het een digitaal blauwdruk van de tabel, waarin wordt vastgelegd welke cellen meerdere rijen of kolommen overspannen zodat OCR intelligent kan worden toegepast.
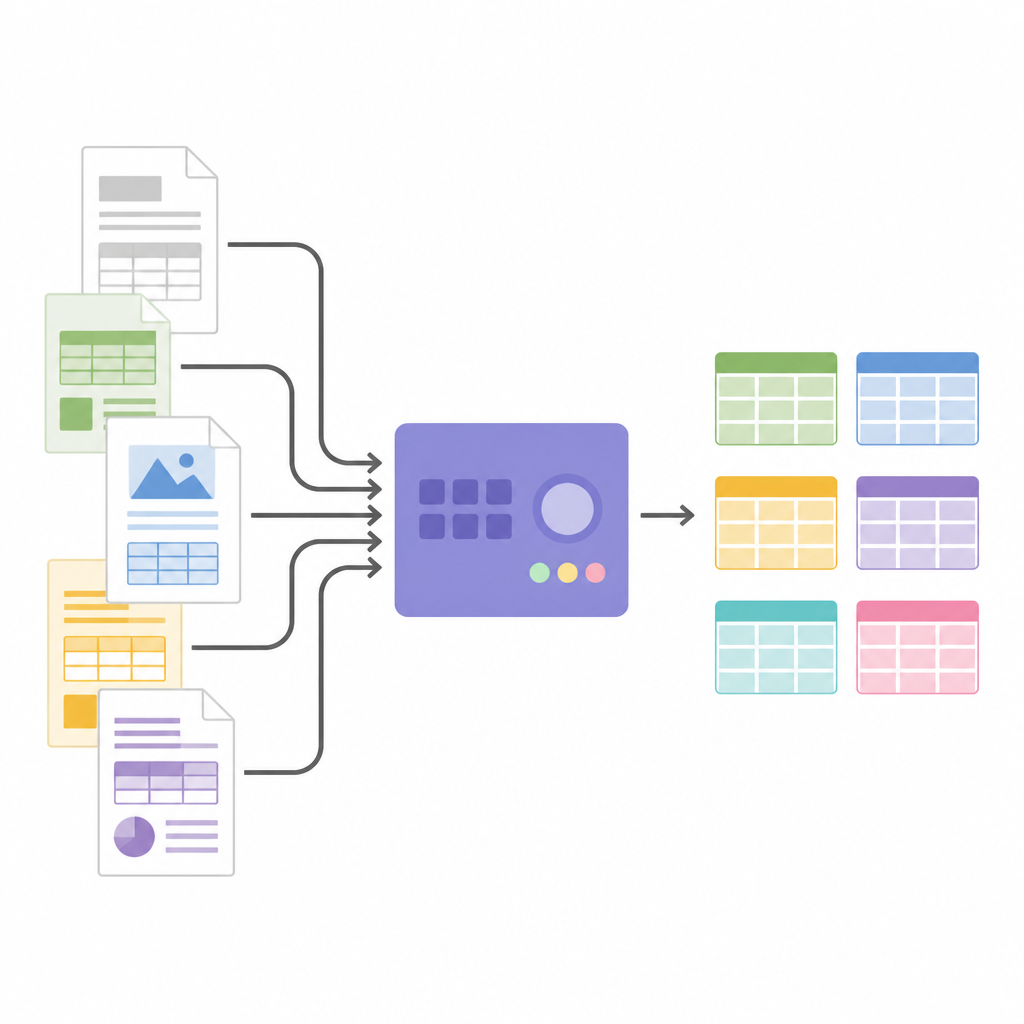
Afbeeldingen omzetten naar gestructureerde data
Zodra de tabelstructuur bekend is, knipt SPARTAN celafbeeldingen uit en stuurt die naar een OCR-engine. Het ondersteunt twee strategieën: elke cel afzonderlijk lezen voor maximale nauwkeurigheid, of groepen cellen tegelijk lezen om de verwerking te versnellen bij grote tabellen. Slimme trucs, zoals het iets verkleinen van elke uitsnede en het gebruiken van onzichtbare scheidingsafbeeldingen tussen cellen, helpen veelvoorkomende OCR-fouten te vermijden en rijen uitgelijnd te houden. Het systeem kan gerelateerde tabellen over pagina’s heen samenvoegen en exporteert alles als JSON of CSV, klaar voor analyse of voor gebruik in andere software. Omdat de architectuur modulair is, kunnen gebruikers OCR-engines wisselen, drempelwaarden tunen of groottaalmodellen aan het eind koppelen om kolommen te labelen, kennisgrafen te bouwen of specifieke feiten te extraheren zonder de kernlogica voor het vinden van tabellen te veranderen.
Hoe goed het in de praktijk werkt
De auteurs testten SPARTAN op meer dan twintigduizend pagina’s afkomstig van elektronische productwijzigingsmeldingen, wetenschappelijke tijdschriften, certificaten en datasheets, inclusief veel lastige randloze en geneste tabellen. Vergeleken met populaire tools zoals Tabula, TabbyPDF, Deepdoctection en EMbTTBF behaalde SPARTAN hogere precisie, recall en een hogere totale F1-score voor table-detectie, samen met betere karakternauwkeurigheid na OCR. Het draaide ook sneller dan de meeste op deep learning gebaseerde systemen en gebruikte veel minder geheugen, waarbij een typische pagina in enkele seconden op een standaard laptop werd verwerkt. De belangrijkste zwakke punten deden zich voor bij zeer slecht gescande documenten of sterk decoratieve lay-outs, waar het systeem er de voorkeur aan geeft twijfelachtige tabellen over te slaan in plaats van de uitvoer met valse positieven te vervuilen.
Wat dit betekent voor alledaagse gebruikers
Voor kleine en middelgrote organisaties die zich geen grote AI-infrastructuren kunnen veroorloven, laat SPARTAN zien dat goed ontworpen regels en moderne beeldanalyse nog steeds krachtige middelen zijn. Het biedt een transparante en afstelbare manier om tabellen uit alledaagse PDF’s te ontsluiten en om te zetten naar gestructureerde data die spreadsheet-, database- en analysetools kunnen begrijpen. Daarmee verkleint het de kloof tussen eenvoudige, breekbare scripts en zware neurale netwerken, en maakt het grootschalige, uitlegbare table-extractie toegankelijker voor iedereen die met complexe documenten werkt.
Bronvermelding: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Trefwoorden: PDF-tabellen, documentanalyse, table-extractie, OCR, OpenCV