Clear Sky Science · ar
SPARTAN: اكتشاف واستخراج الجداول تلقائياً من المستندات باستخدام قواعد OpenCV المتقدمة وتقنيات OCR
لماذا تهم الجداول الذكية
كثير من المعلومات التي تُشغّل الأعمال والبحث الحديث موجودة داخل الجداول في ملفات PDF، من إشعارات تغيّر المنتج إلى الأوراق العلمية والشهادات. تبدو هذه الجداول مرتبة للعين البشرية، لكن الحواسيب تجد صعوبة في قراءتها تلقائياً، خاصة عند الحاجة لمعالجة ملايين الصفحات. يقدّم هذا البحث SPARTAN، نظاماً مفتوح المصدر مصمَّماً لاستخراج جداول نظيفة وقابلة للاستخدام من ملفات PDF اليومية بسرعة وموثوقية وبدون الحاجة إلى أجهزة ذكاء اصطناعي باهظة الثمن.
مشكلة الأوراق الرقمية اليوم
تُعدّ ملفات PDF صيغة العمل الأساسية للتقارير والبيانات والمستندات الفنية لأنها تظهر نفسها بنفس الشكل على أي شاشة أو طابعة. لكن هذه الموثوقية البصرية تأتي بتكلفة خفية: غالباً ما تفتقر ملفات PDF إلى دلائل حول بنية المحتوى. بينما يمكن استخراج النص العادي بسهولة نسبية، تكون الجداول أكثر صعوبة. فهي تأتي بتخطيطات مختلفة، حدود مفقودة، خلايا مدمجة وعناوين متعددة المستويات، وقد تكون مضمنة كصور. الأدوات السابقة القائمة على قواعد بسيطة التي اعتمدت على دلائل مثل الخطوط والفواصل كانت سريعة لكنها تنهار أمام أي شيء أبعد من الشبكات البسيطة. الأساليب الجديدة المبنية على التعلم العميق تعرِف الجداول المعقدة أفضل، لكنها تتطلب مجموعات بيانات موسومة كبيرة، ووحدات معالجة رسومية قوية، وتتصرّف كصناديق سوداء، مما يجعلها مكلفة وصعبة الوثوق بها.
مسار مختلف لقراءة الجداول
يتخذ SPARTAN طريقاً وسطاً باستخدام قواعد معالجة صور مصمَّمة بعناية بدلاً من الشبكات العصبية الثقيلة. مكتوب بلغة بايثون وبُني على OpenCV والتعرّف الضوئي على الحروف (OCR)، يعمل على وحدات المعالجة المركزية العادية ولا يحتاج إلى خطوة تدريب أو مجموعات بيانات ضخمة. يبدأ النظام بتحويل كل صفحة PDF إلى صورة رمادية موحّدة وتوضيح التباين بين النص والجداول والخلفية. خطوة اختيارية لاكتشاف الأعمدة تفصل الصفحات ذات التخطيطات متعددة الأعمدة، مثل المقالات العلمية، بحيث لا تخلط المراحل اللاحقة بين أعمدة النص وأعمدة الجدول. هذه التحضيرات الدقيقة تهيئ بقية خط المعالجة للعمل على صور متسقة ومُقلّلة الضوضاء.
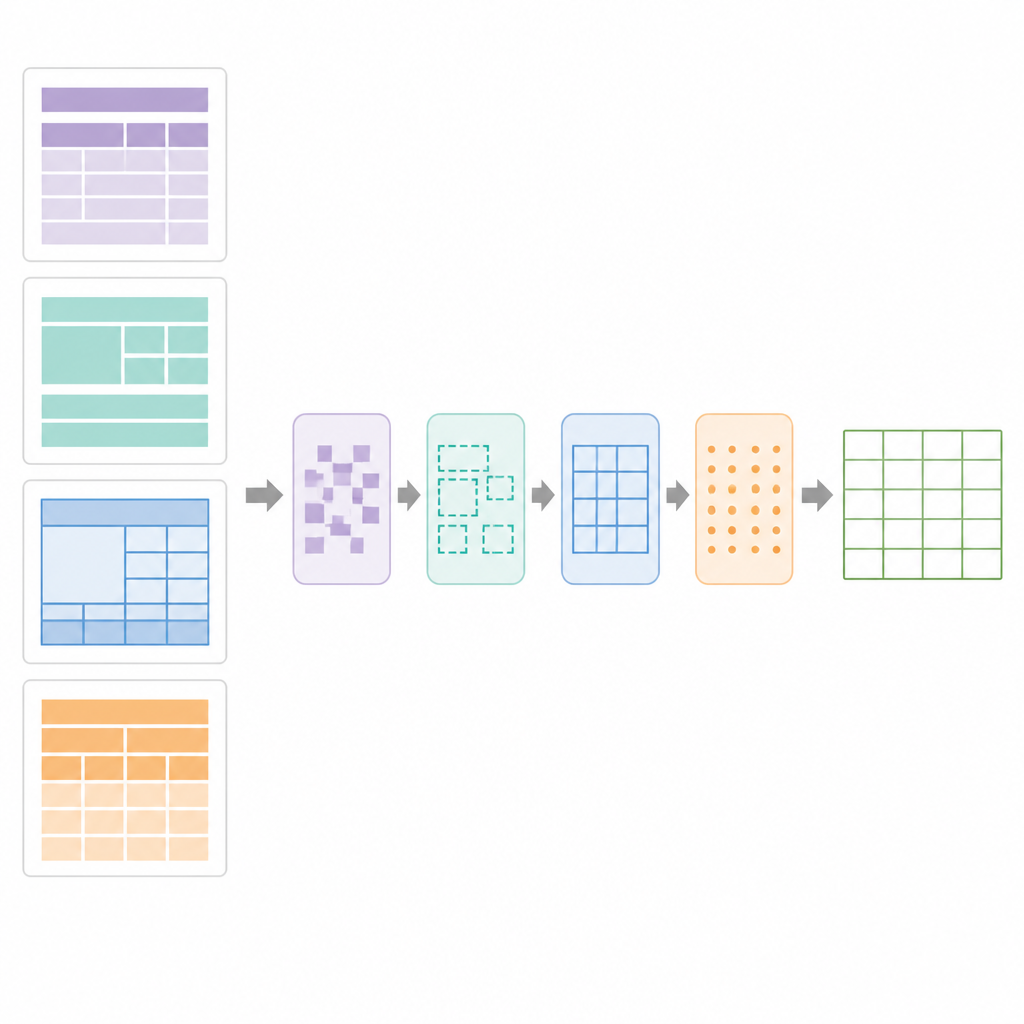
كيف يجد SPARTAN الجداول ويعيد بنائها
في صلب SPARTAN توجد استراتيجية تقسيم مناطق تقسم كل صفحة إلى أربع مناطق: النص قبل الجدول الأول، النص بين الجداول، النص بعد الجدول الأخير ومناطق الجداول نفسها. بالنسبة للجداول ذات الحدود الظاهرة، يكتشف النظام الخطوط، يجمع المُحَيطات على شكل خلايا ويُجمّعها في جداول مرشَّحة. بالنسبة للجداول بدون حدود، ينظر إلى كيفية اصطفاف الكلمات عمودياً وأفقياً، مستخلصاً الأعمدة والصفوف من أنماط الاصطفاف ثم يرسم حدوداً «شبهية» حتى تتمكن المراحل اللاحقة من معالجتها كشبكات عادية. مرحلة تنقيح تستخدم اكتشاف مقاطع الخط الدقيق لإصلاح الحدود المقطوعة، إزالة الخطوط العشوائية وتأكيد شبكات الجداول الصالحة. بعد ذلك، يحلل مُكوّن تنسيق البيانات الشبكة لاكتشاف جداول المفتاح–القيمة، الجداول العادية ذات الصفوف والأعمدة، رؤوس متداخلة وخلايا مدمجة. ثم يبني مخططاً رقمياً للجدول، مسجلاً الخلايا التي تمتد عبر صفوف أو أعمدة متعددة بحيث يمكن تطبيق OCR بذكاء.
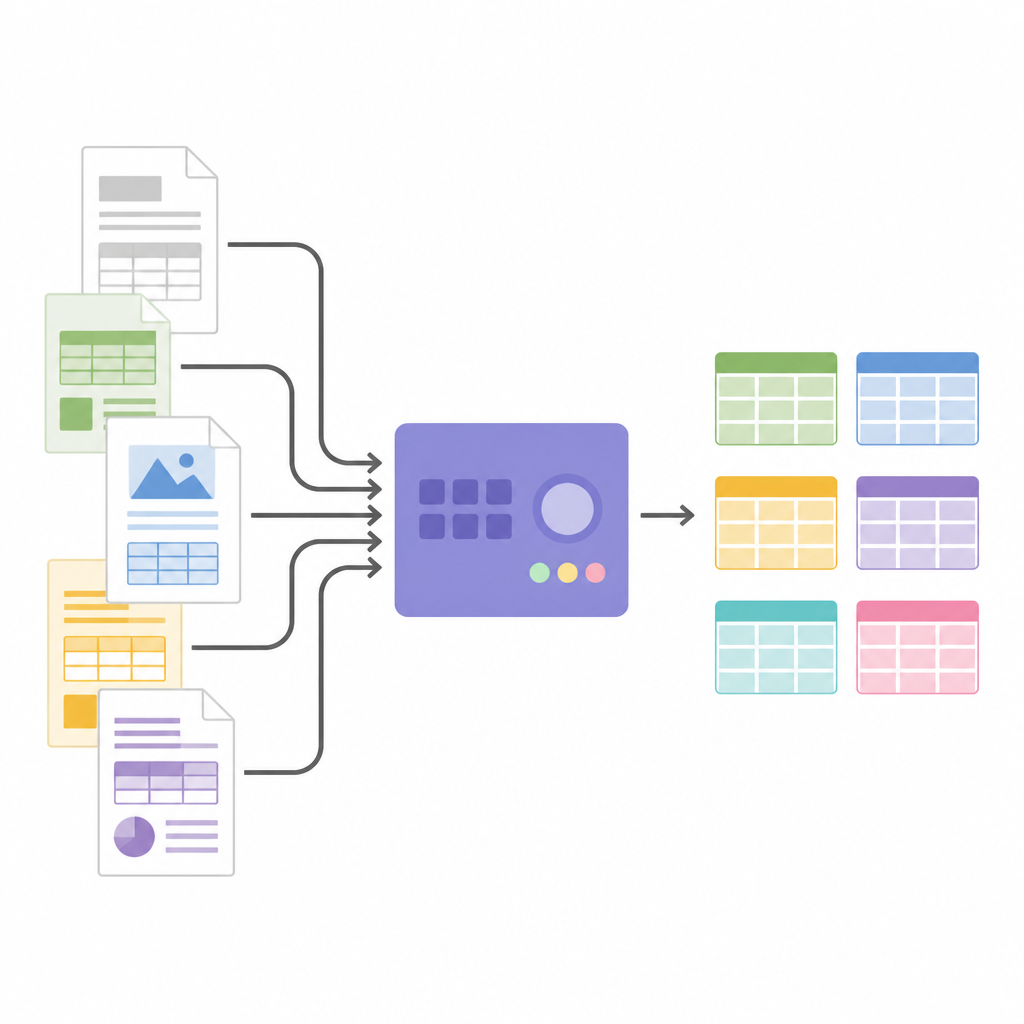
تحويل الصور إلى بيانات مُهيكلة
بمجرد معرفة بنية الجدول، يقوم SPARTAN بقص صور الخلايا وإرسالها إلى محرك OCR. يدعم استراتيجيتين: قراءة كل خلية على حدة لأقصى دقة، أو قراءة مجموعات من الخلايا معاً لتسريع المعالجة عندما تكون الجداول كبيرة. حيل ذكية، مثل تقليص كل قصّة قليلاً واستخدام صور فواصل غير مرئية بين الخلايا، تساعد على تجنّب أخطاء OCR الشائعة والحفاظ على محاذاة الصفوف. يستطيع النظام دمج الجداول ذات الصلة عبر الصفحات ويصدّر كل شيء بصيغتي JSON أو CSV، جاهز للتحليل أو للتغذية في برمجيات أخرى. وبما أن البنية المعمارية معيارية، يمكن للمستخدمين تبديل محركات OCR، ضبط العتبات، أو توصيل نماذج لغوية كبيرة في النهاية لتسمية الأعمدة، بناء مخططات معرفية أو استخراج حقائق محددة دون تغيير منطق اكتشاف الجداول الأساسي.
مدى فعاليته في العالم الحقيقي
اختبر المؤلفون SPARTAN على أكثر من عشرين ألف صفحة مأخوذة من إشعارات تغيّر المنتج الإلكترونية، المجلات العلمية، الشهادات وكتيبات البيانات، بما في ذلك العديد من الجداول الصعبة بلا حدود والمتداخلة. بالمقارنة مع أدوات شائعة مثل Tabula وTabbyPDF وDeepdoctection وEMbTTBF، حقّق SPARTAN دقّة واستدعاء ودرجة F1 إجمالية أعلى لاكتشاف الجداول، إلى جانب دقة أحرف أفضل بعد تطبيق OCR. كما عمل أسرع من معظم الأنظمة المبنية على التعلم العميق واستهلك ذاكرة أقل بكثير، مُنجزاً صفحة نموذجية خلال ثوانٍ على حاسوب محمول قياسي. ظهرت نقاط الضعف الرئيسية على المسح منخفض الجودة جداً أو التنسيقات الزخرفية للغاية، حيث يفضّل النظام تفويت الجداول المشكوك فيها بدلاً من إغراق المخرجات بنتائج زائفة.
ماذا يعني هذا للمستخدمين اليوميين
بالنسبة للمنظمات الصغيرة والمتوسطة التي لا تستطيع تحمل بناية تحتية ضخمة للذكاء الاصطناعي، يُظهِر SPARTAN أن القواعد المصممة جيداً وتحليل الصور الحديث لا يزالان أدوات قوية. فهو يوفّر طريقة شفافة وقابلة للضبط لفتح الجداول من ملفات PDF اليومية وتحويلها إلى بيانات مُهيكلة يمكن لجداول البيانات، قواعد البيانات وأدوات التحليل فهمها. وبهذا، يُقلّص الفجوة بين السكربتات البسيطة والهشة والشبكات العصبية الثقيلة، مما يجعل استخراج الجداول الشرح والقابل للتوسيع أكثر سهولة لأي شخص يعمل مع مستندات معقّدة.
الاستشهاد: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
الكلمات المفتاحية: جداول PDF, تحليل المستندات, استخراج الجداول, OCR, OpenCV