Clear Sky Science · fr
SPARTAN : détection et extraction automatisées de tableaux dans les documents à l’aide d’heuristiques OpenCV avancées et de techniques OCR
Pourquoi les tableaux intelligents comptent
Une grande partie des informations qui font fonctionner les entreprises et la recherche moderne se trouve dans des tableaux au sein de fichiers PDF, des notices de modification produit aux articles scientifiques en passant par les certificats. Ces tableaux paraissent ordonnés pour un lecteur humain, mais les ordinateurs peinent à les lire automatiquement, surtout lorsque des millions de pages doivent être traitées. Cet article présente SPARTAN, un système open source conçu pour extraire rapidement et de manière fiable des tableaux propres et exploitables à partir de PDF ordinaires, sans nécessiter de matériel d’intelligence artificielle coûteux.
Le problème des documents numériques d’aujourd’hui
Les PDF sont le format de référence pour les rapports, relevés et documents techniques car ils s’affichent de la même façon sur tout écran ou imprimante. Cette fiabilité visuelle a un coût caché : les PDF manquent généralement d’indices sur la structure de leur contenu. Si le texte brut peut être extrait assez facilement, les tableaux sont bien plus délicats. Ils présentent des mises en page variées, des bordures manquantes, des cellules fusionnées et des en-têtes à plusieurs niveaux, et peuvent même être intégrés sous forme d’images. Les outils basés sur des règles simples comme la détection de lignes et d’espaces étaient rapides mais échouaient dès qu’on sortait des grilles simples. Les approches récentes par apprentissage profond reconnaissent mieux des tableaux complexes, mais elles exigent de grands jeux de données annotés, des GPU puissants et demeurent des boîtes noires, ce qui les rend coûteuses et difficiles à appréhender.
Une autre voie pour lire les tableaux
SPARTAN (Structured Parsing and Relevant Table Analysis) emprunte une voie intermédiaire en s’appuyant sur des règles de traitement d’image soigneusement conçues plutôt que sur des réseaux neuronaux lourds. Écrit en Python et construit sur OpenCV et la reconnaissance optique de caractères (OCR), il fonctionne sur des CPU ordinaires et ne nécessite ni étape d’entraînement ni jeux de données massifs. Le système commence par convertir chaque page PDF en une image normalisée en niveaux de gris et renforce le contraste entre le texte, les tableaux et l’arrière-plan. Une étape optionnelle de détection de colonnes sépare les pages à mise en page multi-colonnes, comme les articles scientifiques, afin que les étapes ultérieures ne confondent pas colonnes de texte et colonnes de tableau. Cette préparation minutieuse prépare le reste du pipeline à travailler sur des images cohérentes et moins bruitées.
Comment SPARTAN trouve et reconstruit les tableaux
Au cœur de SPARTAN se trouve une stratégie de segmentation des régions qui divise chaque page en quatre zones : le texte avant le premier tableau, le texte entre les tableaux, le texte après le dernier tableau et les zones de tableaux elles‑mêmes. Pour les tableaux avec bordures visibles, le système détecte les lignes, regroupe les contours en forme de cellule et les clusterise en tableaux candidats. Pour les tableaux sans bordures, il examine l’alignement vertical et horizontal des mots, en déduisant colonnes et rangées à partir des motifs d’alignement, puis trace des délimitations « pseudo » pour que les étapes suivantes puissent les traiter comme des grilles normales. Une phase d’affinage utilise la détection précise de segments de ligne pour réparer les bordures cassées, supprimer les lignes parasites et confirmer les grilles de tableau valides. Ensuite, un module de curation des données analyse la grille pour repérer les tableaux clé–valeur, les tableaux classiques en lignes et colonnes, les en‑têtes imbriqués et les cellules fusionnées. Il construit alors un plan numérique du tableau, enregistrant quelles cellules s’étendent sur plusieurs lignes ou colonnes afin que l’OCR puisse être appliquée de manière intelligente.
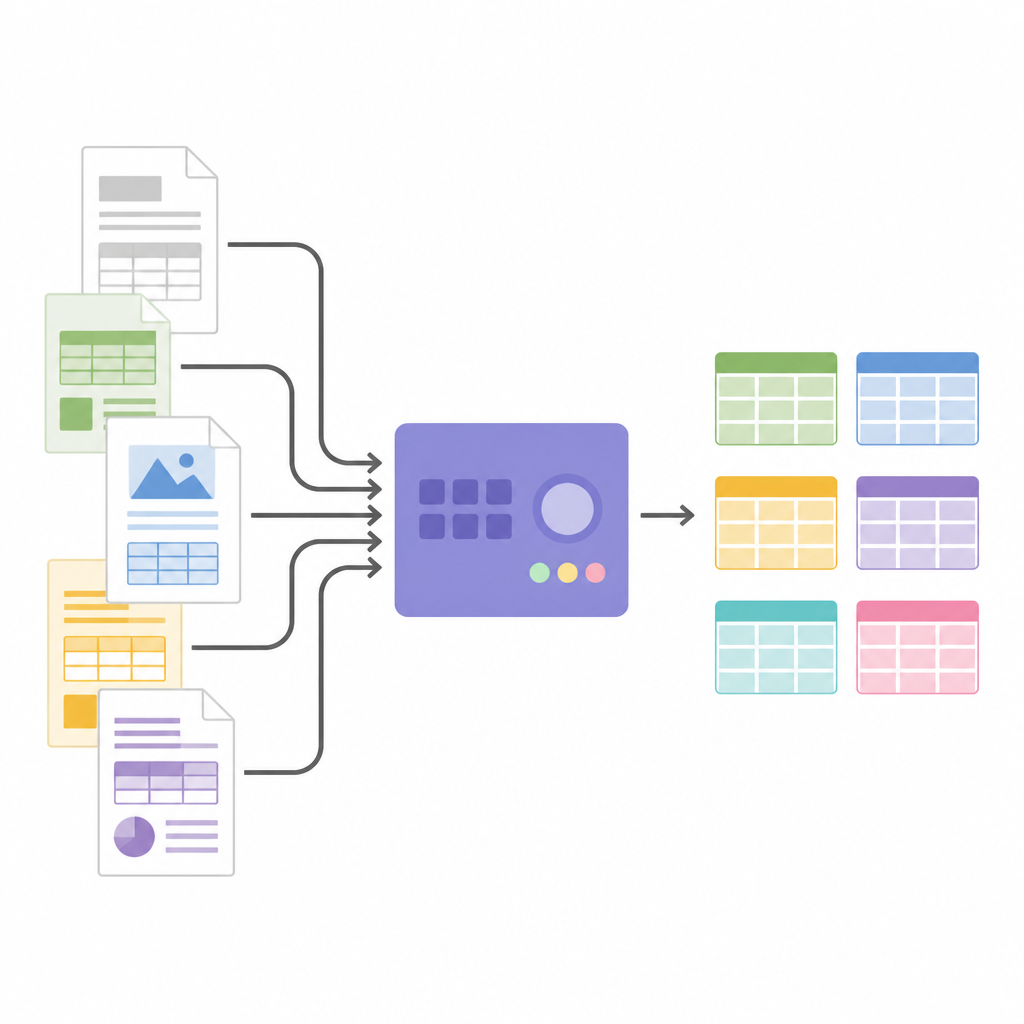
Transformer des images en données structurées
Une fois la structure du tableau connue, SPARTAN recadre les images de cellules et les envoie à un moteur OCR. Il prend en charge deux stratégies : lire chaque cellule une par une pour une précision maximale, ou lire des groupes de cellules ensemble pour accélérer le traitement lorsque les tableaux sont volumineux. Des astuces ingénieuses, comme réduire légèrement chaque recadrage et insérer des images séparatrices invisibles entre les cellules, aident à éviter les erreurs OCR courantes et à maintenir l’alignement des lignes. Le système peut fusionner des tableaux apparentés sur plusieurs pages et exporte le tout au format JSON ou CSV, prêt pour l’analyse ou pour alimenter d’autres logiciels. Parce que l’architecture est modulaire, les utilisateurs peuvent remplacer les moteurs OCR, ajuster les seuils ou brancher des modèles de langage à la fin pour étiqueter les colonnes, construire des graphes de connaissances ou extraire des faits précis sans modifier la logique centrale de détection de tableaux.
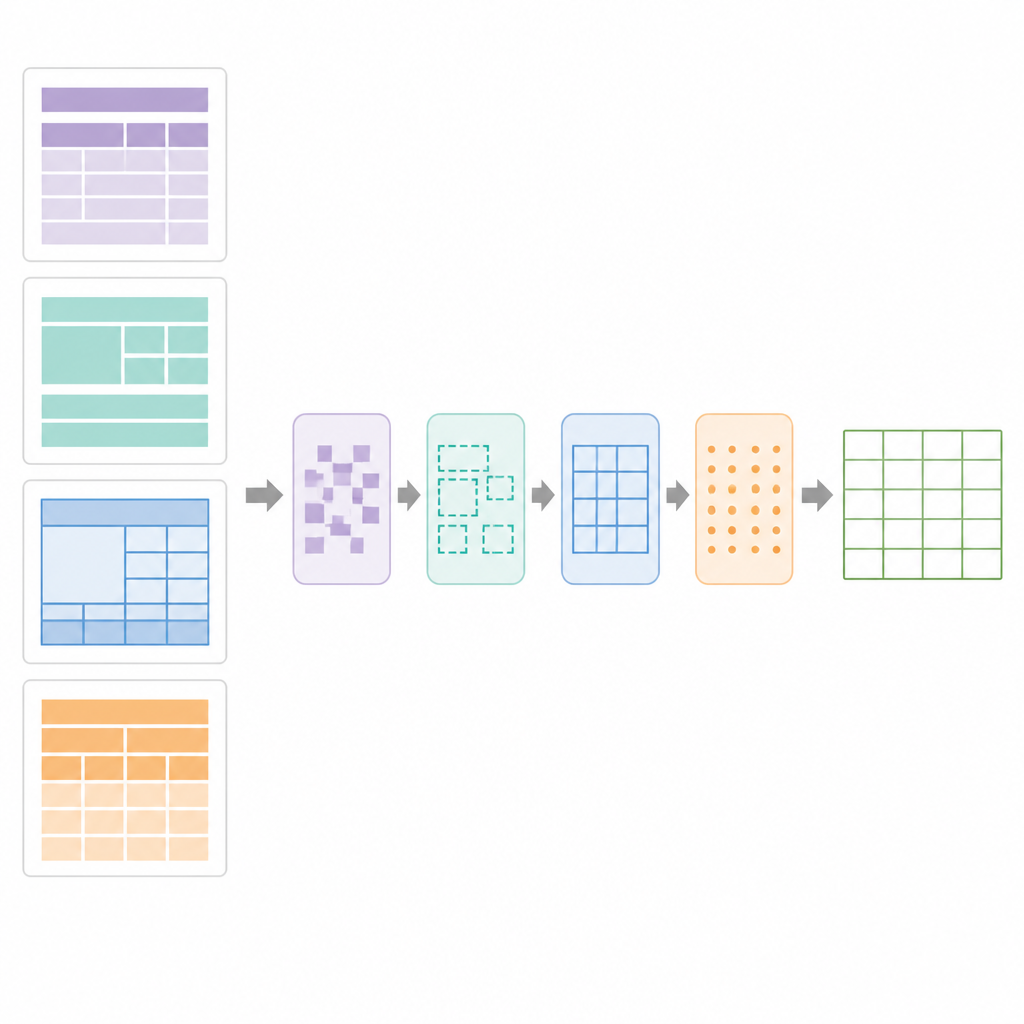
Quelle performance dans le monde réel
Les auteurs ont testé SPARTAN sur plus de vingt mille pages issues de notices de modification produit électroniques, revues scientifiques, certificats et fiches techniques, incluant de nombreux tableaux difficiles sans bordures ou imbriqués. Comparé à des outils populaires tels que Tabula, TabbyPDF, Deepdoctection et EMbTTBF, SPARTAN a obtenu une précision, un rappel et un score F1 globaux supérieurs pour la détection de tableaux, ainsi qu’une meilleure exactitude des caractères après OCR. Il s’est aussi avéré plus rapide que la plupart des systèmes basés sur l’apprentissage profond et a consommé beaucoup moins de mémoire, traitant une page typique en quelques secondes sur un ordinateur portable standard. Les principales limites apparaissent sur des scans de très faible qualité ou des mises en page très décoratives, où le système préfère manquer des tableaux douteux plutôt que d’inonder la sortie de faux positifs.
Ce que cela signifie pour les utilisateurs quotidiens
Pour les petites et moyennes organisations qui ne peuvent pas se permettre des infrastructures IA massives, SPARTAN montre que des règles bien conçues et l’analyse d’image moderne restent des outils puissants. Il offre une méthode transparente et paramétrable pour extraire des tableaux des PDF courants et les transformer en données structurées compréhensibles par des tableurs, bases de données et outils d’analytique. Ce faisant, il réduit l’écart entre des scripts simples et fragiles et des réseaux neuronaux lourds, rendant l’extraction de tableaux à grande échelle, explicable et plus accessible à quiconque travaille avec des documents complexes.
Citation: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Mots-clés: tableaux PDF, analyse de documents, extraction de tableaux, OCR, OpenCV