Clear Sky Science · pl
SPARTAN: zautomatyzowane wykrywanie i ekstrakcja tabel z dokumentów przy użyciu zaawansowanych heurystyk OpenCV i technik OCR
Dlaczego inteligentne tabele mają znaczenie
Wiele informacji napędzających współczesny biznes i badania znajduje się w tabelach w plikach PDF — od powiadomień o zmianach produktu po artykuły naukowe i świadectwa. Dla człowieka te tabele wyglądają schludnie, ale komputery mają problem z automatycznym odczytem, szczególnie gdy trzeba przetworzyć miliony stron. W artykule przedstawiono SPARTAN, system open-source zaprojektowany tak, by szybko i niezawodnie wydobywać z codziennych plików PDF czyste, użyteczne tabele bez potrzeby kosztownego sprzętu do sztucznej inteligencji.
Problem dzisiejszej dokumentacji cyfrowej
PDF-y są podstawowym formatem raportów, zestawień i dokumentów technicznych, ponieważ wyglądają tak samo na każdym ekranie czy drukarce. Ta wizualna spójność ma jednak ukrytą cenę: PDF-y zazwyczaj nie zawierają wskazówek co do struktury zawartości. Podczas gdy zwykły tekst da się dość łatwo wydobyć, tabele są znacznie trudniejsze. Występują w różnych układach, z brakującymi liniami, scalonymi komórkami i wielopoziomowymi nagłówkami, a czasem są osadzone jako obrazy. Wcześniejsze narzędzia oparte na prostych regułach, wykorzystujące linie i odstępy, były szybkie, ale zawodziły przy czymś innym niż proste siatki. Nowsze podejścia z głębokim uczeniem lepiej rozpoznają złożone tabele, lecz wymagają dużych zbiorów oznaczonych danych, wydajnych GPU i zachowują się jak czarne skrzynki, co czyni je kosztownymi i trudnymi do zaufania.
Inna droga do odczytu tabel
SPARTAN (Structured Parsing and Relevant Table Analysis) wybiera ścieżkę pośrednią, stosując starannie opracowane reguły przetwarzania obrazu zamiast ciężkich sieci neuronowych. Napisany w Pythonie i zbudowany na OpenCV oraz optycznym rozpoznawaniu znaków (OCR), działa na zwykłych procesorach i nie wymaga etapu treningu ani ogromnych zbiorów danych. System zaczyna od konwersji każdej strony PDF do ustandaryzowanego obrazu w odcieniach szarości i wyostrzenia kontrastu między tekstem, tabelami a tłem. Opcjonalny etap wykrywania kolumn dzieli strony z układami wielokolumnowymi, takimi jak artykuły naukowe, żeby późniejsze etapy nie myliły kolumn tekstu z kolumnami tabeli. Ta staranna obróbka przygotowuje dalsze elementy potoku do pracy na spójnych, zredukowanych szumem obrazach.
Jak SPARTAN znajduje i odtwarza tabele
W sercu SPARTAN leży strategia segmentacji obszarów, która dzieli każdą stronę na cztery strefy: tekst przed pierwszą tabelą, tekst między tabelami, tekst po ostatniej tabeli oraz same obszary tabel. Dla tabel z widocznymi obramowaniami system wykrywa linie, grupuje kontury mające kształt komórek i klastruje je do kandydatów na tabele. Dla tabel bez obramowań analizuje wyrównanie słów w pionie i poziomie, wyprowadzając kolumny i wiersze z wzorców wyrównania, a następnie rysuje „pseudo” granice, tak aby kolejne etapy mogły traktować je jak zwykłe siatki. Etap dopracowania wykorzystuje precyzyjne wykrywanie odcinków linii do naprawy przerwanych obramowań, usuwania zbędnych linii i potwierdzania prawidłowych siatek tabel. Następnie moduł kuracji danych analizuje siatkę, wykrywając tabele klucz–wartość, zwykłe tabele w układzie wierszy i kolumn, zagnieżdżone nagłówki oraz scalone komórki. Buduje cyfrowy plan tabeli, zapisując które komórki zajmują wiele wierszy lub kolumn, aby OCR mógł być zastosowany w sposób inteligentny.
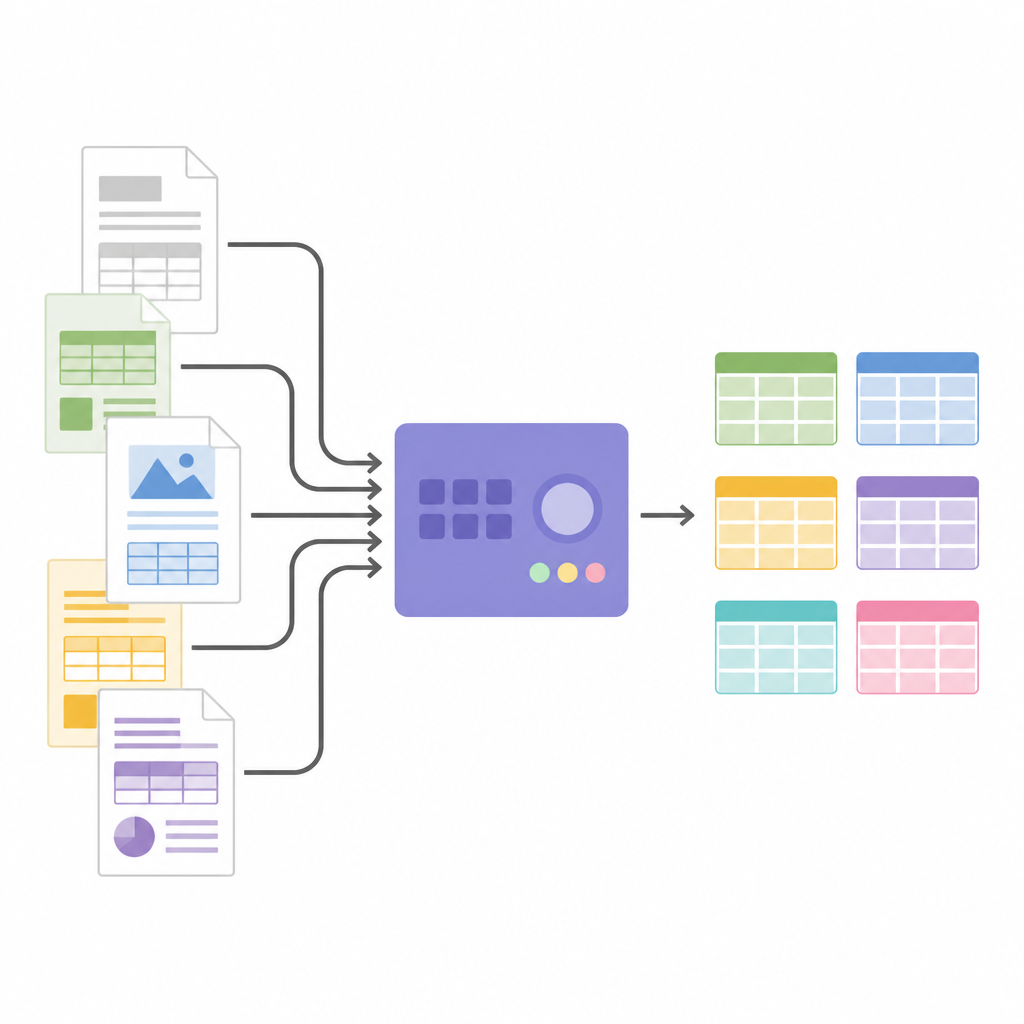
Przekształcanie obrazów w dane strukturalne
Gdy struktura tabeli jest znana, SPARTAN wycina obrazy komórek i przesyła je do silnika OCR. Wspiera dwie strategie: odczyt każdej komórki pojedynczo dla maksymalnej dokładności albo odczyt grup komórek razem, by przyspieszyć przetwarzanie przy dużych tabelach. Sprytne zabiegi, takie jak lekkie zmniejszanie każdego wycinka i używanie niewidocznych separatorów między komórkami, pomagają uniknąć typowych błędów OCR i utrzymać wyrównanie w wierszach. System potrafi łączyć powiązane tabele rozproszone na stronach i eksportować wszystko w formatach JSON lub CSV, gotowe do analiz lub dalszego przetwarzania. Dzięki modułowej architekturze użytkownicy mogą zamieniać silniki OCR, dostrajać progi lub podłączać duże modele językowe na końcu procesu, by etykietować kolumny, budować grafy wiedzy lub wydobywać konkretne fakty, bez zmiany podstawowej logiki wykrywania tabel.
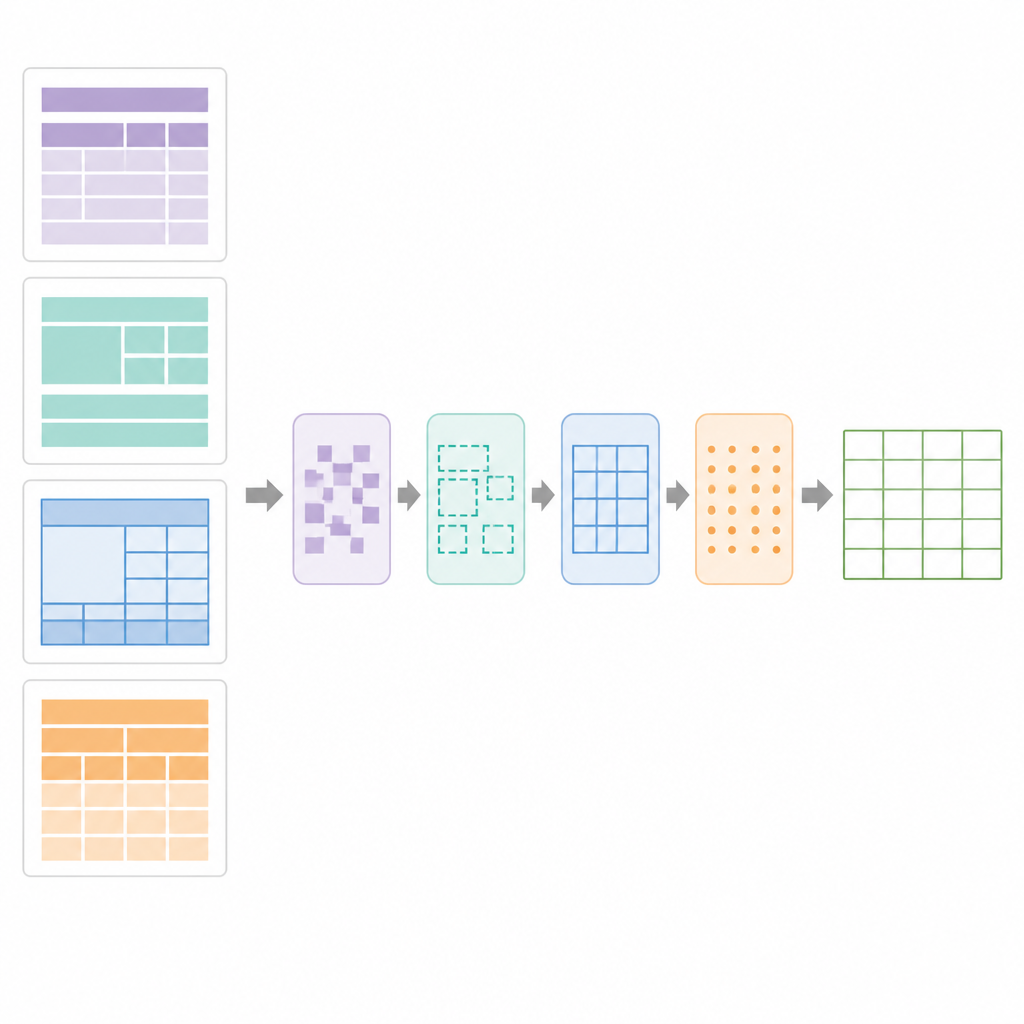
Jak to działa w praktyce
Autorzy przetestowali SPARTAN na ponad dwudziestu tysiącach stron pochodzących z elektronicznych powiadomień o zmianach produktów, czasopism naukowych, świadectw i kart katalogowych, w tym wielu trudnych tabel bez obramowań i tabel zagnieżdżonych. W porównaniu z popularnymi narzędziami takimi jak Tabula, TabbyPDF, Deepdoctection i EMbTTBF, SPARTAN osiągnął wyższą precyzję, czułość i łączny wynik F1 dla wykrywania tabel, a także lepszą dokładność znaków po OCR. Działał też szybciej niż większość systemów opartych na głębokim uczeniu i zużywał znacznie mniej pamięci, przetwarzając typową stronę w ciągu kilku sekund na standardowym laptopie. Główne słabe punkty pojawiały się przy bardzo niskiej jakości skanach lub silnie dekoracyjnych układach, gdzie system woli pominąć wątpliwe tabele, zamiast zalać wynik fałszywymi trafieniami.
Co to oznacza dla codziennych użytkowników
Dla małych i średnich organizacji, które nie mogą sobie pozwolić na duże infrastruktury AI, SPARTAN pokazuje, że dobrze zaprojektowane reguły i nowoczesna analiza obrazu wciąż są potężnymi narzędziami. Oferuje przejrzysty i konfigurowalny sposób odblokowywania tabel z codziennych PDF-ów i przekształcania ich w dane strukturalne, które arkusze kalkulacyjne, bazy danych i narzędzia analityczne potrafią rozumieć. W ten sposób zmniejsza przepaść między prostymi, kruchymi skryptami a ciężkimi sieciami neuronowymi, czyniąc masową, wyjaśnialną ekstrakcję tabel bardziej dostępną dla każdego, kto pracuje ze złożonymi dokumentami.
Cytowanie: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Słowa kluczowe: tabele PDF, analiza dokumentów, ekstrakcja tabel, OCR, OpenCV