Clear Sky Science · de
SPARTAN: automatisierte Tabellenerkennung und -extraktion aus Dokumenten mittels fortgeschrittener OpenCV-Heuristiken und OCR-Techniken
Warum intelligente Tabellen wichtig sind
Ein Großteil der Informationen, die moderne Unternehmen und Forschung steuern, liegt in Tabellen in PDF-Dateien vor – von Produktänderungsmitteilungen über wissenschaftliche Artikel bis hin zu Zertifikaten. Für Menschen wirken diese Tabellen ordentlich, aber Computer tun sich schwer, sie automatisch zu lesen, insbesondere wenn Millionen von Seiten verarbeitet werden müssen. Dieses Papier stellt SPARTAN vor, ein Open‑Source‑System, das darauf ausgelegt ist, schnell, zuverlässig und ohne teure KI‑Hardware saubere, nutzbare Tabellen aus Alltags‑PDFs zu extrahieren.
Das Problem mit heutiger digitaler Dokumentenverwaltung
PDFs sind das Arbeitspferd für Berichte, Abrechnungen und technische Dokumente, weil sie auf jedem Bildschirm oder Drucker gleich aussehen. Diese visuelle Zuverlässigkeit hat einen versteckten Preis: PDFs enthalten in der Regel keine klaren Hinweise auf die Struktur ihres Inhalts. Während reiner Text relativ leicht extrahiert werden kann, sind Tabellen weitaus schwieriger. Sie variieren in Layouts, fehlen manchmal Ränder, enthalten zusammengeführte Zellen und mehrstufige Kopfzeilen oder sind sogar als Bilder eingebettet. Frühere regelbasierte Werkzeuge, die sich auf einfache Hinweise wie Linien und Leerraum stützten, waren schnell, versagten aber bei allem über einfache Gitter hinaus. Neuere Deep‑Learning‑Ansätze erkennen komplexe Tabellen besser, erfordern jedoch große gelabelte Datensätze, leistungsstarke GPUs und verhalten sich wie Blackboxen, was sie teuer und schwer vertrauenswürdig macht.
Ein anderer Weg, Tabellen zu lesen
SPARTAN (Structured Parsing and Relevant Table Analysis) schlägt einen Mittelweg ein und verwendet sorgfältig gestaltete Bildverarbeitungsregeln statt schwerer neuronaler Netze. In Python geschrieben und auf OpenCV sowie optischer Zeichenerkennung (OCR) aufgebaut, läuft es auf normalen CPUs und benötigt keinen Trainingsschritt oder massive Datensätze. Das System beginnt damit, jede PDF‑Seite in ein standardisiertes Graustufenbild zu konvertieren und den Kontrast zwischen Text, Tabellen und Hintergrund zu schärfen. Ein optionaler Spaltenerkennungs‑Schritt teilt Seiten mit mehrspaltigem Layout, z. B. wissenschaftliche Artikel, sodass spätere Stufen Textspalten nicht mit Tabellenspalten verwechseln. Diese sorgfältige Vorbereitung schafft konsistente, rauschreduzierte Bilder für den weiteren Pipeline‑Ablauf.
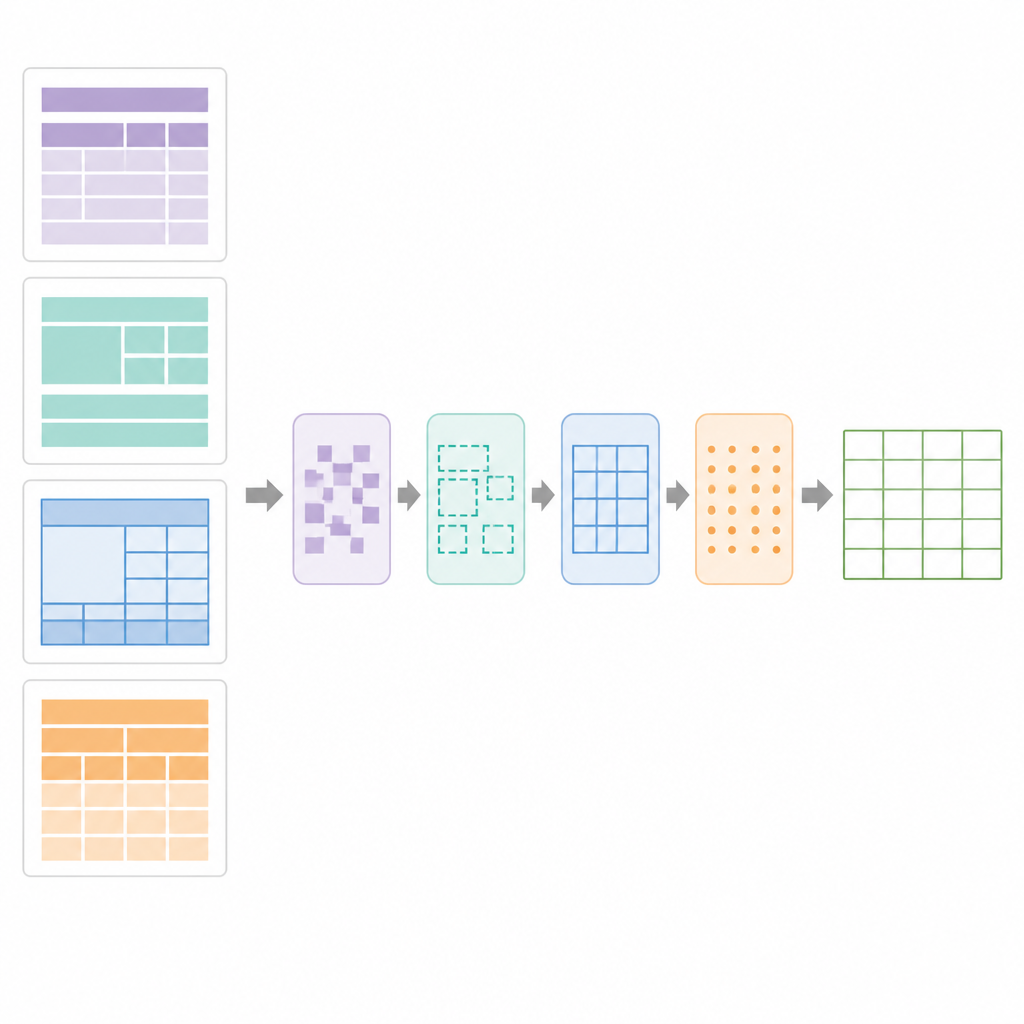
Wie SPARTAN Tabellen findet und wiederaufbaut
Im Kern nutzt SPARTAN eine Regionssegmentierungsstrategie, die jede Seite in vier Zonen aufteilt: den Text vor der ersten Tabelle, den Text zwischen Tabellen, den Text nach der letzten Tabelle und die eigentlichen Tabellenbereiche. Bei Tabellen mit sichtbaren Rahmen erkennt das System Linien, gruppiert zellenförmige Konturen und clustert sie zu Tabellenkandidaten. Bei rahmenlosen Tabellen analysiert es, wie Wörter vertikal und horizontal ausgerichtet sind, leitet daraus Spalten und Zeilen ab und zeichnet dann „Pseudo“-Grenzen, sodass spätere Schritte sie wie normale Gitter behandeln können. Eine Verfeinerungsstufe verwendet präzise Liniensegmenterkennung, um gebrochene Ränder zu reparieren, störende Linien zu entfernen und gültige Tabellenraster zu bestätigen. Anschließend analysiert ein Daten‑Kuratierungsmodul das Raster, um Schlüssel–Wert‑Tabellen, normale Zeilen‑und‑Spalten‑Tabellen, verschachtelte Kopfzeilen und zusammengeführte Zellen zu erkennen. Es erstellt dann einen digitalen Bauplan der Tabelle und dokumentiert, welche Zellen mehrere Zeilen oder Spalten überdecken, sodass OCR gezielt angewendet werden kann.
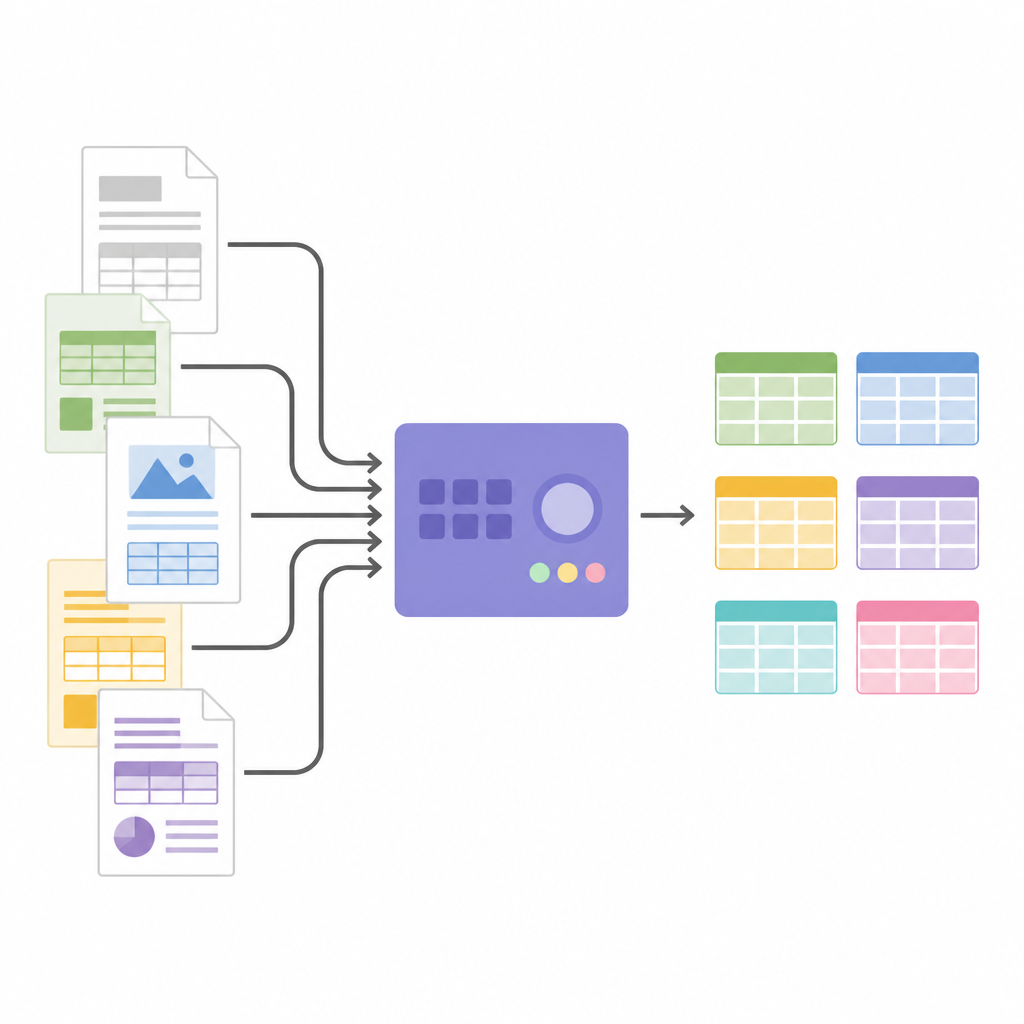
Bilder in strukturierte Daten verwandeln
Sobald die Tabellenstruktur bekannt ist, schneidet SPARTAN Zellbilder aus und übergibt sie an eine OCR‑Engine. Es unterstützt zwei Strategien: jede Zelle einzeln zu lesen für maximale Genauigkeit oder Zellen in Gruppen zu lesen, um die Verarbeitung bei großen Tabellen zu beschleunigen. Clevere Tricks, wie das leichte Verkleinern jeder Zuschneidung und das Verwenden unsichtbarer Trennbilder zwischen Zellen, helfen, häufige OCR‑Fehler zu vermeiden und die Ausrichtung der Zeilen zu erhalten. Das System kann verwandte Tabellen über Seiten hinweg zusammenführen und exportiert alles als JSON oder CSV, bereit für Analyse oder zur Weiterverarbeitung in anderer Software. Da die Architektur modular ist, können Nutzer OCR‑Engines austauschen, Schwellenwerte anpassen oder am Ende große Sprachmodelle einbinden, um Spalten zu beschriften, Wissensgraphen zu bauen oder spezifische Fakten zu extrahieren, ohne die Kernlogik der Tabellenerkennung zu ändern.
Wie gut es in der Praxis funktioniert
Die Autoren testeten SPARTAN auf mehr als zwanzigtausend Seiten aus elektronischen Produktänderungsmitteilungen, wissenschaftlichen Zeitschriften, Zertifikaten und Datenblättern, darunter viele knifflige rahmenlose und verschachtelte Tabellen. Im Vergleich mit beliebten Werkzeugen wie Tabula, TabbyPDF, Deepdoctection und EMbTTBF erreichte SPARTAN höhere Präzision, Recall und eine insgesamt bessere F1‑Score bei der Tabellenerkennung sowie bessere Zeichenaccuracy nach OCR. Es lief zudem schneller als die meisten tiefenlernenden Systeme und verbrauchte deutlich weniger Speicher, wobei eine typische Seite in wenigen Sekunden auf einem Standard‑Laptop verarbeitet wurde. Hauptschwächen traten bei sehr qualitativ schlechten Scans oder stark dekorativen Layouts auf, wo das System eher dazu neigt, zweifelhafte Tabellen zu übersehen, als die Ausgabe mit Fehlfunden zu überfluten.
Was das für den Alltag bedeutet
Für kleine und mittlere Organisationen, die sich keine große KI‑Infrastruktur leisten können, zeigt SPARTAN, dass gut entworfene Regeln und moderne Bildanalyse weiterhin leistungsfähige Werkzeuge sind. Es bietet eine transparente und anpassbare Möglichkeit, Tabellen aus Alltags‑PDFs freizulegen und in strukturierte Daten zu verwandeln, die Tabellenkalkulationen, Datenbanken und Analysetools verstehen. Damit schließt es die Lücke zwischen einfachen, brüchigen Skripten und schwergewichtigen neuronalen Netzen und macht großskalige, erklärbare Tabellenextraktion für alle zugänglicher, die mit komplexen Dokumenten arbeiten.
Zitation: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Schlüsselwörter: PDF-Tabellen, Dokumentenanalyse, Tabellenextraktion, OCR, OpenCV