Clear Sky Science · it
SPARTAN: rilevamento e estrazione automatica di tabelle da documenti usando euristiche OpenCV avanzate e tecniche OCR
Perché le tabelle intelligenti sono importanti
Gran parte delle informazioni che alimentano il business e la ricerca moderna risiede in tabelle dentro file PDF, dalle comunicazioni sui prodotti agli articoli scientifici e ai certificati. Queste tabelle appaiono ordinate all'occhio umano, ma i computer faticano a leggerle automaticamente, soprattutto quando occorre processare milioni di pagine. Questo articolo presenta SPARTAN, un sistema open-source pensato per estrarre tabelle pulite e utilizzabili da PDF quotidiani in modo rapido, affidabile e senza hardware costoso per l'intelligenza artificiale.
Il problema della documentazione digitale odierna
I PDF sono il formato di riferimento per report, rendiconti e documenti tecnici perché appaiono identici su qualsiasi schermo o stampante. Questa affidabilità visiva ha un costo nascosto: i PDF di solito non contengono indizi sulla struttura del loro contenuto. Mentre il testo semplice si può estrarre abbastanza facilmente, le tabelle sono molto più complicate. Presentano layout diversi, bordi mancanti, celle unite e intestazioni a più livelli, e talvolta sono incorporate come immagini. Strumenti basati su regole più semplici, che si affidavano a indizi come linee e spazi bianchi, erano veloci ma si rompevano di fronte a qualsiasi struttura più complessa di una griglia semplice. Approcci più recenti basati sul deep learning riconoscono tabelle complesse meglio, ma richiedono grandi dataset etichettati, GPU potenti e funzionano come scatole nere, rendendoli costosi e difficili da fidarsi.
Una strada diversa per leggere le tabelle
SPARTAN (Structured Parsing and Relevant Table Analysis) percorre una via intermedia utilizzando regole di elaborazione delle immagini accuratamente progettate invece di pesanti reti neurali. Scritto in Python e basato su OpenCV e riconoscimento ottico dei caratteri (OCR), funziona su CPU ordinarie e non necessita di una fase di addestramento o di dataset massivi. Il sistema inizia convertendo ogni pagina PDF in un'immagine in scala di grigi standardizzata e migliorando il contrasto tra testo, tabelle e sfondo. Un passaggio opzionale di rilevamento delle colonne divide le pagine con layout a più colonne, come negli articoli scientifici, in modo che le fasi successive non confondano le colonne di testo con le colonne di tabella. Questa preparazione accurata mette il resto della pipeline nelle condizioni di lavorare su immagini coerenti e con meno rumore.
Come SPARTAN individua e ricostruisce le tabelle
Al centro di SPARTAN c'è una strategia di segmentazione delle regioni che divide ogni pagina in quattro zone: il testo prima della prima tabella, il testo tra le tabelle, il testo dopo l'ultima tabella e le aree della tabella stessa. Per le tabelle con bordi visibili, il sistema rileva le linee, raggruppa i contorni a forma di cella e li clusterizza in tabelle candidate. Per le tabelle senza bordi, osserva come le parole si allineano verticalmente e orizzontalmente, deducendo colonne e righe dai pattern di allineamento e quindi disegnando confini “pseudo” in modo che le fasi successive possano trattarle come normali griglie. Una fase di raffinamento utilizza il rilevamento preciso di segmenti lineari per riparare bordi interrotti, rimuovere linee spurie e confermare griglie di tabella valide. Successivamente, un modulo di curazione dei dati analizza la griglia per individuare tabelle chiave–valore, tabelle normali righe-e-colonne, intestazioni annidate e celle unite. Costruisce quindi un progetto digitale della tabella, registrando quali celle si estendono su più righe o colonne in modo che l'OCR possa essere applicato in maniera intelligente.
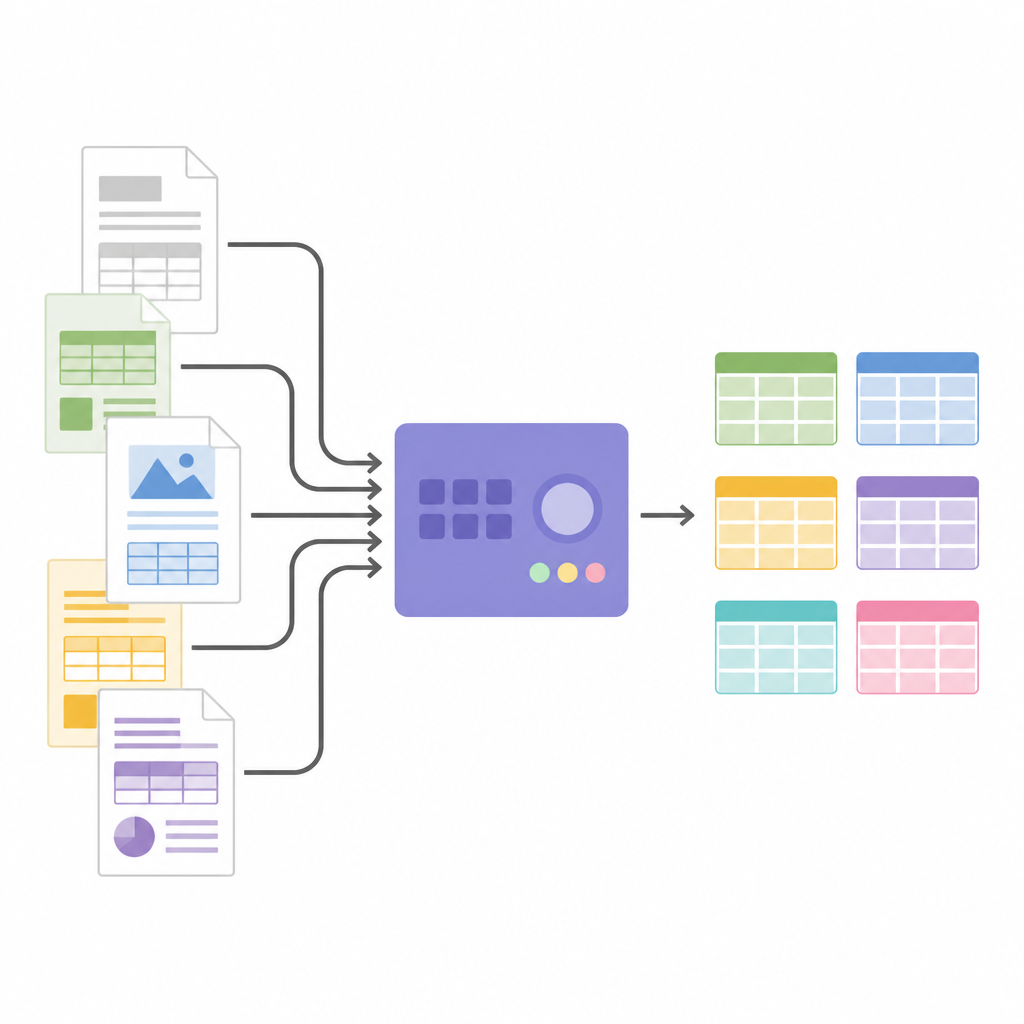
Trasformare immagini in dati strutturati
Una volta nota la struttura della tabella, SPARTAN ritaglia le immagini delle celle e le invia a un motore OCR. Supporta due strategie: leggere ogni cella una per una per la massima accuratezza, oppure leggere gruppi di celle insieme per accelerare l'elaborazione quando le tabelle sono grandi. Accorgimenti ingegnosi, come ridurre leggermente ogni ritaglio e inserire immagini separatrici invisibili tra le celle, aiutano a evitare errori comuni dell'OCR e mantenere l'allineamento delle righe. Il sistema può unire tabelle correlate su più pagine ed esporta tutto in JSON o CSV, pronto per l'analisi o per essere alimentato in altri software. Poiché l'architettura è modulare, gli utenti possono cambiare il motore OCR, tarare le soglie o collegare modelli di linguaggio di grandi dimensioni alla fine per etichettare colonne, costruire grafi di conoscenza o estrarre fatti specifici senza modificare la logica centrale di individuazione delle tabelle.
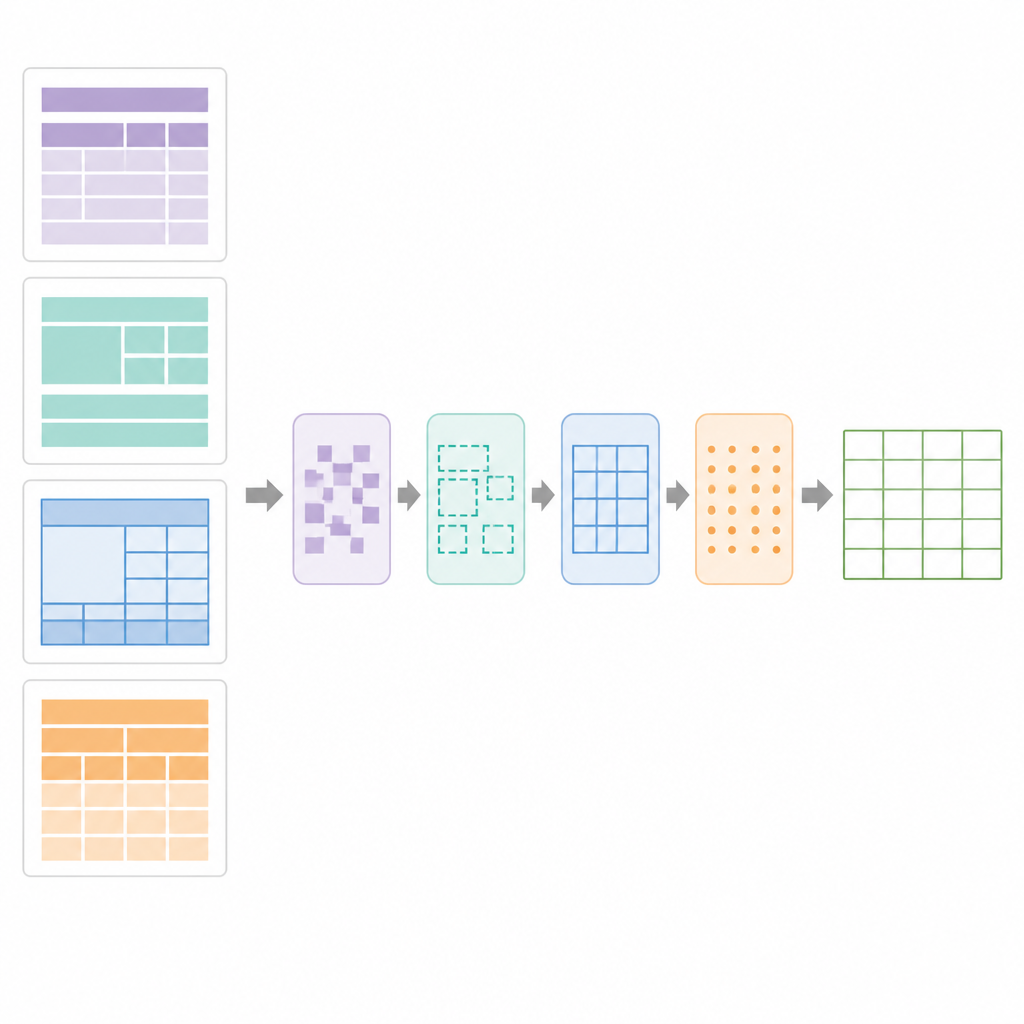
Quali risultati ottiene nel mondo reale
Gli autori hanno testato SPARTAN su più di ventimila pagine tratte da comunicazioni elettroniche di modifica dei prodotti, riviste scientifiche, certificati e schede tecniche, incluse molte tabelle borderline senza bordi e con intestazioni annidate. Rispetto a strumenti popolari come Tabula, TabbyPDF, Deepdoctection ed EMbTTBF, SPARTAN ha raggiunto maggiore precisione, richiamo e punteggio F1 complessivo per la rilevazione delle tabelle, insieme a una migliore accuratezza dei caratteri dopo l'OCR. Ha anche funzionato più velocemente della maggior parte dei sistemi basati sul deep learning e ha richiesto molta meno memoria, completando una pagina tipica in pochi secondi su un laptop standard. I principali punti deboli sono emersi su scansioni di qualità molto bassa o layout altamente decorativi, dove il sistema tende a non rilevare tabelle dubbie piuttosto che inondare l'output con falsi positivi.
Cosa significa per gli utenti di tutti i giorni
Per le piccole e medie organizzazioni che non possono permettersi grandi infrastrutture AI, SPARTAN dimostra che regole ben progettate e analisi delle immagini moderne sono ancora strumenti potenti. Offre un modo trasparente e regolabile per sbloccare tabelle da PDF quotidiani e trasformarle in dati strutturati che fogli di calcolo, database e strumenti di analisi possono comprendere. Così facendo, riduce il divario tra script semplici e fragili e reti neurali pesanti, rendendo l'estrazione di tabelle su larga scala e spiegabile più accessibile a chiunque lavori con documenti complessi.
Citazione: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Parole chiave: tabelle PDF, analisi dei documenti, estrazione di tabelle, OCR, OpenCV