Clear Sky Science · ru
SPARTAN: автоматическое обнаружение и извлечение таблиц из документов с использованием продвинутых эвристик OpenCV и методов OCR
Почему умные таблицы важны
Большая часть информации, которая управляет современной бизнес‑ и научной деятельностью, хранится в таблицах в PDF-файлах — от уведомлений об изменениях продуктов до научных статей и сертификатов. Для человека такие таблицы выглядят аккуратно, но компьютерам автоматически их распознать сложно, особенно если нужно обработать миллионы страниц. В этой статье представлен SPARTAN — система с открытым исходным кодом, предназначенная для быстрого, надежного извлечения чистых и пригодных к использованию таблиц из обычных PDF без затрат на дорогое аппаратное обеспечение для ИИ.
Проблема современного цифрового документооборота
PDF — рабочая лошадка для отчетов, ведомостей и технической документации, поскольку файлы выглядят одинаково на любом экране или принтере. Такая визуальная предсказуемость скрывает проблему: PDF часто не содержат явной информации о структуре содержимого. В то время как простой текст можно извлечь относительно легко, с таблицами гораздо сложнее. Они имеют разные макеты, отсутствующие границы, объединенные ячейки и многоуровневые заголовки, а иногда и встраиваются как изображения. Ранние инструментальные решения, опирающиеся на простые признаки вроде линий и пробелов, работали быстро, но терпели неудачу при чем‑то большем, чем простые сетки. Новые подходы на основе глубокого обучения лучше распознают сложные таблицы, но требуют больших размеченных наборов данных, мощных GPU и ведут себя как «черные ящики», что делает их дорогими и трудными для доверия.
Другой путь к чтению таблиц
SPARTAN (Structured Parsing and Relevant Table Analysis) идет по среднему пути, используя тщательно разработанные правила обработки изображений вместо тяжеловесных нейросетей. Написанная на Python и построенная на OpenCV и оптическом распознавании текста (OCR), она работает на обычных CPU и не требует этапа обучения или массивных наборов данных. Система начинает с преобразования каждой страницы PDF в стандартизированное изображение в градациях серого и повышения контрастности между текстом, таблицами и фоном. Опциональный этап обнаружения колонок разделяет страницы с многоколоночной версткой, например в научных статьях, чтобы последующие этапы не путали текстовые колонки с колонками таблиц. Такая тщательная подготовка задает основу для работы остального конвейера на согласованных, с уменьшенным шумом изображениях.
Как SPARTAN находит и восстанавливает таблицы
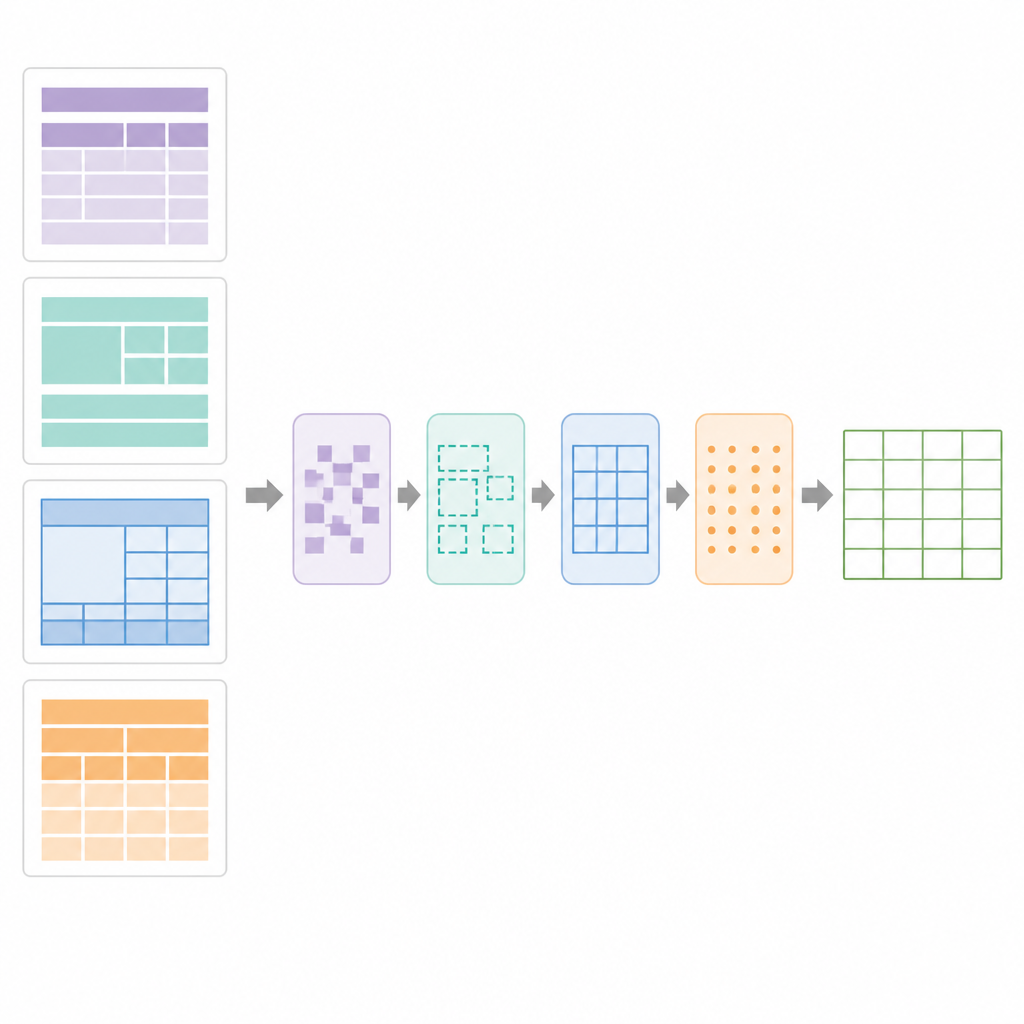
В основе SPARTAN лежит стратегия сегментации областей, которая делит каждую страницу на четыре зоны: текст до первой таблицы, текст между таблицами, текст после последней таблицы и сами области таблиц. Для таблиц с видимыми границами система обнаруживает линии, группирует контуры, похожие на ячейки, и объединяет их в кандидаты на таблицы. Для таблиц без границ она анализирует выравнивание слов по вертикали и горизонтали, выводя колонки и строки по паттернам выравнивания, а затем проводит «псевдо»границы, чтобы последующие этапы могли обрабатывать их как обычные сетки. Этап уточнения использует точное детектирование отрезков, чтобы восстановить разорванные границы, удалить посторонние линии и подтвердить корректные таблицы. Затем модуль курирования данных анализирует сетку, выявляя таблицы ключ–значение, обычные строчно‑столбцовые таблицы, вложенные заголовки и объединенные ячейки. Он строит цифровой чертеж таблицы, фиксируя, какие ячейки охватывают несколько строк или столбцов, чтобы OCR применялся интеллектуально.
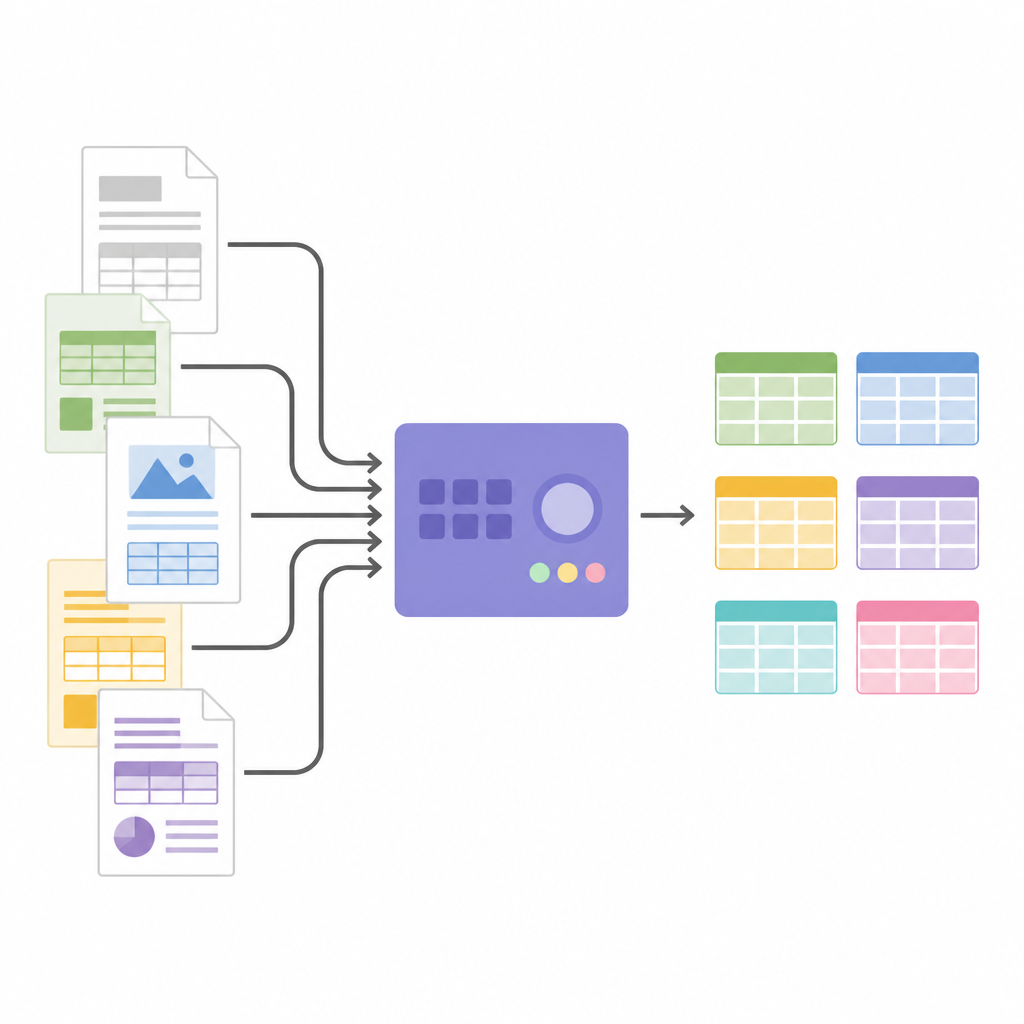
Преобразование изображений в структурированные данные
Когда структура таблицы известна, SPARTAN вырезает изображения ячеек и отправляет их в OCR‑движок. Поддерживаются две стратегии: чтение каждой ячейки по очереди для максимальной точности или группирование ячеек для ускорения обработки крупных таблиц. Хитрые приемы, такие как небольшое уменьшение каждой вырезки и использование невидимых разделительных изображений между ячейками, помогают избежать типичных ошибок OCR и сохраняют выравнивание строк. Система может объединять связанные таблицы по страницам и экспортировать результаты в JSON или CSV, готовые для анализа или передачи в другое ПО. Благодаря модульной архитектуре пользователи могут менять OCR‑движки, настраивать пороги или подключать большие языковые модели на финальном этапе для маркировки столбцов, построения графов знаний или извлечения конкретных фактов без изменения основной логики поиска таблиц.
Как это работает в реальном мире
Авторы протестировали SPARTAN на более чем двадцати тысячах страниц из уведомлений об изменениях электронной продукции, научных журналов, сертификатов и технических паспортов, включая множество сложных таблиц без границ и с вложенной структурой. В сравнении с популярными инструментами, такими как Tabula, TabbyPDF, Deepdoctection и EMbTTBF, SPARTAN показал более высокую точность, полноту и общий F1‑балл для обнаружения таблиц, а также лучшую точность распознавания символов после OCR. Она также работала быстрее, чем большинство систем на основе глубокого обучения, и использовала значительно меньше памяти, обрабатывая типичную страницу за несколько секунд на стандартном ноутбуке. Основные слабые места проявлялись на очень низкокачественных сканах или при чрезмерно декоративной верстке, где система предпочитает пропускать сомнительные таблицы, а не засорять вывод ложными срабатываниями.
Что это значит для повседневных пользователей
Для малых и средних организаций, которые не могут позволить себе крупные ИИ‑инфраструктуры, SPARTAN демонстрирует, что продуманная набор правил и современные методы анализа изображений по‑прежнему являются мощными инструментами. Она предлагает прозрачный и настраиваемый способ извлечения таблиц из повседневных PDF и превращения их в структурированные данные, понятные таблицам, базам данных и средствам аналитики. Тем самым система сокращает разрыв между простыми, хрупкими скриптами и тяжеловесными нейросетями, делая массовое объяснимое извлечение таблиц более доступным для всех, кто работает со сложными документами.
Цитирование: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Ключевые слова: PDF-таблицы, анализ документов, извлечение таблиц, OCR, OpenCV