Clear Sky Science · es
SPARTAN: detección y extracción automatizada de tablas en documentos usando heurísticas avanzadas de OpenCV y técnicas OCR
Por qué importan las tablas inteligentes
Gran parte de la información que mueve los negocios y la investigación moderna reside en tablas dentro de archivos PDF, desde avisos de cambio de producto hasta artículos científicos y certificados. Estas tablas parecen ordenadas para el ojo humano, pero los ordenadores tienen dificultades para leerlas automáticamente, sobre todo cuando hay que procesar millones de páginas. Este artículo presenta SPARTAN, un sistema de código abierto diseñado para extraer tablas limpias y útiles de PDFs cotidianos de forma rápida, fiable y sin necesidad de costoso hardware de inteligencia artificial.
El problema del papeleo digital actual
Los PDF son el formato de referencia para informes, extractos y documentos técnicos porque se ven igual en cualquier pantalla o impresora. Esa fiabilidad visual tiene un coste oculto: los PDFs suelen carecer de pistas sobre la estructura de su contenido. Mientras que el texto plano puede extraerse con cierta facilidad, las tablas son mucho más complicadas. Aparecen con distintos diseños, bordes ausentes, celdas fusionadas y encabezados multinivel, e incluso pueden estar incrustadas como imágenes. Herramientas basadas en reglas anteriores, que se apoyaban en pistas simples como líneas y espacios en blanco, eran rápidas pero fallaban ante algo más allá de rejillas simples. Enfoques recientes de aprendizaje profundo reconocen tablas complejas mejor, pero requieren grandes conjuntos de datos etiquetados, GPUs potentes y funcionan como cajas negras, lo que los hace costosos y difíciles de confiar.
Un camino distinto para leer tablas
SPARTAN (Structured Parsing and Relevant Table Analysis) toma un camino intermedio usando reglas de procesamiento de imagen cuidadosamente diseñadas en lugar de pesadas redes neuronales. Escrito en Python y construido sobre OpenCV y reconocimiento óptico de caracteres (OCR), funciona en CPUs ordinarias y no necesita una fase de entrenamiento ni conjuntos de datos masivos. El sistema comienza convirtiendo cada página PDF en una imagen en escala de grises estandarizada y acentuando el contraste entre texto, tablas y fondo. Un paso opcional de detección de columnas divide páginas con diseños de varias columnas, como artículos científicos, para que las etapas posteriores no confundan columnas de texto con columnas de tabla. Esta preparación cuidadosa permite que el resto del flujo de trabajo opere sobre imágenes consistentes y con menos ruido.
Cómo SPARTAN encuentra y reconstruye tablas
En el núcleo de SPARTAN está una estrategia de segmentación de regiones que divide cada página en cuatro zonas: el texto antes de la primera tabla, el texto entre tablas, el texto después de la última tabla y las áreas de tabla en sí. Para tablas con bordes visibles, el sistema detecta líneas, agrupa contornos con forma de celda y los clústeriza en tablas candidatas. Para tablas sin bordes, observa cómo las palabras se alinean vertical y horizontalmente, infiriendo columnas y filas a partir de patrones de alineación y luego dibujando límites “pseudo” para que las etapas posteriores las traten como rejillas normales. Una fase de refinamiento utiliza detección precisa de segmentos de línea para reparar bordes rotos, eliminar líneas errantes y confirmar rejillas de tabla válidas. A continuación, un módulo de curación de datos analiza la rejilla para detectar tablas clave–valor, tablas normales de filas y columnas, encabezados anidados y celdas fusionadas. Luego construye un plano digital de la tabla, registrando qué celdas abarcan varias filas o columnas para que el OCR se aplique de forma inteligente.
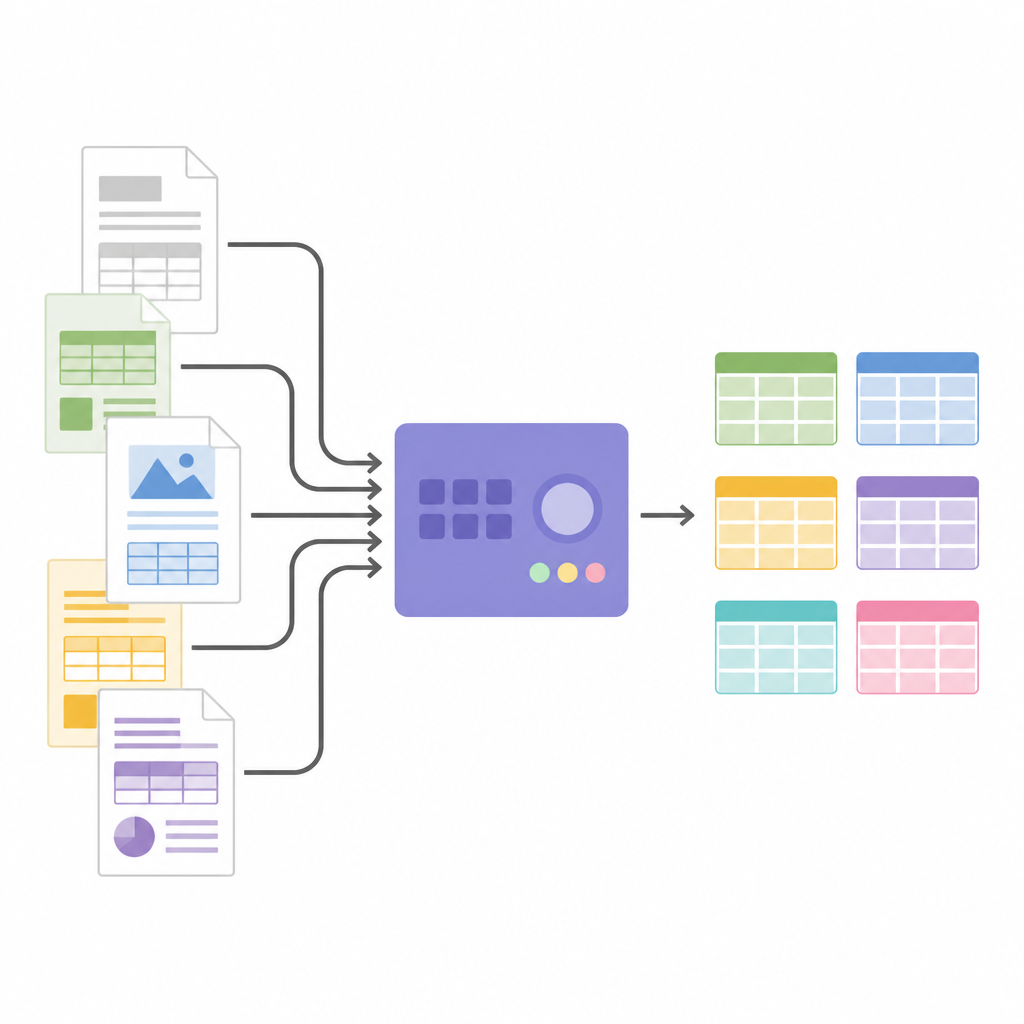
Convertir imágenes en datos estructurados
Una vez conocida la estructura de la tabla, SPARTAN recorta las imágenes de las celdas y las envía a un motor OCR. Soporta dos estrategias: leer cada celda una por una para máxima precisión, o leer grupos de celdas juntos para acelerar el procesamiento cuando las tablas son grandes. Trucos ingeniosos, como reducir ligeramente cada recorte y usar imágenes separadoras invisibles entre celdas, ayudan a evitar errores OCR comunes y a mantener las filas alineadas. El sistema puede fusionar tablas relacionadas a lo largo de páginas y exporta todo en JSON o CSV, listo para análisis o para alimentar otros programas. Dado que la arquitectura es modular, los usuarios pueden cambiar motores OCR, ajustar umbrales o conectar modelos de lenguaje grandes al final para etiquetar columnas, construir grafos de conocimiento o extraer hechos específicos sin cambiar la lógica central de detección de tablas.
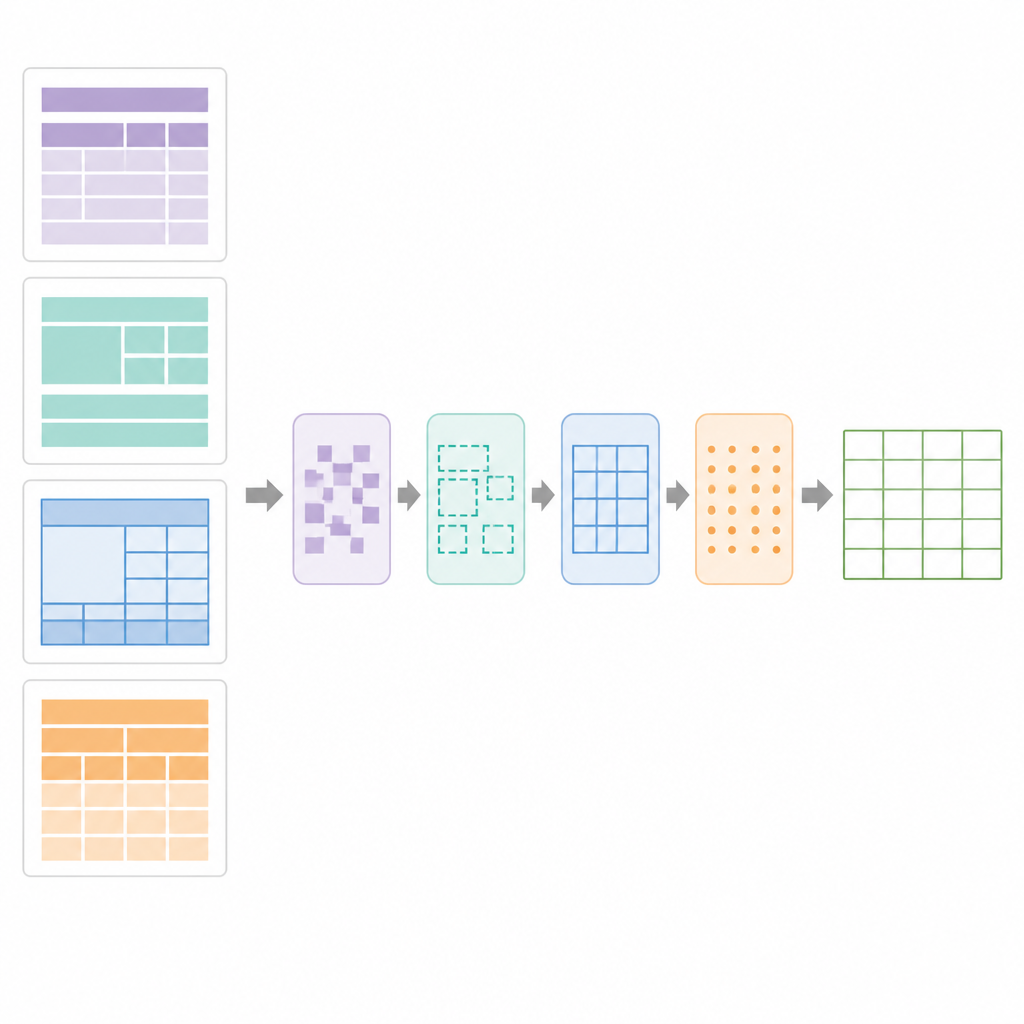
Qué tan bien funciona en el mundo real
Los autores probaron SPARTAN en más de veinte mil páginas extraídas de avisos electrónicos de cambio de producto, revistas científicas, certificados y hojas de datos, incluyendo muchas tablas complejas sin bordes y con anidamiento. En comparación con herramientas populares como Tabula, TabbyPDF, Deepdoctection y EMbTTBF, SPARTAN alcanzó mayor precisión, recall y puntuación F1 global en la detección de tablas, junto con mejor exactitud de caracteres tras el OCR. También funcionó más rápido que la mayoría de los sistemas basados en aprendizaje profundo y consumió mucha menos memoria, completando una página típica en unos segundos en un portátil estándar. Los principales puntos débiles aparecieron en escaneos de muy baja calidad o en diseños muy decorativos, donde el sistema prefiere no detectar tablas dudosas antes que inundar la salida con resultados falsos.
Qué significa esto para los usuarios cotidianos
Para pequeñas y medianas organizaciones que no pueden permitirse grandes infraestructuras de IA, SPARTAN demuestra que las reglas bien diseñadas y el análisis de imagen moderno siguen siendo herramientas potentes. Ofrece una forma transparente y ajustable de extraer tablas de PDFs cotidianos y convertirlas en datos estructurados que hojas de cálculo, bases de datos y herramientas analíticas pueden entender. Al hacerlo, reduce la brecha entre scripts simples y frágiles y redes neuronales pesadas, haciendo la extracción de tablas a gran escala, explicable y más accesible para cualquiera que trabaje con documentos complejos.
Cita: Nandurbarkar, S., Chaudhari, A.Y. & Mulla, R. SPARTAN: automated table detection and extraction from documents using advanced OpenCV heuristics and OCR techniques. Sci Rep 16, 14954 (2026). https://doi.org/10.1038/s41598-026-44325-7
Palabras clave: Tablas PDF, análisis de documentos, extracción de tablas, OCR, OpenCV