Clear Sky Science · tr
Büyük dil modelleriyle yinelemeli politika iyileştirmesi yoluyla duyusal-motor kontrol
Makinelere Kendi Başlarına Hareket Etmeyi Öğretmek
Çubuk dengelemek, bir sarkacı dik konuma sallamak veya bir vadiden çıkarak sürmek gibi becerileri insan mühendislerin her hareketi titizlikle kodlamasına ya da binlerce örnek gösterim toplamasına gerek kalmadan öğrenen bir robot hayal edin. Bu makale, sohbet botlarında kullanılan türdeki büyük dil modellerinin (LLM'ler) metin açıklamaları ve biraz deneme-yanılma yoluyla hareket eden makineler için kontrol stratejileri tasarlayan ve iyileştiren “beyinlere” nasıl dönüştürülebileceğini inceliyor. 
Sözlerden Hareketlere
Geleneksel robot kontrolü sıklıkla hareketi sabit yapı taşlarına böler; önceden tanımlanmış yürüyüş adımları veya erişme hareketleri gibi. Daha üst düzey bir program sonra bu parçaları seçip sıralar. Bu yaklaşım basit ortamlarda işe yarasa da, hareketlerin birbirine aktığı ve an be an hassas ayarlama gerektiren daha akışkan durumlarda zorlanır. Yazarlar bunun yerine LLM'lerden robotun duyduğu—konumu, hızı, açıları vb.—gibi bilgileri doğrudan sürekli motor komutlarına eşleyen tam kontrol kuralları oluşturmasını istiyor. Modelin aldığı tek başlangıç bilgisi, robotun gövdesinin, sensörlerinin ve motorlarının, çevrenin ve hedeflenen görevin doğal dil açıklamasıdır.
Düşünme ve İyileştirme Döngüsü
Yaklaşımın özünde Yinelemeli Politika İyileştirmesi adını verdikleri bir yinelemeli öğrenme döngüsü vardır. İlk adımda LLM, problemi aşamalara ayırarak düşünmeye yönlendirilir: önce düz bir dille yüksek düzey bir strateji çizer, sonra bunu açık IF–THEN–ELSE tarzı kurallara dönüştürür ve nihayet bu kuralları çalıştırılabilir koda çevirir. Bu ilk kontrolör bir simülasyon ortamında—örneğin dik tutulması gereken bir çubuğa sahip bir araba—çalıştırılır ve robotun performansı ölçülür. Kritik olarak, robotun kısa sensör okumaları ve ilgili eylem parçacıkları ile stratejinin ne kadar iyi çalıştığına dair bir özet LLM'ye geri verilir. LLM'den bu izleri analiz etmesi, zayıf yönleri bulması ve geliştirilmiş bir kontrolör üretmesi istenir. Bu döngü birçok kez tekrarlanır ve davranış kademeli olarak cilalanır. 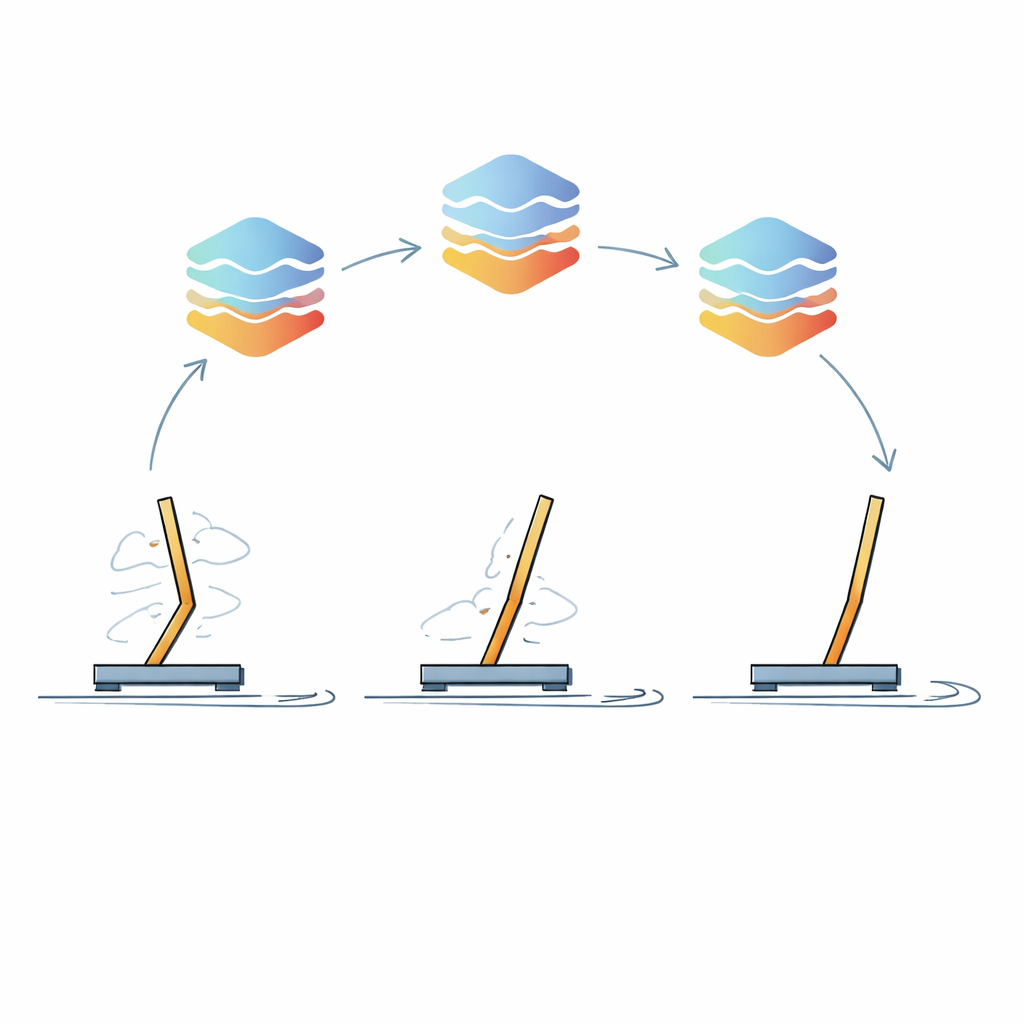
Fikri Test Etmek
Yöntemin gerçekten işe yarayıp yaramadığını görmek için araştırmacılar bunu pekiştirmeli öğrenmede kullanılan klasik kıyas görevleri üzerinde denediler: bir araba–çubuk sistemini dengelemek, bir sarkacı sallayıp stabilize etmek, dik bir yokuştan bir arabayı sürmek ve iki eklemli bir sistemin hedef yüksekliğe sallanmasını gerektiren acrobot görevini çözmek. Ayrıca popüler bir fizik simülatöründen ters çevrilmiş bir sarkaç görevini ele aldılar. Bu görevler ayrıntılı inceleme için yeterince basit ama yine de kilit zorlukları yakalıyor: robot her şeyi aynı anda görmüyor, ödüller gecikmeli geliyor ve fizik son derece kararsız olabiliyor. Ekip yaklaşık 70–120 milyar parametreli birkaç modern açık kaynak dil modelini karşılaştırdı, model çıktılarına ne kadar rastgelelik kattıklarını çeşitlendirdi ve güvenilir istatistikler elde etmek için her deneyi birkaç kez tekrarladı.
Dil Modelleri Makineleri Ne Kadar İyi Kontrol Ediyor?
En iyi performans gösteren model, GPT-oss adındaki 120 milyar parametreli sistem, çoğu görevde tutarlı şekilde yüksek kaliteli kontrol stratejileri keşfetti ve sık sık optimal veya optimale yakın skorlar elde etti. Başka bir model olan Qwen2.5 bazı problemlerde özellikle iyi performans gösterdi; ters çevrilmiş sarkaçta GPT-oss’u geride bıraksa da standart sarkaç görevinde zorlandı. Önemli olarak, LLM'lerin ürettiği ilk kontrolörler çoğunlukla vasattı; bu, modellerin yalnızca eğitim verilerinden hazır çözümleri hatırlamadığını gösteriyor. Performans yinelemeler boyunca belirgin şekilde iyileşti çünkü modeller geri bildirimleri kullanarak hangi sensör sinyallerinin daha önemli olduğunu ve bunların eylemleri nasıl etkilemesi gerektiğini ayarladılar. Yazarlar ayrıca her iyileştirme istemine kaç zaman adımı sensör verisi dahil edileceğini ve hangi geri bildirim parçalarının en kritik olduğunu incelediler; orta düzeyde veri ve önceki stratejiler hakkında zengin bilgilerin en iyi sonucu verdiğini buldular.
Gelecek Robotlar İçin Neden Önemli
Bir uzman olmayan için ana çıkarım, dil modellerinin sadece konuşmaktan daha fazlasını yapabileceğidir: makinelerin akıllıca hareket etmesini sağlayan ince motor kurallarının tasarlanmasına yardımcı olabilirler. Rastgele davranışla başlayıp büyük miktarda deneme-yanılma verisi gerektirmek yerine, bir LLM sözlü bir açıklamadan makul bir kontrol planı önerebilir ve robotun denediği durumların kısa kayıtlarını okuyarak bunu sürekli iyileştirebilir. Bu ön bilgi ve deneysel öğrenme karışımı, yetenekli robotlar ve diğer otonom sistemlerin geliştirilmesinin maliyetini ve eforunu azaltabilir. Hâlâ aşılması gereken engeller var—büyük modelleri çalıştırmak için gereken yoğun hesaplama ve çok karmaşık, uzun süreli görevlere ölçeklendirmenin zorluğu gibi—ancak çalışma, düşük seviyeli hareketlerin en azından kısmen bir zamanlar yalnızca bir sonraki kelimeyi tahmin edecek şekilde eğitilmiş sistemler tarafından şekillendirilebileceği bir yol öneriyor.
Atıf: Carvalho, J.T., Nolfi, S. Sensory-motor control with large language models via iterative policy refinement. Sci Rep 16, 13575 (2026). https://doi.org/10.1038/s41598-026-42091-0
Anahtar kelimeler: büyük dil modelleri, robot kontrolü, pekiştirmeli öğrenme, bedenselleşmiş ajanlar, yinelemeli politika iyileştirmesi