Clear Sky Science · fr
Contrôle sensori-moteur avec de grands modèles de langage via un raffinement itératif de politique
Apprendre aux machines à se mouvoir de façon autonome
Imaginez un robot qui apprend à équilibrer une perche, à redresser un pendule ou à sortir d'une vallée—sans que des ingénieurs humains programment chaque mouvement à la main ni collectent des milliers de démonstrations. Cet article examine comment les grands modèles de langage (LLM)—le même type de systèmes utilisés pour les chatbots—peuvent devenir des « cerveaux » qui conçoivent et améliorent des stratégies de contrôle pour de telles machines en mouvement, en s'appuyant principalement sur des descriptions textuelles et un peu d'essais-erreurs. 
Des mots aux mouvements
Le contrôle robotique traditionnel découpe souvent le mouvement en blocs fixes, comme des pas de marche prédéfinis ou des gestes de préhension. Un programme de plus haut niveau sélectionne ensuite et orchestre ces morceaux. Si cela fonctionne dans des contextes simples, la méthode peine dans des situations plus fluides où les mouvements se confondent et doivent être ajustés finement à chaque instant. Les auteurs demandent plutôt aux LLM de créer des règles de contrôle complètes qui cartographient directement ce que le robot perçoit—position, vitesse, angles, etc.—en commandes motrices continues. La seule information de départ fournie au modèle est une description en langage naturel du corps du robot, de ses capteurs et actionneurs, de l'environnement et de l'objectif à atteindre.
Une boucle de réflexion et d'amélioration
Le cœur de l'approche est une boucle d'apprentissage itérative que les auteurs appellent Raffinement Itératif de Politique. Dans une première étape, le LLM est incité à réfléchir au problème par étapes : il expose d'abord une stratégie de haut niveau en langage courant, puis la transforme en règles claires de type SI–ALORS–SINON, et enfin convertit ces règles en code exécutable. Ce contrôleur initial est exécuté dans un environnement simulé—par exemple un chariot avec une perche qu'il faut maintenir droite—et les performances du robot sont mesurées. De manière cruciale, de courts extraits des relevés sensoriels du robot et des actions correspondantes sont ensuite renvoyés au LLM, accompagnés d'un résumé de l'efficacité de la stratégie. Le LLM est invité à analyser ces traces, repérer les faiblesses et générer un contrôleur amélioré. Ce cycle se répète de nombreuses fois, polissant progressivement le comportement. 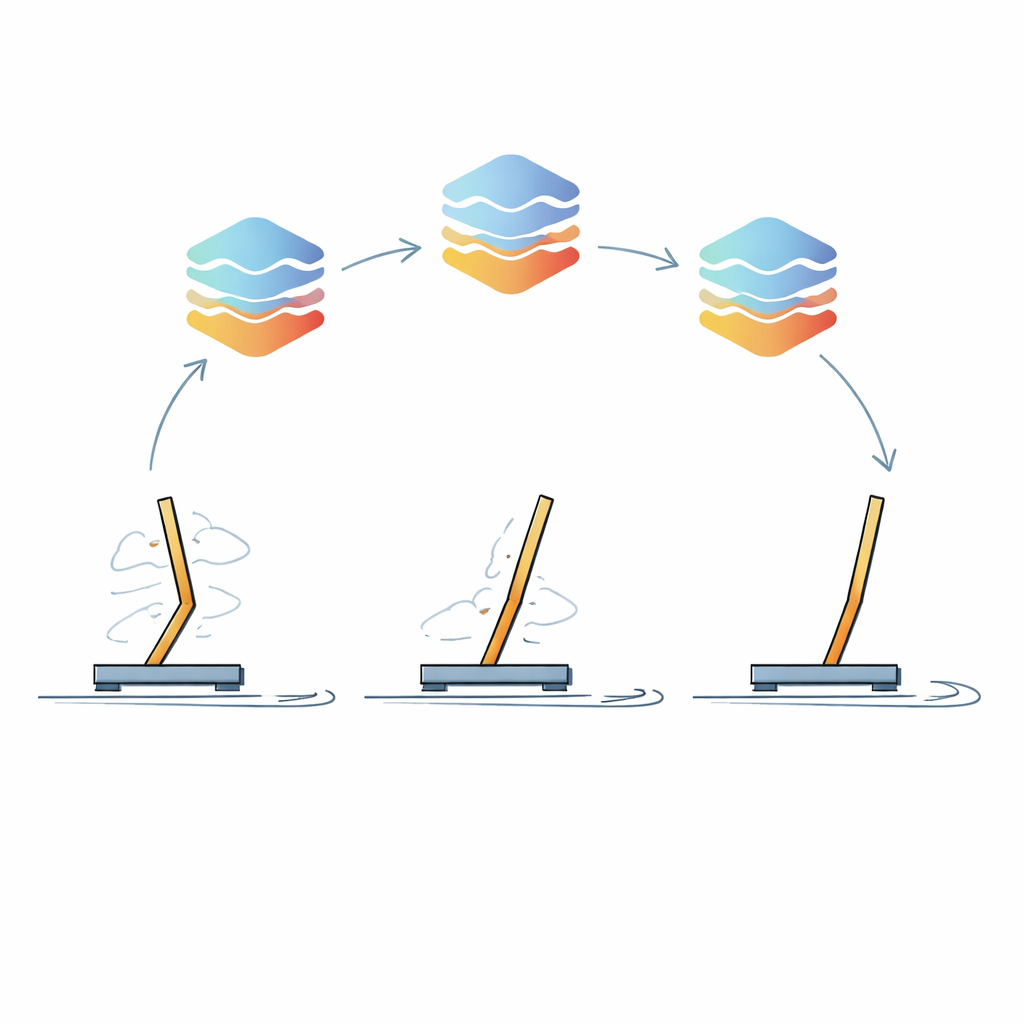
Mettre l'idée à l'épreuve
Pour vérifier l'efficacité de la méthode, les chercheurs l'ont testée sur un ensemble de tâches classiques de référence utilisées en apprentissage par renforcement : équilibrer un système chariot–perche, balancer et stabiliser un pendule, conduire une voiture en montée raide, et résoudre une tâche d'acrobot où un système à deux segments doit être balancé jusqu'à une hauteur cible. Ils ont également abordé une tâche de pendule inversé issue d'un simulateur physique populaire. Ces tâches sont suffisamment simples pour être étudiées en détail mais captent néanmoins des défis essentiels : le robot ne perçoit pas tout instantanément, les récompenses sont retardées et la dynamique peut être très instable. L'équipe a comparé plusieurs modèles de langage open source modernes d'environ 70 à 120 milliards de paramètres, a varié le degré d'aléa dans les sorties du modèle et a répété chaque expérience plusieurs fois pour obtenir des statistiques fiables.
Dans quelle mesure les modèles de langage contrôlent-ils les machines ?
Le modèle le plus performant, un système de 120 milliards de paramètres nommé GPT-oss, a systématiquement découvert des stratégies de contrôle de haute qualité sur la plupart des tâches, atteignant souvent des scores optimaux ou proches de l'optimum. Un autre modèle, Qwen2.5, a particulièrement bien réussi sur certains problèmes, surpassant même GPT-oss sur le pendule inversé, bien qu'il ait peiné sur d'autres tâches comme le pendule standard. Il est important de noter que les premiers contrôleurs produits par les LLM étaient souvent médiocres, montrant qu'ils ne se contentaient pas de sortir des solutions préenregistrées des données d'entraînement. Les performances se sont nettement améliorées au fil des itérations, les modèles utilisant le retour pour ajuster quels signaux sensoriels importaient le plus et comment ils devaient influencer les actions. Les auteurs ont aussi étudié combien d'instants de données sensorielles inclure dans chaque invite de raffinement et quelles pièces de rétroaction étaient les plus critiques, constatant qu'une quantité intermédiaire de données et des informations riches sur les stratégies précédentes donnaient les meilleurs résultats.
Pourquoi cela compte pour les robots de demain
Pour un non-spécialiste, l'idée principale est que les modèles de langage peuvent faire plus que dialoguer : ils peuvent aider à concevoir les règles motrices fines qui permettent aux machines de se mouvoir intelligemment. Plutôt que de partir d'un comportement aléatoire et de nécessiter d'énormes quantités d'essais-erreurs, un LLM peut proposer un plan de contrôle raisonnable à partir d'une description verbale, puis l'améliorer progressivement en lisant de courts comptes rendus de ce qui s'est passé lorsque le robot l'a essayé. Ce mélange de connaissances a priori et d'apprentissage expérimental pourrait réduire le coût et l'effort nécessaires pour construire des robots et autres systèmes autonomes performants. S'il reste des obstacles—comme la lourde puissance de calcul nécessaire pour exécuter de grands modèles et la difficulté à monter en échelle vers des tâches très complexes et de longue durée—l'étude suggère une voie vers des robots dont les mouvements de bas niveau sont façonnés, au moins en partie, par des systèmes initialement entraînés simplement à prédire le mot suivant dans une phrase.
Citation: Carvalho, J.T., Nolfi, S. Sensory-motor control with large language models via iterative policy refinement. Sci Rep 16, 13575 (2026). https://doi.org/10.1038/s41598-026-42091-0
Mots-clés: grands modèles de langage, contrôle robotique, apprentissage par renforcement, agents incarnés, raffinement itératif de politique