Clear Sky Science · sv
Sensorimotorisk styrning med stora språkmodeller via iterativ policysförfining
Att lära maskiner att röra sig själva
Föreställ dig en robot som lär sig att balansera en stång, svänga upp en pendel eller köra upp ur en dal—utan att människliga ingenjörer noggrant programmerar varje rörelse eller samlar tusentals demonstrationsexempel. Denna artikel undersöker hur stora språkmodeller (LLM)—samma typ av system som används i chattbottar—kan omvandlas till "hjärnor" som utformar och förbättrar styrstrategier för sådana rörliga maskiner, i huvudsak baserat på textbeskrivningar och en viss mängd trial-and-error. 
Från ord till rörelse
Traditionell robotstyrning delar ofta upp rörelser i fasta byggstenar, såsom fördefinierade gångsteg eller nå-rörelser. Ett högre program väljer sedan och sekvenserar dessa delar. Det fungerar i enkla fall, men det brister i mer flytande situationer där rörelser flyter ihop och måste finjusteras från ögonblick till ögonblick. Författarna ber i stället LLM att skapa fullständiga styrregler som direkt mappar vad roboten känner—dess position, hastighet, vinklar och så vidare—till kontinuerliga motoriska kommandon. Den enda inledande information modellen får är en naturlig språklig beskrivning av robotens kropp, dess sensorer och motorer, den omgivande miljön och vad den ska uppnå.
En slinga av reflektion och förfining
Kärnan i angreppssättet är en iterativ inlärningsslinga som författarna kallar Iterative Policy Refinement. I första steget uppmanas LLM att tänka igenom problemet i etapper: den skissar först en övergripande strategi i klartext, omvandlar sedan detta till tydliga IF–THEN–ELSE–regler och konverterar slutligen dessa regler till körbar kod. Den initiala kontrollern körs i en simulerad miljö—till exempel en vagn med en stång som måste hållas upprätt—och robotens prestanda mäts. Avgörande är att korta utdrag av robotens sensoravläsningar och motsvarande handlingar sedan matas tillbaka till LLM tillsammans med en sammanfattning av hur väl strategin fungerade. LLM ombeds analysera dessa spår, hitta svagheter och generera en förbättrad controller. Denna cykel upprepas många gånger och polerar gradvis beteendet. 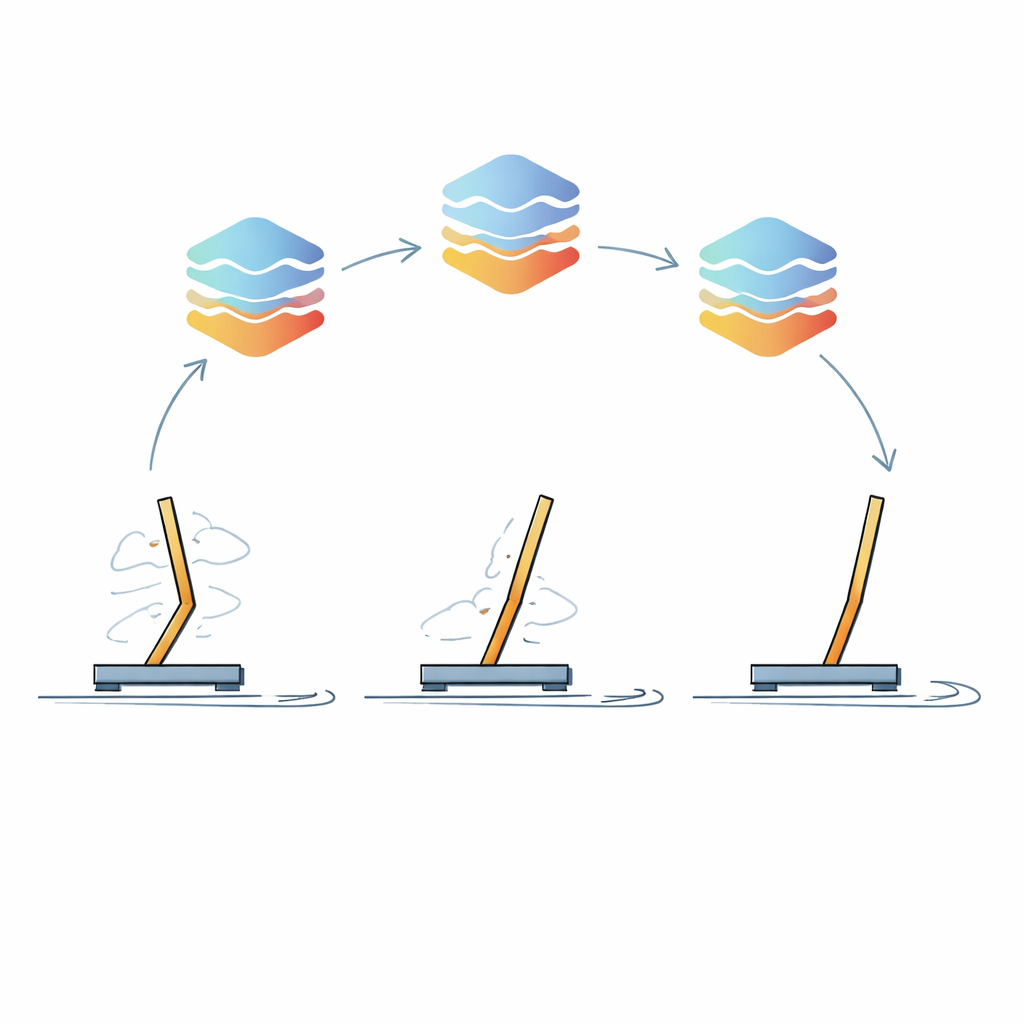
Sätta idén på prov
För att kontrollera om metoden verkligen fungerar testade forskarna den på en uppsättning klassiska benchmark-uppgifter som används inom förstärkningsinlärning: balansering av ett vagn–stång-system, svänga upp och stabilisera en pendel, köra en bil uppför en brant backe och lösa en acrobot-uppgift där ett tvåledat system måste svängas upp till en målhöjd. De gav sig också på en inverterad pendeluppgift från en populär fysiksimulator. Dessa uppgifter är tillräckligt enkla för att studeras i detalj men fångar ändå centrala utmaningar: roboten ser inte allt på en gång, belöningar kommer med fördröjning och fysiken kan vara mycket instabil. Teamet jämförde flera moderna open-source språkmodeller på ungefär 70–120 miljarder parametrar, varierade hur mycket slump de tillät i modellens utdata och upprepade varje experiment flera gånger för att få tillförlitlig statistik.
Hur bra styr språkmodeller maskiner?
Den bäst presterande modellen, ett 120-miljarder-parameter system kallat GPT-oss, upptäckte konsekvent högkvalitativa styrstrategier över de flesta uppgifter och nådde ofta optimala eller nära optimala resultat. En annan modell, Qwen2.5, presterade särskilt väl på vissa problem och överträffade till och med GPT-oss på den inverterade pendeln, även om den hade svårare med andra uppgifter såsom standardpendeln. Viktigt är att de första styrarna som LLM producerade ofta var mediokra, vilket visar att de inte bara återkallade färdiga lösningar från träningsdata. Prestandan förbättrades markant över iterationerna när modellerna använde feedback för att justera vilka sensorsignaler som var viktigast och hur de skulle påverka handlingarna. Författarna undersökte också hur många tidssteg av sensordata som skulle inkluderas i varje förfiningsprompt och vilka delar av feedbacken som var mest avgörande, och fann att en medelnivå av data och rik information om tidigare strategier fungerade bäst.
Varför detta är viktigt för framtidens robotar
För en icke-specialist är huvudpoängen att språkmodeller kan mer än att tala: de kan hjälpa till att utforma de finmaskiga motorregler som får maskiner att röra sig intelligent. Istället för att börja från slumpmässigt beteende och kräva enorma mängder trial-and-error-data kan en LLM föreslå en rimlig styrplan utifrån en verbal beskrivning och sedan stadigt förbättra den genom att läsa korta inspelningar av vad som hände när roboten försökte. Denna blandning av förhandskunskap och erfarenhetsbaserat lärande kan minska kostnad och ansträngning för att bygga kapabel robotik och andra autonoma system. Det finns fortfarande hinder—såsom den stora beräkningsbördan för att köra stora modeller och utmaningen att skala till mycket komplexa, långvariga uppgifter—men studien pekar på en väg mot robotar vars lågnivårörelser delvis formas av system som ursprungligen tränats för att förutsäga nästa ord i en mening.
Citering: Carvalho, J.T., Nolfi, S. Sensory-motor control with large language models via iterative policy refinement. Sci Rep 16, 13575 (2026). https://doi.org/10.1038/s41598-026-42091-0
Nyckelord: stora språkmodeller, robotstyrning, förstärkningsinlärning, förkroppsligade agenter, iterativ policysförfining