Clear Sky Science · tr
Varyasyonel veri asimilasyonu perspektifinden derin pekiştirmeli öğrenmede geriye bilgi yayılımını görselleştirmek
Bilgisayar biliminin ötesinde neden önemli
Hava tahminleri, iklim modelleri ve oyun oynayan yapay zekâ sistemleri birbirinden uzak alanlar gibi görünebilir, ancak hepsi aynı gizli motor üzerine dayanır: bir modeli, gerçekte olanlarla daha iyi uyuşacak şekilde yineleyerek düzeltmek. Bu makale o kara kutuyu açıyor. Basit bir Snake video oyunu test alanı kullanarak, yazar—görsel ve adım adım—öğrenme algoritmasının oyunu geliştirme biçiminin, meteorologların gözlemsel verileri kullanarak hava tahminlerini nasıl düzelttiğini yakından yansıttığını gösteriyor. Sonuç, modern yapay zekâ ile atmosfer biliminin uzun süreli yöntemleri arasında anlaşılır, sezgisel bir köprü kuruyor.
Ortak bir gizli motora sahip iki dünya
Sayısal hava tahmininde, varyasyonel veri asimilasyonu atmosferin fiziksel modelini gerçek dünya gözlemleriyle birleştirmek için kullanılır. Bilim insanları tahmin modelini ileriye doğru çalıştırır, ölçümlerle karşılaştırır ve ardından bu uyumsuzluklardan gelen bilgiyi geriye doğru yayarak modelin başlangıç koşullarını ayarlar. Oyun oynamayı veya robotları kontrol etmeyi öğrenen sistemleri güçlendiren derin pekiştirmeli öğrenme de benzer şekilde bir modeli ileri çalıştırır: bir ajan eylemler yapar, ödül veya ceza alır ve ardından sinir ağı içindeki bilgiyi geriye doğru göndererek içsel parametrelerini ayarlar. Makale, farklı terminolojinin altında her iki sürecin de aynı tür işi yaptığını—tüm olay dizisi boyunca sistemin performansını ölçen tek bir skoru minimize etmeyi—iddia ediyor.
Basit bir oyun, temiz bir laboratuvar
Bu bağlantıyı somutlaştırmak için çalışma sadeleştirilmiş bir ortam kullanıyor: klasik Snake oyununu öğrenen bir yapay zekâ ajanı. Ajan, çevresinin kompakt bir tanımını görür—yemeğin, duvarların ve kendi gövdesinin kafasına göre konumu—ve bu 11 bilgi parçasını tek gizli katmanlı küçük bir sinir ağına besler. Ağ üç seçenek üretir: sola dön, düz git veya sağa dön. Yılan her yiyecek yediğinde ajan pozitif ödül alır; duvara veya kendi bedenine çarparsa negatif ödül alır ve oyun biter. Kritik olarak yazar, bu ağın her bir parametresini—toplam 3.584 tanesini—her eğitim adımında kaydeder, böylece tüm öğrenme süreci tekrar oynatılabilir ve ayrıntılı biçimde incelenebilir.
Öğrenmeyi içeriden izlemek
Bu tam kayıtla makale, yılan öğrenirken ağın içsel “ağırlıklarının” nasıl değiştiğini görselleştiriyor. Başlangıçta eylemler neredeyse rastlantısaldır ve ağırlık güncellemeleri dağınık ve küçüktür. Birçok oyun boyunca ajan ızgarayı keşfettikçe ve pek çok başarı ile başarısızlık yaşadıkça bu güncellemeler yapılandırılmış desenler oluşturmaya başlar. Yılanın yolları daha uzun ve yiyeceğe doğru daha yönlendirilmiş hale gelir. Çalışma, bir hamleden sonra her küçük öğrenme patlamasının kısa menzilli bir düzeltme gibi olduğunu gösteriyor: anlık ödüllerden gelen bilgi geriye doğru dalgalar halinde o hamleyi üreten parametreleri ayarlıyor. Periyodik olarak, sistem geçmiş oyun deneyimlerini yeniden kullanır ve eski tercihlerin en son parametreler altında nasıl iyi veya kötü göründüğünü yeniden hesaplar. Bu, hava merkezlerinin güncellenmiş bir tahmin etrafında tekrar tekrar lineerleştirip yeniden optimize etmelerine benzeyen dört boyutlu varyasyonel veri asimilasyonuna benzer.
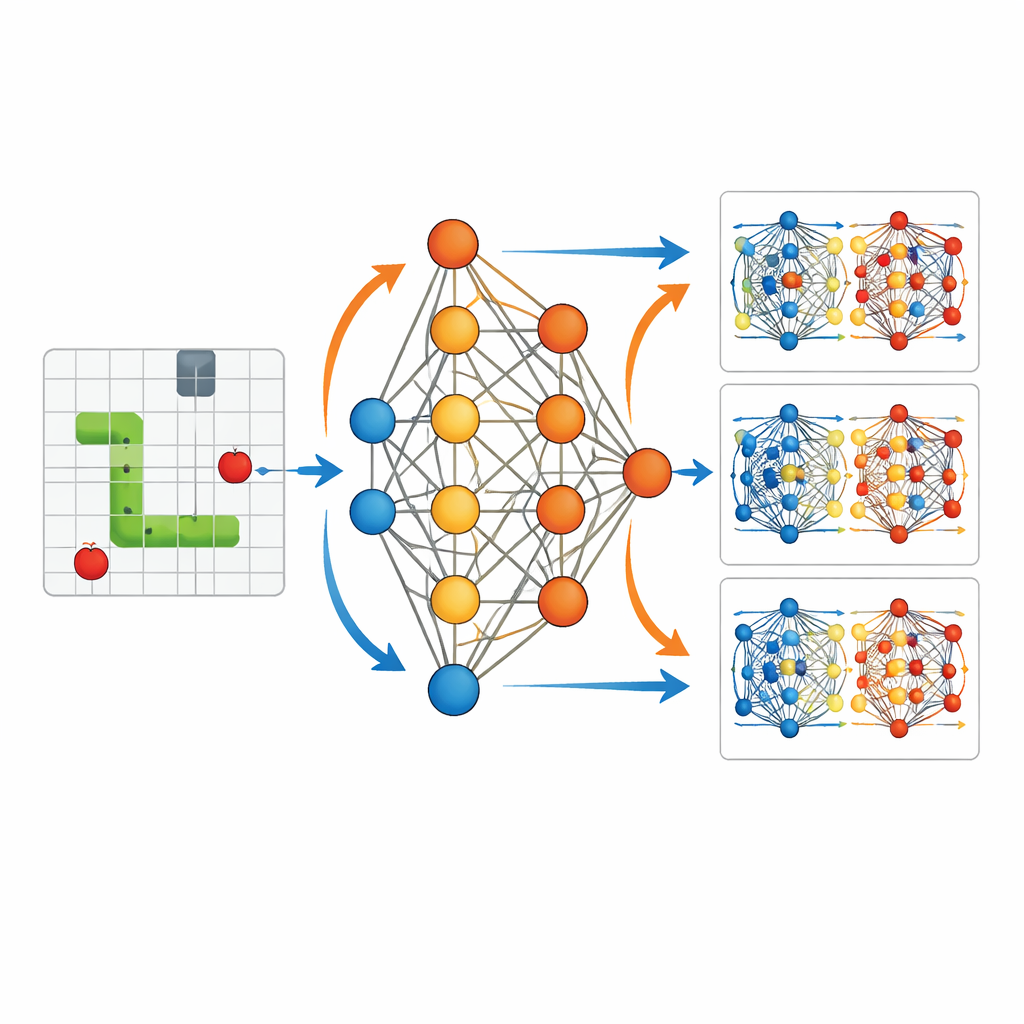
Rastlantısal dolaşmadan amaçlı harekete
Eğitilmiş ve eğitilmemiş ajanlar arasındaki karşıtlık, bu gizli güncellemelerin etkisini görmek için durumu açık hale getiriyor. Eğitim yokken yılan başlangıç noktasının yakınında dolanır, belirgin bir strateji olmadan duvarlara veya kendi bedenine çarpar. Eğitimden sonra aynı ağ yapısı, tehlikelerden kaçınırken yiyeceğe doğru aktif olarak yönelen düzgün, amaçlı yörüngeler üretir. Parametre değişikliklerinin görselleştirmeleri, belirli zamanlardaki ödüllerin ağdaki belirli bağlantıları seçici olarak güçlendirdiğini veya zayıflattığını göstererek davranışı organize eder. Bu, veri asimilasyonundaki gözlemsel bilginin modelin başlangıç koşullarını kademeli olarak yeniden şekillendirip tahminlerin gerçeğe daha uygun yörüngeleri izlemesini sağlamasına benzer.
Çalışmanın gerçekten gösterdiği şey
Bu çalışma yeni bir öğrenme algoritması ya da hava tahmini için yeni bir yöntem sunmuyor. Bunun yerine ortak bir ilkenin açık, öğretici bir resmini veriyor: hem derin pekiştirmeli öğrenme hem de varyasyonel veri asimilasyonu modeli tekrar tekrar ileri çalıştırır, ne kadar iyi performans gösterdiğini ölçer ve ardından bu bilgiyi bazı ayarlanabilir nicelikleri iyileştirmek üzere geriye doğru gönderir. Snake oyununda bu nicelikler bir stratejiyi kodlayan sinir ağı ağırlıklarıdır; hava tahmininde ise bir tahmini başlatan atmosferik durumlardır. Bilginin geriye doğru akışını küçük, tamamen gözlemlenebilir bir sistemde görünür kılarak makale, atmosfer bilimcilerine modern makine öğrenimi dinamiklerini daha sezgisel anlatıyor ve yapay zekâ araştırmacılarına yerbilimlerinde benzer fikirlerin uzun geçmişini takdir etme olanağı sağlıyor.
Atıf: Wang, KY. Visualising backward information propagation in deep reinforcement learning from a variational data assimilation perspective. Sci Rep 16, 11581 (2026). https://doi.org/10.1038/s41598-026-42086-x
Anahtar kelimeler: pekiştirmeli öğrenme, veri asimilasyonu, yapay sinir ağları, hava tahmini, optimizasyon