Clear Sky Science · de
Visualisierung der rückwärtsgerichteten Informationsausbreitung im Deep Reinforcement Learning aus Sicht der variationalen Datenassimilation
Warum das über die Informatik hinaus wichtig ist
Wettervorhersagen, Klimamodelle und spielende künstliche Intelligenz wirken auf den ersten Blick weit auseinanderliegend, stützen sich aber auf denselben verborgenen Motor: ein Modell wiederholt so zu justieren, dass es besser mit der Realität übereinstimmt. Dieses Paper öffnet diese Black Box. Anhand des einfachen Snake-Videospiels als Prüfstand zeigt die Autorin — bildlich und Schritt für Schritt — dass die Art, wie ein Lernalgorithmus sein Spiel verbessert, eng dem gleicht, wie Meteorologinnen und Meteorologen Vorhersagen mithilfe von Beobachtungsdaten verfeinern. Das Ergebnis ist eine klare, intuitive Brücke zwischen moderner KI und lang etablierten Methoden der Atmosphärenwissenschaft.
Zwei Welten mit demselben verborgenen Motor
In der numerischen Wettervorhersage wird die variationale Datenassimilation eingesetzt, um ein physikalisches Atmosphärenmodell mit realen Beobachtungen zu kombinieren. Wissenschaftlerinnen und Wissenschaftler laufen das Vorhersagemodell vorwärts durch, vergleichen es mit Messungen und propagieren dann die Informationen aus diesen Abweichungen rückwärts, um die Anfangsbedingungen des Modells anzupassen. Deep Reinforcement Learning, das Systeme antreibt, die lernen, Spiele zu spielen oder Roboter zu steuern, läuft ebenfalls vorwärts: Ein Agent trifft Aktionen, erhält Belohnungen oder Bestrafungen und sendet dann Informationen rückwärts durch ein neuronales Netz, um seine internen Parameter anzupassen. Das Paper argumentiert, dass—unter der unterschiedlichen Fachsprache—beide Prozesse dieselbe Art von Arbeit leisten: sie minimieren eine einzige Fehlergröße, die misst, wie gut das System über eine ganze Abfolge von Ereignissen abschneidet.
Ein einfaches Spiel als sauberes Labor
Um diese Verbindung greifbar zu machen, verwendet die Studie ein reduziertes Setting: einen KI-Agenten, der das klassische Snake-Spiel lernt. Der Agent sieht eine kompakte Beschreibung seiner Umgebung—wo sich Futter, Wände und sein eigener Körper relativ zum Kopf befinden—und speist diese 11 Informationsbits in ein kleines neuronales Netz mit einer versteckten Schicht. Das Netz gibt drei Optionen aus: links abbiegen, geradeaus oder rechts abbiegen. Jedes Mal, wenn die Schlange Futter frisst, erhält der Agent eine positive Belohnung; stürzt sie gegen eine Wand oder in sich selbst, gibt es eine negative Belohnung und das Spiel endet. Entscheidend ist, dass die Autorin jeden einzelnen Parameter dieses Netzes—insgesamt 3.584—bei jedem Trainingsschritt aufzeichnet, sodass der gesamte Lernprozess vollständig wieder abgespielt und im Detail untersucht werden kann.
Lernen von innen beobachten
Mit diesem vollständigen Protokoll visualisiert das Paper, wie sich die internen „Gewichte“ des Netzes verändern, während die Schlange lernt. Zu Beginn sind die Aktionen fast zufällig und die Gewichtsänderungen verstreut und klein. Über viele Spiele hinweg, während der Agent das Gitter erkundet und viele Erfolge und Misserfolge erlebt, beginnen diese Updates strukturierte Muster zu bilden. Die Pfade der Schlange werden länger und zielgerichteter zum Futter hin. Die Studie zeigt, dass jeder kleine Lernschub nach einem Zug wie eine kurzreichweitige Korrektur wirkt: Informationen aus unmittelbar erhaltenen Belohnungen breiten sich rückwärts aus, um die Parameter anzupassen, die diesen Zug hervorgebracht haben. Periodisch nutzt das System auch vergangene Spielerfahrungen wieder, indem es neu berechnet, wie gut oder schlecht diese alten Entscheidungen unter den aktuellsten Parametern aussehen. Das ähnelt dem Vorgehen von Wetterzentren, die in der vierdimensionalen variationalen Datenassimilation wiederholt linearisierten und um eine aktualisierte Vorhersage herum reoptimierten.
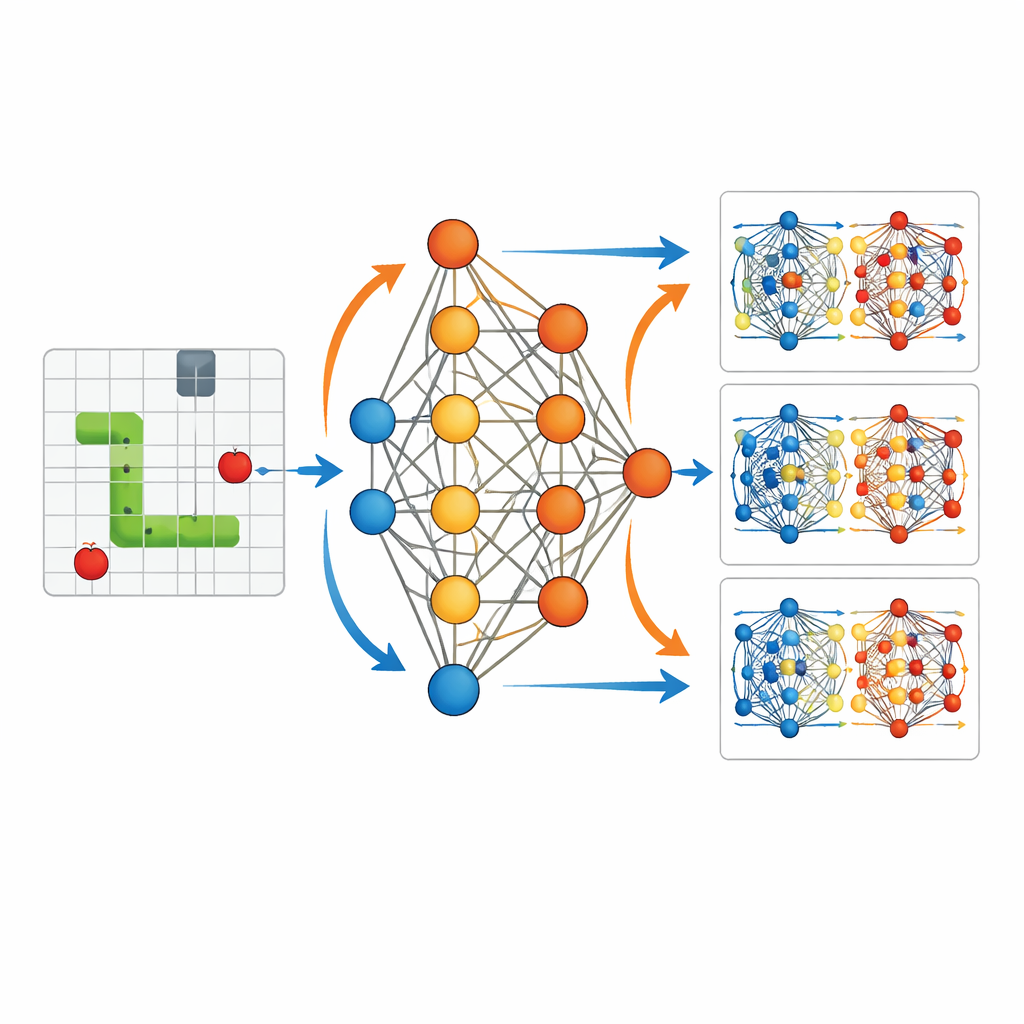
Vom zufälligen Umherirren zur zielgerichteten Bewegung
Der Kontrast zwischen trainierten und untrainierten Agenten macht die Wirkung dieser verborgenen Updates leicht sichtbar. Ohne Training schlängelt sich die Schlange in der Nähe ihres Startpunkts umher und stößt ohne erkennbare Strategie gegen Wände oder in sich selbst. Nach dem Training erzeugt dieselbe Netzstruktur glatte, zielgerichtete Bahnen, die aktiv auf das Futter zusteuern und Gefahren meiden. Visualisierungen der Parameteränderungen zeigen, dass Belohnungen zu bestimmten Zeiten selektiv bestimmte Verbindungen im Netz stärken oder schwächen und so das Verhalten organisieren. Das spiegelt wider, wie Beobachtungsinformationen in der Datenassimilation schrittweise die Modell-Anfangsbedingungen umformen, sodass Vorhersagen Trajektorien folgen, die besser mit der Realität übereinstimmen.
Was die Studie wirklich zeigt
Die Arbeit führt keinen neuen Lernalgorithmus und keine neue Art der Wettervorhersage ein. Sie bietet vielmehr ein klares, lehrreiches Bild eines gemeinsamen Prinzips: Sowohl Deep Reinforcement Learning als auch variationale Datenassimilation laufen ein Modell wiederholt vorwärts, messen, wie gut es abgeschnitten hat, und senden diese Information dann rückwärts, um eine Menge anpassbarer Größen zu verbessern. Im Snake sind diese Größen die Gewichte des neuronalen Netzes, die eine Strategie kodieren; in der Wettervorhersage sind es die atmosphärischen Zustände, die eine Vorhersage initialisieren. Indem der rückwärtsgerichtete Informationsfluss in einem kleinen, vollständig beobachtbaren System sichtbar gemacht wird, vermittelt das Paper Atmosphärenwissenschaftlerinnen und -wissenschaftlern ein intuitiveres Verständnis moderner Machine-Learning-Dynamiken und hilft KI-Forschenden, die lange Geschichte ähnlicher Ideen in der Geowissenschaft zu schätzen.
Zitation: Wang, KY. Visualising backward information propagation in deep reinforcement learning from a variational data assimilation perspective. Sci Rep 16, 11581 (2026). https://doi.org/10.1038/s41598-026-42086-x
Schlüsselwörter: bestärkendes Lernen, Datenassimilation, Neuronale Netze, Wettervorhersage, Optimierung