Clear Sky Science · ru
Визуализация обратной передачи информации в глубоком обучении с подкреплением с точки зрения вариационной ассимиляции данных
Почему это важно за пределами информатики
Прогнозы погоды, климатические модели и искусственный интеллект для игр кажутся далекими областями, но все они опираются на один и тот же скрытый механизм: многократное корректирование модели, чтобы она лучше соответствовала происходящему в реальности. Эта статья приоткрывает эту «черную коробку». На простом примере видеоигры Snake автор визуально и пошагово показывает, что способ, которым алгоритм обучения улучшает свою игру, тесно напоминает процесс, с помощью которого метеорологи уточняют прогнозы, используя наблюдения. В результате получено ясное, интуитивное звено между современным ИИ и давними методами атмосферной науки.
Два мира с общим скрытым механизмом
В численном прогнозировании погоды вариационная ассимиляция данных используется для объединения физической модели атмосферы с реальными наблюдениями. Ученые запускают модель прогноза вперед во времени, сравнивают её с измерениями и затем распространяют информацию об этих расхождениях назад, чтобы скорректировать начальные условия модели. Глубокое обучение с подкреплением, которое лежит в основе систем, обучающихся играть или управлять роботами, тоже запускает модель вперед: агент совершает действия, получает награды или штрафы и затем передает информацию назад через нейронную сеть, чтобы подстроить её параметры. В статье утверждается, что под разной терминологией оба процесса выполняют одну и ту же задачу — минимизацию единой меры качества, оценивающей поведение системы на всей последовательности событий.
Простая игра как чистая лаборатория
Чтобы сделать это сопоставление конкретным, в исследовании использована упрощённая обстановка: агент ИИ, обучающийся играть в классическую игру Snake. Агент видит компактное описание окружения — где находятся еда, стены и его собственное тело относительно головы — и подаёт эти 11 бит информации в небольшую нейронную сеть с одним скрытым слоем. Сеть выдает три варианта: поворот влево, идти прямо или повернуть вправо. Каждый раз, когда змея съедает еду, агент получает положительную награду; при столкновении со стеной или с собой — отрицательную награду и игра заканчивается. Важно, что автор записывает все параметры этой сети — всего 3584 — на каждом шаге обучения, так что весь процесс обучения можно воспроизвести и подробно исследовать.
Наблюдение обучения изнутри
Имея полный протокол, статья визуализирует, как меняются внутренние «веса» сети по мере обучения змеи. Сначала действия почти случайны, а обновления весов рассыпаны и малы. С течением многих игр, по мере того как агент исследует поле и переживает множество успехов и неудач, эти обновления начинают выстраиваться в структурированные шаблоны. Траектории змеи становятся длиннее и более направленными к еде. Исследование показывает, что каждый небольшой всплеск обучения после хода похож на краткосрочную коррекцию: информация от немедленных вознаграждений распространяется назад, корректируя параметры, которые породили тот ход. Периодически система также повторно использует прошлые игровые эпизоды, пересчитывая, насколько хороши или плохи были те давние решения с точки зрения актуальных параметров. Это похоже на то, как метеоцентры многократно линеаризуют и переоптимизируют вокруг обновлённого прогноза в четырехмерной вариационной ассимиляции данных.
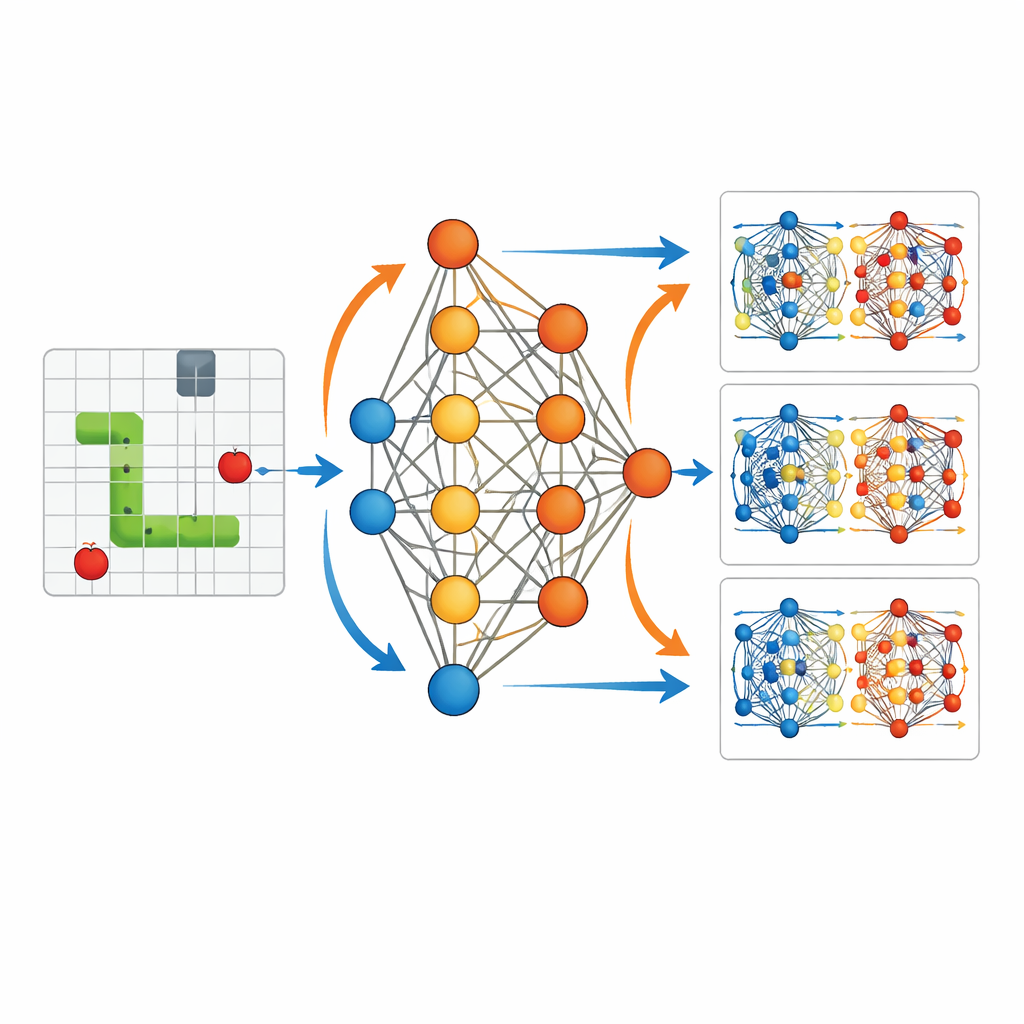
От случайного блуждания к целенаправленному движению
Контраст между обученным и необученным агентом делает эффект этих скрытых обновлений наглядным. Без обучения змея бродит рядом со стартовой точкой, врезаясь в стены или в себя и не вырабатывая явной стратегии. После обучения та же структура сети порождает плавные, целенаправленные траектории, которые активно направляются к еде и избегают опасности. Визуализации изменений параметров показывают, что вознаграждения в конкретные моменты выборочно усиливают или ослабляют отдельные соединения в сети, организуя её поведение. Это похоже на то, как observational информация в ассимиляции данных постепенно изменяет начальные условия модели, чтобы прогнозы следовали траекториям, более согласующимся с реальностью.
Что на самом деле демонстрирует исследование
Работа не вводит новый алгоритм обучения и не предлагает новый способ прогнозирования погоды. Вместо этого она дает ясную, наглядную картину общего принципа: и глубокое обучение с подкреплением, и вариационная ассимиляция данных многократно запускают модель вперёд, оценивают её результаты и затем передают эту информацию назад, чтобы улучшить набор настраиваемых величин. В Snake эти величины — веса нейронной сети, кодирующие стратегию; в прогнозировании погоды — состояния атмосферы, задающие начальные условия. Сделав обратный поток информации видимым в небольшой, полностью наблюдаемой системе, статья даёт атмосферным ученым более интуитивное представление о динамике современных методов машинного обучения и помогает исследователям ИИ оценить долгую историю похожих идей в геонауках.
Цитирование: Wang, KY. Visualising backward information propagation in deep reinforcement learning from a variational data assimilation perspective. Sci Rep 16, 11581 (2026). https://doi.org/10.1038/s41598-026-42086-x
Ключевые слова: обучение с подкреплением, ассими лция данных, нейронные сети, прогноз погоды, оптимизация