Clear Sky Science · pl
Wizualizacja wstecznego przepływu informacji w głębokim uczeniu ze wzmocnieniem z perspektywy wariacyjnej asyminacji danych
Dlaczego to ma znaczenie poza informatyką
Prognozy pogody, modele klimatyczne i sztuczna inteligencja grająca w gry mogą wydawać się odległymi dziedzinami, a jednak opierają się na tym samym ukrytym mechanizmie: wielokrotnym korygowaniu modelu, aby lepiej zgadzał się z rzeczywistością. Ten artykuł otwiera tę czarną skrzynkę. Na przykładzie prostej gry Snake autor pokazuje — wizualnie i krok po kroku — że sposób, w jaki algorytm uczący się poprawia swoją grę, bardzo przypomina sposób, w jaki meteorolodzy udoskonalają prognozy pogodowe, wykorzystując obserwacje. Efekt to klarowny, intuicyjny most między nowoczesną sztuczną inteligencją a od dawna stosowanymi metodami w naukach atmosferycznych.
Dwa światy z wspólnym ukrytym mechanizmem
W numerycznym prognozowaniu pogody wariacyjna asymilacja danych służy do łączenia fizycznego modelu atmosfery z obserwacjami z rzeczywistości. Naukowcy uruchamiają model prognozy do przodu w czasie, porównują go z pomiarami, a następnie propagują informacje o tych niezgodnościach wstecz, aby skorygować warunki początkowe modelu. Głębokie uczenie ze wzmocnieniem, które napędza systemy uczące się gry czy sterowania robotami, również uruchamia model do przodu: agent podejmuje działania, otrzymuje nagrody lub kary, a następnie przesyła informacje wstecz przez sieć neuronową, by dostroić jej parametry. Artykuł argumentuje, że pod odmiennym żargonem oba procesy wykonują ten sam rodzaj pracy — minimalizują jedną miarę (funkcję kosztu), która ocenia, jak dobrze system radzi sobie w całej sekwencji zdarzeń.
Prosta gra jako czyste laboratorium
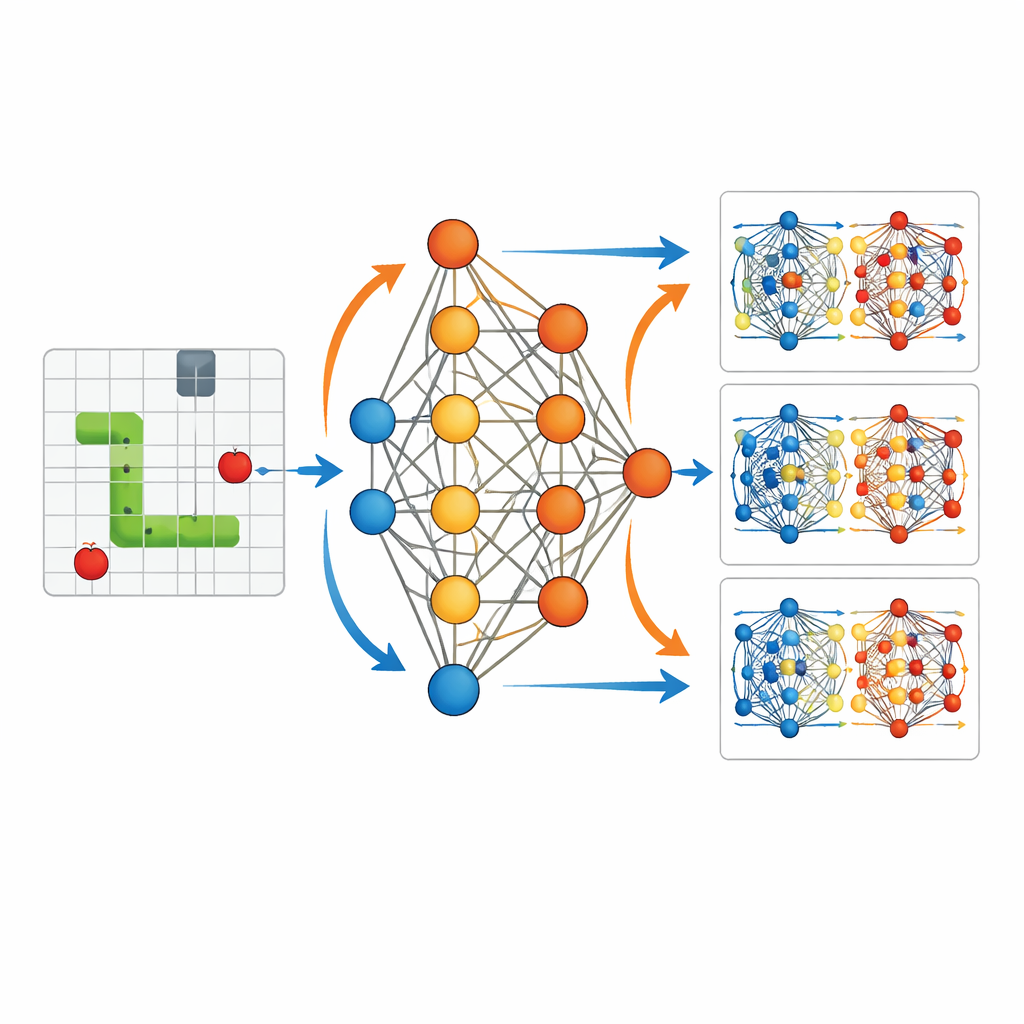
Aby uczynić to powiązanie namacalnym, badanie korzysta z uproszczonego środowiska: agenta AI uczącego się klasycznej gry Snake. Agent widzi skompaktowany opis otoczenia — gdzie znajdują się jedzenie, ściany i jego własne ciało względem głowy — i przekazuje tych 11 bitów informacji do małej sieci neuronowej z jedną warstwą ukrytą. Sieć daje trzy opcje: skręć w lewo, idź prosto lub skręć w prawo. Za każdym razem, gdy wąż zjada jedzenie, agent otrzymuje dodatnią nagrodę; jeśli uderzy w ścianę lub we własne ciało, dostaje ujemną nagrodę i gra się kończy. Kluczowe jest to, że autor zapisuje każdy parametr tej sieci — łącznie 3 584 — na każdym kroku treningu, tak aby cały proces uczenia mógł zostać odtworzony i szczegółowo przeanalizowany.
Obserwowanie uczenia od środka
Dysponując pełnym zapisem, artykuł wizualizuje, jak wewnętrzne „wagi” sieci zmieniają się w miarę nauki węża. Na początku działania są prawie losowe, a aktualizacje wag rozproszone i niewielkie. W miarę rozgrywek, gdy agent eksploruje pole i doświadcza wielu sukcesów i porażek, te aktualizacje zaczynają formować uporządkowane wzory. Ścieżki węża stają się dłuższe i bardziej ukierunkowane na jedzenie. Badanie pokazuje, że każda mała fala uczenia po ruchu przypomina krótkodystansową korektę: informacje z bezpośrednich nagród rozchodzą się wstecz, by skorygować parametry, które wygenerowały ten ruch. Okazjonalnie system także ponownie wykorzystuje wcześniejsze doświadczenia z gry, przeliczając, jak dobre lub złe wyglądają tamte wybory przy najnowszych parametrach. To przypomina sposób, w jaki ośrodki meteorologiczne wielokrotnie linearizują i ponownie optymalizują wokół zaktualizowanej prognozy w czterowymiarowej wariacyjnej asymilacji danych.
Od losowego błądzenia do celowego ruchu
Kontrast między agentami przeszkolonymi i nieprzeszkolonymi czyni efekt tych ukrytych aktualizacji łatwym do zobaczenia. Bez treningu wąż wije się w pobliżu punktu startowego, uderzając w ściany lub we własne ciało bez widocznej strategii. Po treningu ta sama struktura sieci generuje płynne, celowe trajektorie, które aktywnie zmierzają do jedzenia, unikając niebezpieczeństw. Wizualizacje zmian parametrów pokazują, że nagrody w określonych momentach selektywnie wzmacniają lub osłabiają poszczególne połączenia w sieci, organizując jej zachowanie. To odzwierciedla sposób, w jaki informacje obserwacyjne w asymilacji danych stopniowo przekształcają warunki początkowe modelu, tak aby prognozy podążały za trajektoriami bardziej zgodnymi z rzeczywistością.
Co badanie faktycznie pokazuje
Praca nie wprowadza nowego algorytmu uczenia ani nowego sposobu prognozowania pogody. Zamiast tego oferuje jasny, dydaktyczny obraz wspólnej zasady: zarówno głębokie uczenie ze wzmocnieniem, jak i wariacyjna asymilacja danych wielokrotnie uruchamiają model do przodu, mierzą, jak dobrze wypadł, a następnie przesyłają tę informację wstecz, by poprawić pewien zestaw regulowanych wielkości. W Snake tymi wielkościami są wagi sieci neuronowej kodujące strategię; w prognozowaniu pogody to stany atmosferyczne inicjujące prognozę. Pokazując wsteczny przepływ informacji w małym, w pełni obserwowalnym systemie, artykuł daje naukowcom atmosfery bardziej intuicyjne wyczucie dynamiki współczesnego uczenia maszynowego i pomaga badaczom AI docenić długą historię podobnych pomysłów w geonaukach.
Cytowanie: Wang, KY. Visualising backward information propagation in deep reinforcement learning from a variational data assimilation perspective. Sci Rep 16, 11581 (2026). https://doi.org/10.1038/s41598-026-42086-x
Słowa kluczowe: uczenie ze wzmocnieniem, asymilacja danych, sieci neuronowe, prognozowanie pogody, optymalizacja