Clear Sky Science · es
Visualización de la propagación hacia atrás de la información en el aprendizaje por refuerzo profundo desde la perspectiva de la asimilación variacional de datos
Por qué esto importa más allá de la informática
Los pronósticos meteorológicos, los modelos climáticos y la inteligencia artificial para jugar a videojuegos pueden parecer mundos aparte, pero comparten un mismo motor oculto: ajustar repetidamente un modelo para que se acerque más a lo que realmente ocurre. Este artículo abre esa caja negra. Usando el sencillo videojuego Snake como banco de pruebas, el autor muestra —visual y paso a paso— que la manera en que un algoritmo de aprendizaje mejora su juego refleja de forma estrecha cómo los meteorólogos refinan sus pronósticos usando datos observacionales. El resultado es un puente claro e intuitivo entre la IA moderna y métodos consolidados en la ciencia atmosférica.
Dos mundos con un motor oculto compartido
En la predicción numérica del tiempo, la asimilación variacional de datos se utiliza para combinar un modelo físico de la atmósfera con observaciones del mundo real. Los científicos ejecutan el modelo de pronóstico hacia adelante en el tiempo, lo comparan con las mediciones y luego propagan hacia atrás la información derivada de esas discrepancias para ajustar las condiciones iniciales del modelo. El aprendizaje por refuerzo profundo, que impulsa sistemas que aprenden a jugar o a controlar robots, también ejecuta un modelo hacia adelante: un agente realiza acciones, recibe recompensas o penalizaciones y luego envía información hacia atrás a través de una red neuronal para ajustar sus parámetros internos. El artículo sostiene que, bajo la diferencia de jerga, ambos procesos realizan el mismo tipo de trabajo: minimizar una única puntuación que mide el rendimiento del sistema a lo largo de toda una secuencia de eventos.
Un juego simple como laboratorio limpio
Para concretar esta conexión, el estudio usa un entorno simplificado: un agente de IA que aprende a jugar al clásico Snake. El agente percibe una descripción compacta de su entorno —dónde están la comida, las paredes y su propio cuerpo respecto a la cabeza— y alimenta esos 11 bits de información a una pequeña red neuronal con una capa oculta. La red ofrece tres opciones: girar a la izquierda, seguir recto o girar a la derecha. Cada vez que la serpiente come, el agente recibe una recompensa positiva; si choca contra una pared o contra sí misma, obtiene una recompensa negativa y el juego termina. De forma crucial, el autor registra cada parámetro de esta red —3.584 en total— en cada paso de entrenamiento, de modo que todo el proceso de aprendizaje puede reproducirse y examinarse en detalle.
Observar el aprendizaje desde dentro
Con este registro completo, el artículo visualiza cómo cambian los «pesos» internos de la red a medida que la serpiente aprende. Al principio, las acciones son casi aleatorias y las actualizaciones de pesos son dispersas y pequeñas. Tras muchas partidas, mientras el agente explora la cuadrícula y experimenta numerosos éxitos y fracasos, esas actualizaciones empiezan a formar patrones estructurados. Las trayectorias de la serpiente se alargan y se orientan más hacia la comida. El estudio muestra que cada pequeño estallido de aprendizaje tras una jugada es como una corrección de corto alcance: la información procedente de recompensas inmediatas se propaga hacia atrás para ajustar los parámetros que produjeron esa acción. Periódicamente, el sistema también reutiliza experiencias de partidas pasadas, recomputando cuán buenas o malas parecen esas decisiones antiguas bajo los parámetros más recientes. Esto se asemeja a cómo los centros meteorológicos linearizan y reoptimizan repetidamente alrededor de un pronóstico actualizado en la asimilación variacional de datos en cuatro dimensiones.
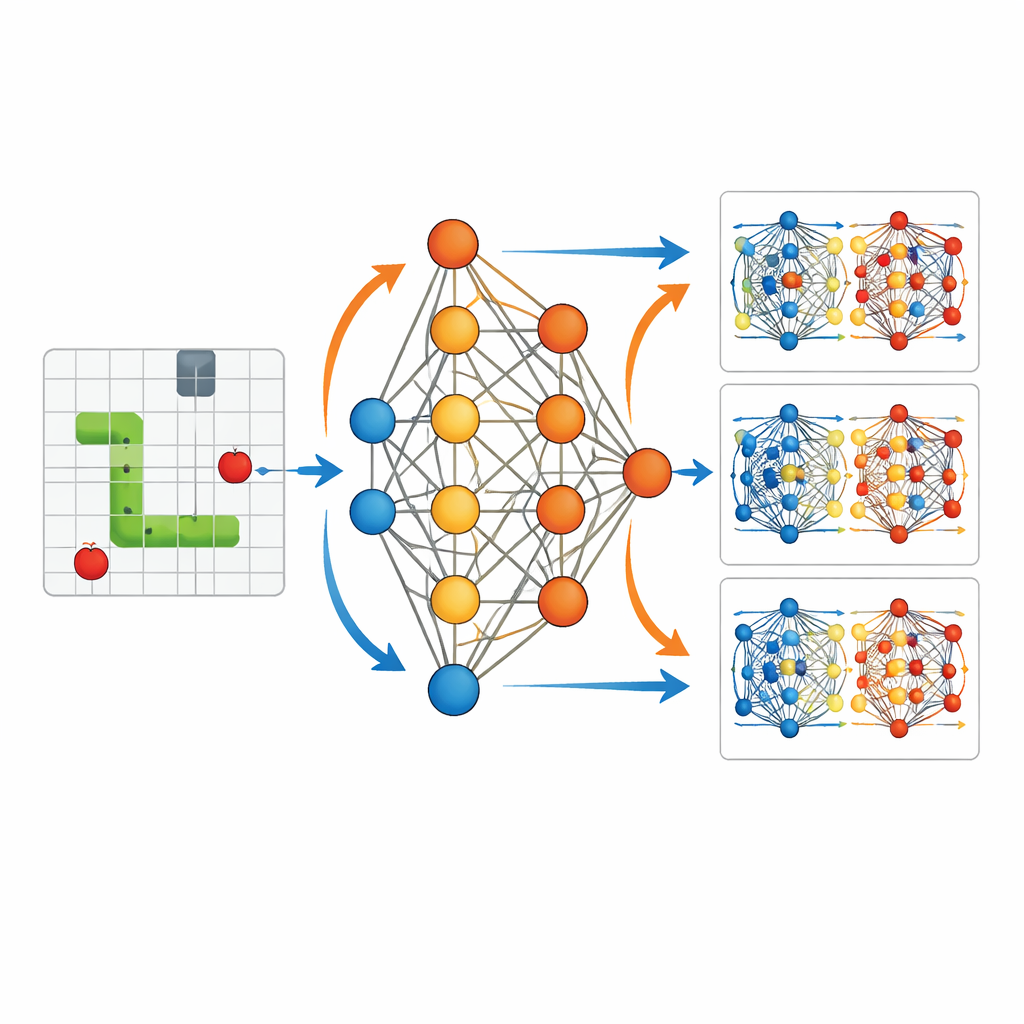
De la deambulación aleatoria al movimiento con propósito
El contraste entre agentes entrenados y no entrenados hace fácil ver el efecto de estas actualizaciones ocultas. Sin entrenamiento, la serpiente deambula cerca del punto de inicio, chocando con paredes o consigo misma sin una estrategia aparente. Tras el entrenamiento, la misma estructura de red genera trayectorias suaves y dirigidas que se orientan activamente hacia la comida evitando el peligro. Las visualizaciones de los cambios de parámetros muestran que las recompensas en momentos específicos fortalecen o debilitan selectivamente conexiones particulares en la red, organizando su comportamiento. Esto refleja cómo la información observacional en la asimilación de datos remodela gradualmente las condiciones iniciales del modelo para que los pronósticos sigan trayectorias más consistentes con la realidad.
Lo que realmente muestra el estudio
El trabajo no introduce un nuevo algoritmo de aprendizaje ni una nueva forma de pronosticar el tiempo. En cambio, ofrece una imagen didáctica y clara de un principio compartido: tanto el aprendizaje por refuerzo profundo como la asimilación variacional de datos ejecutan repetidamente un modelo hacia adelante, miden su rendimiento y luego envían esa información hacia atrás para mejorar un conjunto de cantidades ajustables. En Snake, esas cantidades son los pesos de la red neuronal que codifican una estrategia; en la predicción meteorológica, son los estados atmosféricos que initian un pronóstico. Al hacer visible el flujo inverso de información en un sistema pequeño y totalmente observable, el artículo da a los científicos atmosféricos una sensación más intuitiva de la dinámica del aprendizaje automático moderno y ayuda a los investigadores de IA a apreciar la larga historia de ideas similares en las geociencias.
Cita: Wang, KY. Visualising backward information propagation in deep reinforcement learning from a variational data assimilation perspective. Sci Rep 16, 11581 (2026). https://doi.org/10.1038/s41598-026-42086-x
Palabras clave: aprendizaje por refuerzo, asimilación de datos, redes neuronales, predicción meteorológica, optimización