Clear Sky Science · ar
تصوُّر انتشار المعلومات رجعياً في التعلم التعزيزي العميق من منظور الدمج البَياني التغايري
لماذا يهم هذا الأمر خارج علم الحاسوب
قد تبدو توقعات الطقس ونماذج المناخ والذكاء الاصطناعي القادر على لعب الألعاب عالماً مختلفاً، لكنها كلها تعتمد على محرك خفي مشترك: تعديل نموذج مراراً حتى يتطابق بشكل أفضل مع ما يحدث فعلاً. تفتح هذه الورقة ذلك الصندوق الأسود. باستخدام لعبة الثعبان البسيطة كحقل اختبار، يُظهر المؤلف — بصرياً وخطوة بخطوة — أن طريقة تحسين خوارزمية التعلم لأدائها تشبه تماماً الطريقة التي يصقل بها علماء الأرصاد توقعات الطقس باستخدام البيانات المرصودة. النتيجة هي جسر واضح وبديهي بين الذكاء الاصطناعي الحديث والأساليب التقليدية في علوم الغلاف الجوي.
عالمان يشتركان في نفس المحرك الخفي
في التنبؤ العددي للطقس، يستخدم الدمج البَياني التغايري لدمج نموذج فيزيائي للغلاف الجوي مع الملاحظات الواقعية. يقوم العلماء بتشغيل نموذج التنبؤ إلى الأمام عبر الزمن، ومقارنته بالقياسات، ثم يعيدون نشر معلومات تلك الفروقات إلى الوراء لتعديل شروط بداية النموذج. التعلم التعزيزي العميق، الذي يقود أنظمة تتعلم لعب الألعاب أو التحكم في الروبوتات، أيضاً يُشغّل نموذجاً إلى الأمام: يتخذ وكيل إجراءات، يتلقى مكافآت أو عقوبات، ثم يمرر المعلومات إلى الوراء عبر شبكة عصبية لتعديل معاييره الداخلية. تجادل الورقة بأنه تحت المصطلحات المختلفة، كلا العمليتين تقومان بنفس نوع العمل — تقليل مقياس واحد يقيس مدى أداء النظام عبر سلسلة كاملة من الأحداث.
لعبة بسيطة كمختبر نظيف
لجعْل هذا الارتباط ملموساً، تستخدم الدراسة إعداداً مبسّطاً: وكيل ذكاء اصطناعي يتعلم لعب لعبة الثعبان الكلاسيكية. يرى الوكيل وصفاً مدمجاً لبيئته — مكان الطعام والجدران وجسد الثعبان بالنسبة لرأسه — ويغذي هذه المعلومات المكوّنة من 11 بتاً إلى شبكة عصبية صغيرة بطبقة خفية واحدة. تخرج الشبكة ثلاث خيارات: الالتفاف لليسار، السير مباشرة، أو الالتفاف لليمين. كل مرة يأكل فيها الثعبان طعاماً، يحصل الوكيل على مكافأة إيجابية؛ وإذا اصطدم بجدار أو بجسده، يحصل على مكافأة سلبية وتنتهي اللعبة. والأهم أن المؤلف يسجل كل معلمة في هذه الشبكة — 3584 معلمة بالمجمل — عند كل خطوة تدريب، بحيث يمكن إعادة تشغيل عملية التعلم بأكملها وتفحصها بتفصيل.
مراقبة التعلم من الداخل
بفضل هذا السجل الكامل، تقوم الورقة بتصوير كيف تتغير "الأوزان" الداخلية للشبكة أثناء تعلم الثعبان. في البداية، تكون الأفعال شبه عشوائية، وتحديثات الأوزان متفرقة وصغيرة. على مدار ألعاب عديدة، ومع استكشاف الوكيل للشبكة وخوضه العديد من النجاحات والإخفاقات، تبدأ تلك التحديثات في تشكيل أنماط منظمة. تصبح مسارات الثعبان أطول وأكثر توجّهاً نحو الطعام. تُظهر الدراسة أن كل دفعة صغيرة من التعلم بعد حركة تشبه تصحيحاً قصير المدى: حيث تتدفق معلومات المكافآت الفورية إلى الوراء لتعديل المعاملات التي أنتجت تلك الحركة. بشكل دوري، يعيد النظام أيضاً استخدام تجارب لعبة سابقة، معيداً حساب مدى جودة أو سوء تلك الاختيارات القديمة تحت المعايير المحدثة. هذا يشبه كيف تقوم مراكز التنبؤ الجوي بتقريب خطي متكرر وإعادة تحسين حول توقع محدث في إطار الدمج البَياني التغايري رباعي الأبعاد.
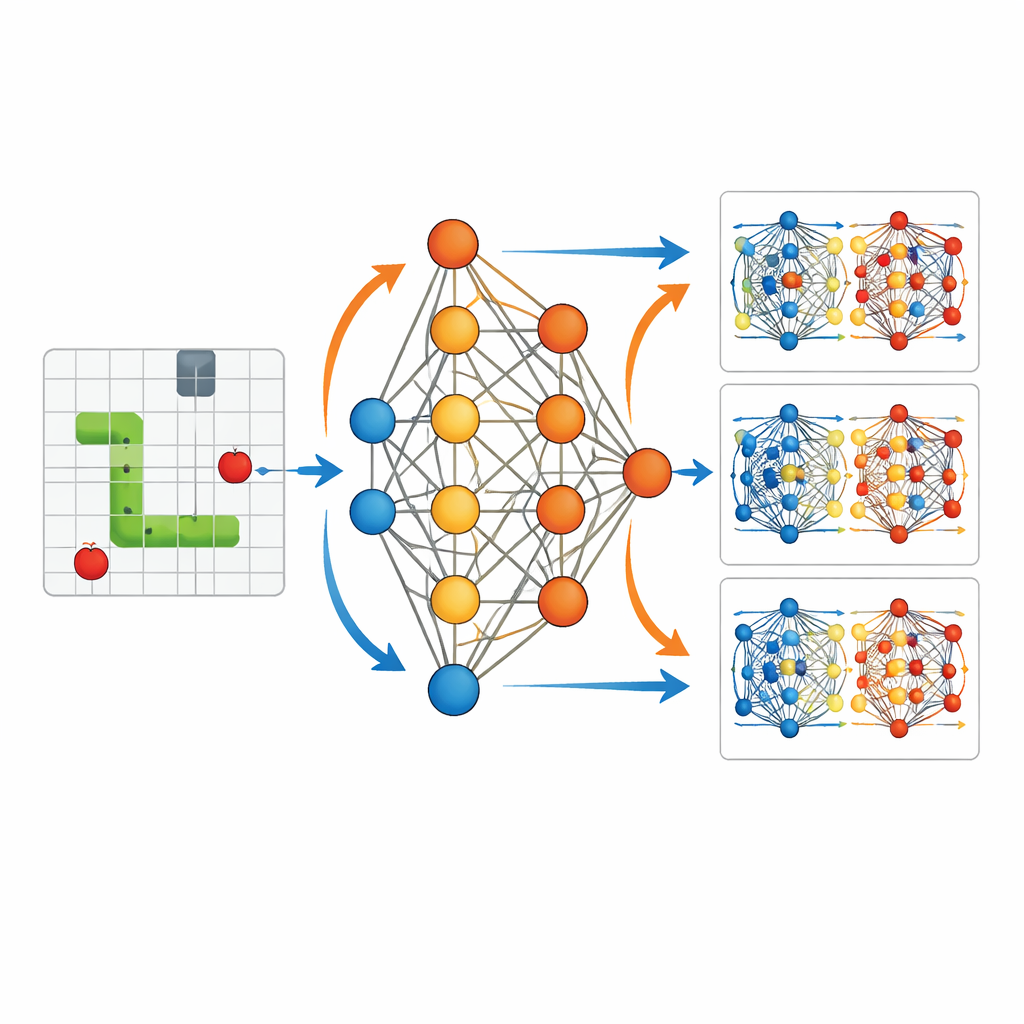
من التجوال العشوائي إلى الحركة الهادفة
التباين بين وكلاء غير مدرَّبين ووكلاء مدرَّبين يجعل أثر هذه التحديثات الخفية سهل الرصد. بدون تدريب، يتيه الثعبان قرب نقطة انطلاقه، يصطدم بالجدران أو بمخه بلا استراتيجية واضحة. بعد التدريب، ينتج نفس هيكل الشبكة مسارات سلسة وهادفة تتوجه بنشاط نحو الطعام وتتفادى الخطر. تُظهر التصويرات لتغيرات المعاملات أن المكافآت في أوقات محددة تقوّي أو تُضعف اتصالات معينة في الشبكة بشكل انتقائي، ما ينظم سلوكها. هذا يعكس كيف تعيد المعلومات المرصودة في الدمج البَياني تشكيل شروط البداية للنموذج تدريجياً بحيث تتبع التنبؤات مسارات أكثر اتساقاً مع الواقع.
ما الذي تُبرِزه الدراسة فعلاً
العمل لا يقدم خوارزمية تعلم جديدة ولا طريقة جديدة لتنبؤ الطقس. بل يقدم صورة واضحة وتعليمية لمبدأ مشترك: كلا من التعلم التعزيزي العميق والدمج البَياني التغايري يقومان مراراً بتشغيل نموذج إلى الأمام، وقياس مدى أدائه، ثم إرسال تلك المعلومات إلى الوراء لتحسين مجموعة من الكميات القابلة للتعديل. في لعبة الثعبان، تلك الكميات هي أوزان الشبكة العصبية التي تُشفّر استراتيجية؛ أما في تنبؤ الطقس، فهي حالات الغلاف الجوي التي تُغذي التوقع. بجعل تدفُّق المعلومات الرجعي مرئياً في نظام صغير ويمكن ملاحظته بالكامل، تمنح الورقة علماء الغلاف الجوي إحساساً أكثر بديهية بديناميكيات التعلم الآلي الحديثة وتساعد باحثي الذكاء الاصطناعي على تقدير التاريخ الطويل لأفكار مماثلة في علوم الأرض.
الاستشهاد: Wang, KY. Visualising backward information propagation in deep reinforcement learning from a variational data assimilation perspective. Sci Rep 16, 11581 (2026). https://doi.org/10.1038/s41598-026-42086-x
الكلمات المفتاحية: التعلم التعزيزي, الدمج البَياني, الشبكات العصبية, تنبؤ الطقس, التحسين