Clear Sky Science · tr
Bilgi izotopları kullanarak yapay zekâ üretimli içeriklerden yetkisiz eğitim verilerini denetleme
Günlük internet kullanıcıları için bunun önemi
Modern yapay zekâ sistemleri haberler, romanlar, kodlar ve sosyal medya paylaşımları gibi insan yapımı metinlerin büyük koleksiyonlarından öğrenir. Ancak bu materyallerin bir kısmı telif hakkıyla korunuyor veya son derece kişisel olabilir ve yapay zekâ şirketleri genellikle tam olarak ne kullandıklarını açıklamaz. Bu makale, siyah kutu bir yapay zekâ sisteminin yalnızca çıktıları kullanılarak sıradan kişiler, yayıncılar ve denetleyiciler tarafından kendi verilerini eğitmekte kullanıp kullanmadığını kontrol etmenin pratik bir yolunu tanıtıyor. Bu, güçlü sohbet botları çağında gizliliği ve fikri mülkiyeti koruma açısından potansiyel olarak oyun değiştirici olabilir.
Gizli eğitim verisi sorunu
Günümüzün büyük dil modelleri etkileyici yeteneklerini geniş miktarda yazılı materyal özümseyerek kazanır. Bu içeriğin çoğu kamu internetinden kazınır; burada sıkı lisanslarla korunuyor veya hassas bilgiler içerebilir. Ancak geleneksel veri sızıntılarından farklı olarak, yapay zekâ geliştiricileri ham veriyi yeniden dağıtmaz; bunun yerine veriyi model davranışına işlerler. Ticari sistemler yalnızca üretilmiş metni açığa çıkarır, dahili işleyişlerini veya eğitim kümelerini paylaşmaz. Belirli örneklerin eğitimde kullanılıp kullanmadığını tespit etmeye yönelik mevcut adli yöntemler çoğunlukla token olasılıkları gibi içsel istatistiklere dayanır; bu tür bilgiler GPT tarzı sohbet hizmetleri gibi servislerde mevcut değildir. Aynı zamanda, bu modeller pasajları kelimesi kelimesine kopyalamaktan kaçınacak şekilde ayarlanır, bu yüzden belgeniz ile modelin yanıtları arasındaki basit benzerlik kontrolleri güvenilir kanıt sağlamaya yeterince güçlü değildir.
Yeni bir fikir: bilgi izotopları
Yazarlar kimyadan bir kavram ödünç alıyor: izotoplar aynı elementin hafifçe farklı versiyonlarıdır ve reaksiyonlar boyunca izlenebilirler. Metinde, “anlamsal öğe” adlandırılmış bir varlık, bir fiil veya belirli bir kaynak kod satırı gibi ince taneli bir anlam parçasıdır. “Bilgi izotopu” ise aynı şeyi anlam olarak koruyan ama görünüş olarak farklı olan bağlama uygun alternatiftir: örneğin “New York”, “NYC” ve “the Big Apple”. Temel ampirik bulgu şudur: bir dil modeli eğitim sırasında özgün biçimi görmüşse, aynı bağlamda birden çok eşit derecede makul varyant arasından seçim yapması istendiğinde o kesin biçime güçlü bir eğilim geliştirir. Modelin daha önce hiç görmediği materyaller için bu eğilim çok daha zayıftır, çünkü doğrudan belleğe değil genel bilgiye dayanmak zorundadır.
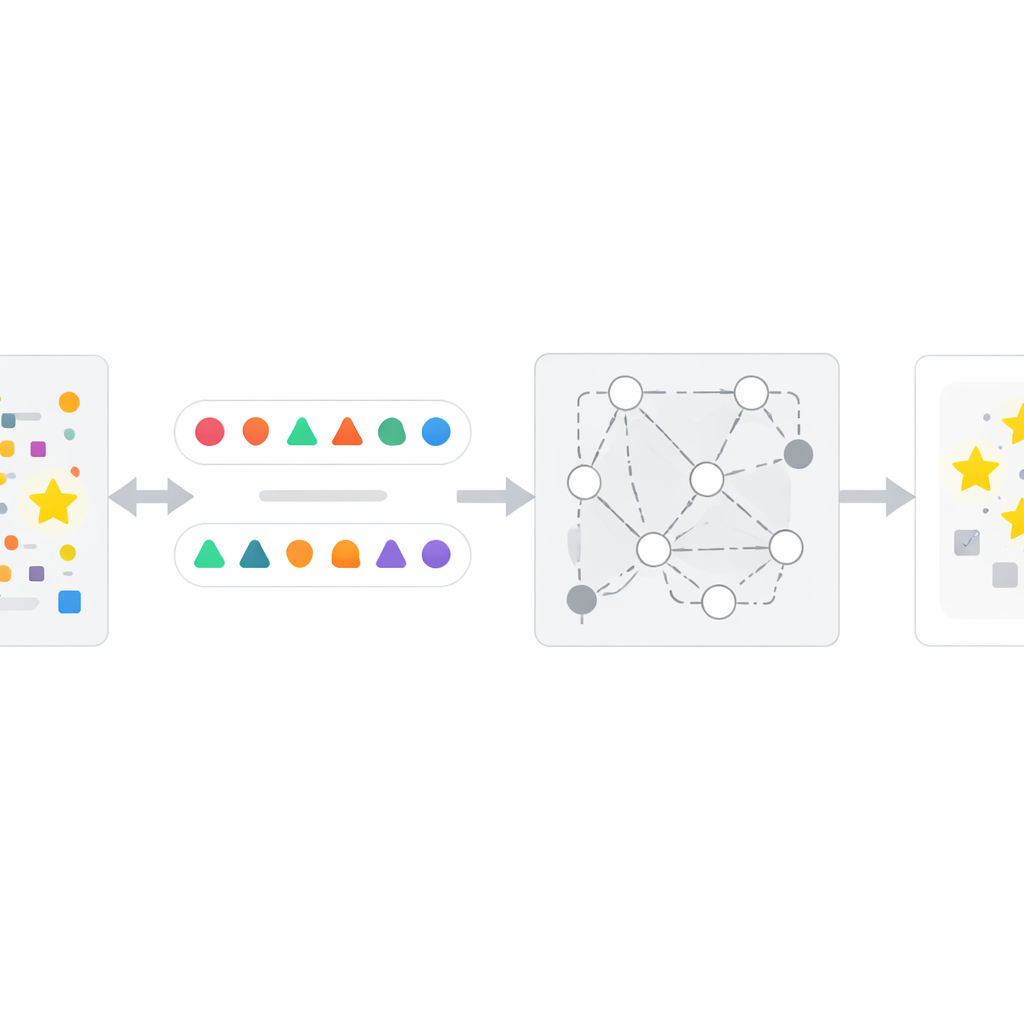
InfoTracer yöntemi nasıl çalışır
Bu içgörü üzerine inşa edilen yazarlar InfoTracer adlı dört adımlı bir çerçeve tasarlar. İlk olarak, şüpheli bir metni—örneğin bir haber makalesi, tıbbi kayıt, kitap pasajı veya kod dosyası—taranlar ve anlam öğelerine böler; özellikle ayırt edici bir bellek izi bırakma olasılığı en yüksek olan kelime türleri ve kod satırlarına odaklanır. İkinci olarak, seçilen her öğe için ayrı bir üretici model kullanarak çevreleyen pasajla doğal şekilde uyumlu birkaç bağlama duyarlı izotop oluşturur: farklı ifadeler veya kod varyantları. Üçüncü olarak, bu aday “prob”ları yalnızca bağlamdan hangisinin en iyi olduğunu kolayca söyleyemeyecek insan benzeri bir okuyucunun seçilemeyeceği durumda tutmak üzere filtreler; böylece hedef yapay zekânın gösterdiği güçlü eğilimin ortak akıldan ziyade eğitim maruziyetinden kaynaklanma olasılığı artar. Son olarak, InfoTracer orijinal öğeyi maskeleyen ve izotop kümesinden bir tamamlama seçmesini isteyen çoktan seçmeli istemlerle kara kutu yapay zekâyı tekrar tekrar sorgular. Yapay zekânın birçok prob boyunca ne sıklıkla özgün wording’i seçtiğini toplayarak, yöntem metnin büyük olasılıkla eğitim verisinin parçası olup olmadığını işaret eden genel bir aktivasyon skoru üretir.
Tekniği teste sokmak
Araştırmacılar InfoTracer’ı açık ve ticari dil modellerinin geniş bir seçkisi üzerinde değerlendirir ve eğitim örneklerini eğitim dışı olanlardan makul şekilde ayırabildikleri dikkatle hazırlanmış kıstaslar kullanır. Bilinen ön eğitim verilerine sahip açık kaynak LLaMA modellerinde, InfoTracer Wikipedia pasajlarının üyelerini üye olmayanlardan çok yüksek doğrulukla ayırt eder; bu, yalnızca kısa kesitler mevcut olduğunda bile geçerlidir. Aynı kaynaktan birden fazla pasaj birleştirildiğinde, performans genellikle kısa bir makale uzunluğundan az metin kullanılarak mükemmel ayrımlara hızla yaklaşır. Yöntem ayrıca hedef sistemi yaklaşıklamak için vekil modellere dayananlar da dahil olmak üzere çeşitli en son teknoloji rakipleri geride bırakır ve eğitim ile test verilerinin aynı genel stil ve konuları paylaştığı daha zorlu kurulumlarda da etkili kalır.
Dayanıklılık testleri, gerçek dünya modelleri ve uzun metinler
Gerçek dünya kötüye kullanımını taklit etmek için yazarlar InfoTracer’ı gizlilik açısından hassas tıbbi metinler, telifli kitap içerikleri ve kod depoları üzerinde ve GPT-3.5, GPT-4o, Claude, Gemini ve diğer API’ler gibi birkaç büyük ticari sistemde test eder. Model mimarisi veya eğitim korpusları hakkında hiçbir bilgi olmadan bile InfoTracer, bu alanlardan temsilî veri kümelerinin eğitimde kullanılıp kullanmadığını genellikle birkaç bin kelimeden elde edilen güçlü istatistiksel kanıtlarla güvenilir biçimde tespit eder. Çerçeve ayrıca saldırganların veriyi kısmen yeniden yazması veya seçici örneklemesi durumunda da sağlam kalır: ağır yeniden yazma sinyali zayıflatabilir, ancak daha fazla metin mevcut olduğunda yöntemin doğruluğu büyük ölçüde toparlanır. 21 Çin romanını kapsayan bir milyon kelimenin üzerindeki büyük ölçekli bir gösterimde, InfoTracer muhtemelen eğitime giren daha eski eserleri ve muhtemelen girmemiş olan son romanları net şekilde ayırır.
Bu durum veri hakları için ne anlama geliyor
Teknik olmayan bir bakışla, makale şunu gösterir: yapay zekâ sistemleri opak olsa bile davranışları eğitildikleri metinlerin ölçülebilir parmak izlerini taşır. Neredeyse özdeş alternatifler arasındaki tercihlerden zekice yararlanarak InfoTracer bu parmak izlerini bir modelin belirli kaynakları ezberlediğine dair mahkemede kullanılabilecek kanıta dönüştürür. Yöntem yapay zekâ sağlayıcılarının iş birliğini gerektirmez ve orijinal veriyi değiştirmez; bu da onu potansiyel kötüye kullanımı denetlemek isteyen yazarlar, kurumlar ve düzenleyiciler için uygun kılar. Mevcut deneyler metin odaklı olsa da yazarlar benzer fikirlerin ses, görüntü ve videoya da genişletilebileceğini savunur. Üretken yapay zekâ hassas alanlara genişledikçe, bu tür kara kutu denetim araçları uygulamada gizlilik ve telif hakkı kurallarının uygulanmasının temel taşlarından biri haline gelebilir.
Atıf: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Anahtar kelimeler: Yapay zekâ eğitim verisi denetimi, bilgi izotopları, veri gizliliği, telif hakkı ve yapay zekâ, kara kutu dil modelleri