Clear Sky Science · ja
情報アイソトープを用いたAI生成コンテンツからの無断学習データの監査
なぜ日常のインターネット利用者に関係するのか
現代のAIシステムは、ニュース記事、小説、コード、さらにはソーシャルメディア投稿など、人間が作成した膨大なテキスト群から学習します。しかし、それらの多くは著作権で保護されていたり極めて個人的な内容を含んでいたりし、AI企業が正確に何を使ったかを明かすことは稀です。本稿は、一般の人々、出版社、規制当局がブラックボックスのAIシステムが自分たちのデータで学習したかどうかを、その出力だけを使って実用的に確認する方法を提示します。これにより、強力なチャットボットの時代におけるプライバシーと知的財産の保護にとって画期的な手段となり得ます。
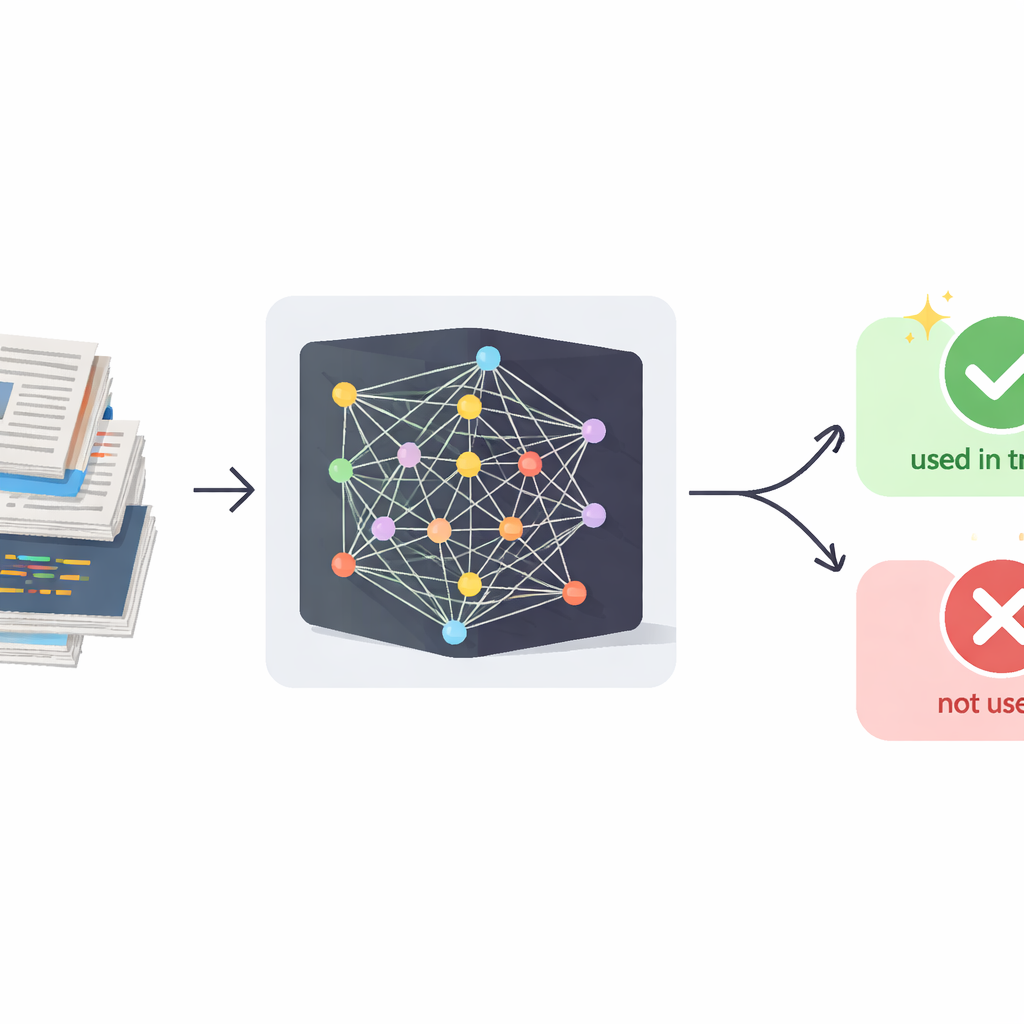
隠された学習データの問題点
今日の大規模言語モデルは、膨大な書き言葉を吸収することで高い能力を獲得します。これらの多くは公開インターネットからスクレイピングされたもので、厳しいライセンスの対象だったり機微な情報を含んでいたりします。従来のデータ漏洩とは異なり、AI開発者は生データを再配布するのではなく、その内容をモデルの挙動に焼き付けます。商用システムは生成されたテキストのみを公開し、内部の動作や学習セットは明かしません。特定の例が学習に使われたかを検出する既存の鑑定技術は、トークン確率のような内部統計に依存することが多く、GPTスタイルのチャットボットでは利用できません。同時に、こうしたモデルは文章を逐語的にコピーすることを避けるよう調整されているため、文書とモデルの応答との単純な類似性チェックは信頼できる証拠としては弱すぎます。
新しい発想:情報アイソトープ
著者らは化学から概念を借用します。化学ではアイソトープが同一元素のわずかに異なる版として反応中に追跡可能です。テキストにおける「意味要素」は、固有表現、動詞、特定のコード行など、意味の細かな区切りを指します。「情報アイソトープ」は、同じ意味を保ちながら見た目が異なる文脈に適した代替表現です。例えば「New York」「NYC」「the Big Apple」が挙げられます。重要な実証的発見は、もし言語モデルが学習中に元の表現を見ていたなら、同じ文脈で複数の同等に妥当な変種から選ばせるときにその正確な形式を強く好むようになるという点です。一方で、モデルが学習で見ていない素材については、この好みははるかに弱く、直接的な記憶ではなく一般的な知識に頼るしかないためです。
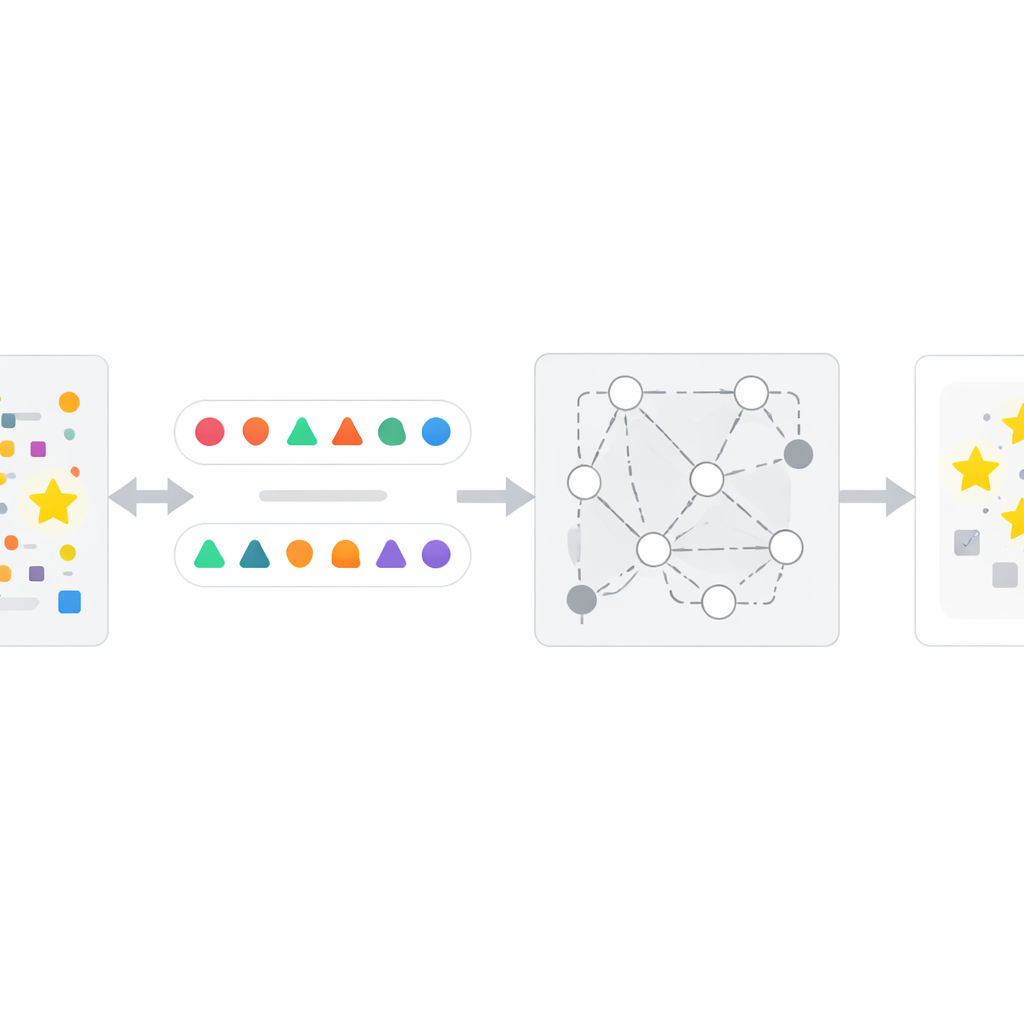
InfoTracer法の仕組み
この洞察に基づき、著者らはInfoTracerと名付けた4段階の枠組みを設計します。第一に、疑わしいテキスト(ニュース記事、医療記録、書籍の一節、コードファイルなど)を走査し、意味要素に分割します。特に記憶の痕跡を残しやすい品詞やコード行に注目します。第二に、選択した各要素について、別の生成モデルを用いて文脈に合った複数のアイソトープ(異なる言い回しやコードのバリアント)を作成します。第三に、これらの候補「プローブ」を、文脈だけでは人間の読み手がどれが最適か容易に判別できないものに絞り込みます。これにより、ターゲットAIが示す強い選好は常識ではなく学習露出によるものと推定されやすくなります。最後に、InfoTracerは元の要素をマスクした多肢選択プロンプトでブラックボックスAIを繰り返し照会し、アイソトープ集合からの補完を選ばせます。多数のプローブにわたりAIが元の表現を選ぶ頻度を集計することで、テキストが学習データの一部であった可能性を示す総合的な活性化スコアを算出します。
手法の検証
研究者らは、トレーニング例と非トレーニング例を合理的に分離できるよう慎重に設計したベンチマークを用い、オープンおよび商用の多様な言語モデルでInfoTracerを評価します。既知の事前学習データを持つオープンソースのLLaMAモデル上では、InfoTracerはメンバー(学習に使われた)と非メンバーのWikipediaパッセージを非常に高い精度で区別します。短い抜粋のみでも有効であり、同一ソースからの複数のパッセージを組み合わせると、しばしば短い論文の長さにも満たないテキスト量でほぼ完全に分離できます。本法は、ターゲットシステムを近似する代替モデルに依存する手法を含む最先端の競合法を上回り、学習データとテストデータが同じ様式や話題を共有するより困難な設定でも有効性を維持します。
ストレステスト、実用モデル、長文への適用
実世界での悪用を模倣するため、著者らはInfoTracerをプライバシーに敏感な医療テキストや著作権のある書籍の内容、コードリポジトリ、そしてGPT-3.5、GPT-4o、Claude、Geminiなど複数の主要商用システムで試験します。モデルのアーキテクチャや学習コーパスについて何も知らなくても、InfoTracerはこれらのドメインからの代表的なデータセットが学習に使われた可能性をしばしば数千語程度の情報から強い統計的証拠で検出します。攻撃者が学習データを部分的に書き換えたり選択的にサンプリングした場合でも枠組みは頑健で、重い書き換えで信号が弱まってもテキスト量が増えれば精度は大部分回復します。21の中国小説にまたがる100万語以上の大規模実演では、InfoTracerは学習に入り込んだ可能性の高い古い作品と、学習に含まれていないと考えられる新しい小説を明瞭に分離しました。
データ権利にとっての意義
技術的でない観点から見ると、この論文はAIシステムが不透明であっても、その挙動には学習に用いられたテキストの測定可能な指紋が残ることを示しています。ほとんど同一に近い選択肢間の好みを巧みに利用することで、InfoTracerはこれらの指紋を法廷で使える証拠へと変え、モデルが特定の情報源を記憶していることを示せます。この方法はAI提供者の協力を必要とせず、元データを改変もしないため、著者、機関、規制当局が潜在的な不正利用を監査するのに適しています。現行の実験は主にテキストに焦点を当てていますが、著者らは同様の考え方が音声、画像、動画にも拡張可能だと論じています。生成AIが機微な領域に拡大し続ける中、こうしたブラックボックス監査ツールは実務におけるプライバシーと著作権規制の施行の基盤になり得ます。
引用: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
キーワード: AIの学習データ監査, 情報アイソトープ, データプライバシー, 著作権とAI, ブラックボックス言語モデル