Clear Sky Science · he
בדיקת נתוני אימון לא מורשים מתוך תוכן שנוצר על ידי בינה מלאכותית באמצעות איזוטופים מידעיים
מדוע זה חשוב למשתמשי האינטרנט היומיומיים
מערכות בינה מלאכותית מודרניות לומדות ממאגרי טקסט עצומים שנוצרו על ידי בני אדם — חדשות, רומנים, קוד, ואפילו פוסטים ברשתות חברתיות. אך רבים מהחומרים הללו מוגנים בזכויות יוצרים או מכילים מידע רגיש אישי, וחברות ה-AI כמעט ואינן מחשיפות במדויק מהן השתמשו. מאמר זה מציג שיטה מעשית לאנשים פרטיים, למו“לים ולרגולטורים לבחון האם מערכת AI בתיבת שחור הוכשרה על הנתונים שלהם, תוך שימוש אך ורק ביציאות המתקבלות ממנה. בכך זה עלול לשנות את כללי המשחק בהגנת פרטיות וקניין רוחני בעידן הצ׳אבט-בוטים החזקים.
בעיית נתוני האימון הנסתרים
מודלים גדולים של שפה מפתחים את כישוריהם המרשימים על ידי ספיגת כמויות עצומות של חומר כתוב. חלק גדול מהתוכן נאסף מהאינטרנט הציבורי, שם הוא עשוי להיות כפוף לרישיונות מחמירים או להכיל מידע רגיש. בניגוד לדליפות נתונים מסורתיות, מפתחי ה-AI אינם מפיצים מחדש את הנתונים הגולמיים; הם משזפים אותם להתנהגות המודל. מערכות מסחריות מציגות טקסטים שנוצרו בלבד, ולא את מבנה הפנימי או מערכי האימון. טכניקות פורנזיות קיימות לזיהוי שימוש בדוגמאות ספציפיות לתוך האימון מסתמכות לרוב על סטטיסטיקות פנימיות כמו הסתברויות טוקנים, שאינן זמינות בשירותים בסגנון צ׳אט של GPT. במקביל, המודלים מכוונים להימנע מהעתקה מילה במילה, ולכן בדיקות דמיון פשוטות בין המסמך שלך לתשובות המודל חלשות מדי כדי להוות ראיה מהימנה.
רעיון חדש: איזוטופים מידעיים
המחברים שואבים מושג מכימיה, שבה איזוטופים הם גרסאות מעט שונות של אותו יסוד שאפשר לעקוב אחריהן בתגובות. בטקסט, "יסוד סמנטי" הוא חתיכת משמעות דקה — כגון ישות ממוסגרת, פועל או שורת קוד ספציפית. "איזוטופ מידע" הוא אלטרנטיבה המתאימה להקשר שמשמעותה זהה אך נראית שונה: למשל, "ניו יורק", "NYC" ו"העיר הגדולה". הממצא האמפירי המרכזי הוא שאם מודל שפה ראה את הניסוח המקורי במהלך האימון, הוא מפתח העדפה חזקה לנוסח המדויק הזה כאשר מתבקשים לבחור מבין מספר גרסאות שוות-מכובד בהקשר דומה. בחומרים שהמודל לא נחשף אליהם באימון, ההעדפה הזאת חלשה בהרבה, כי המודל יכול להישען רק על ידע כללי במקום זיכרון ישיר.
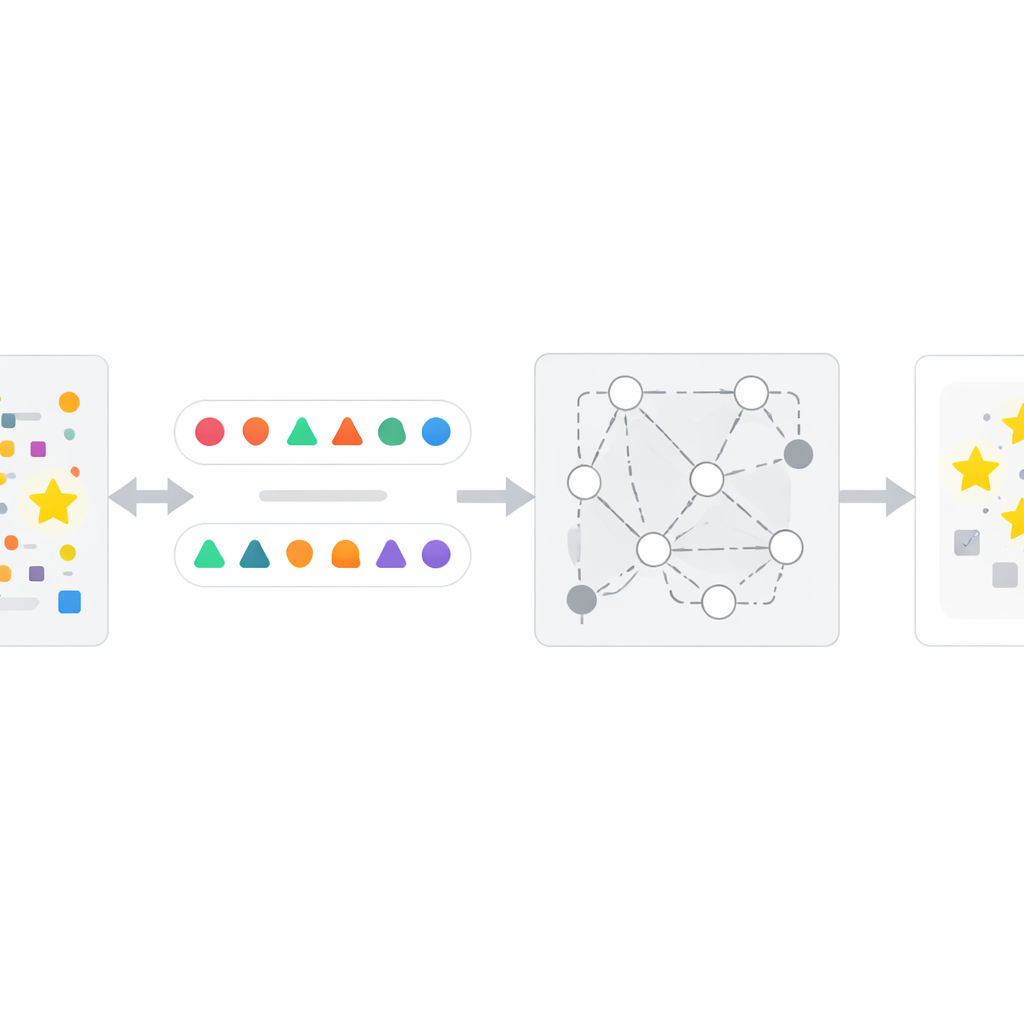
איך שיטת InfoTracer עובדת
בהסתמך על התובנה הזו, המחברים מתכננים מסגרת בת ארבעה שלבים שנקראת InfoTracer. ראשית, היא סורקת טקסט חשוד — כגון כתבת חדשות, תיק רפואי, קטע מספר או קובץ קוד — ומפרקת אותו ליסודות סמנטיים, תוך התמקדות בחלקי הדיבר ושורות הקוד שבסבירות גבוהה ביותר להשאיר טביעת זיכרון מובחנת. שנית, עבור כל יסוד נבחר היא משתמשת במודל גנרטיבי נפרד ליצירת מספר איזוטופים מותאמי-הקשר: ניסוחים או ואריאציות קוד שונות שעדיין משתלבות באופן טבעי בקטע. שלישית, היא מסננת את המועמדים הללו לשמירה רק על אותם "חיישנים" שבהם קורא אנושי לא יכול בקלות לקבוע איזו אופציה היא הטובה ביותר מההקשר בלבד, ובכך מבטיחה שכל העדפה חזקה שמפגין ה-AI היעד נובעת סביר להניח מחשיפה באימון ולא מהיגיון פשוט. לבסוף, InfoTracer שואלת שוב ושוב את ה-AI בתיבת השחור עם קבצי בחירה מרובה שמסתירים את היסוד המקורי ומבקשים ממנו לבחור השלמה מתוך קבוצת האיזוטופים. על ידי צבירת תדירות בחירת הניסוח המקורי לאורך חיישנים רבים, השיטה מפיקה ציון הפעלה כולל שמצביע האם סביר שהטקסט היה חלק מנתוני האימון.
בדיקת הטכניקה
החוקרים מעריכים את InfoTracer על מבחר רחב של מודלים פתוחים ומסחריים, באמצעות בוחנים שנבנו בקפידה שבהם ניתן בהגיון להפריד דוגמאות אימון מדוגמאות שאינן אימון. על מודלים פתוחים כמו LLaMA עם נתוני טריינינג ידועים, InfoTracer מבחינה בין קטעי ויקיפדיה שהם חברים של ערכת האימון לבין קטעים שאינם חברים בדיוק גבוה מאוד, אפילו כאשר זמינים רק קטעים קצרים. כאשר משלבים מספר קטעים מאותה מקור, הביצועים מתקרבים במהירות להפרדה מושלמת, לעתים תוך שימוש בפחות מאורך של מאמר קצר. השיטה גם מתעלה על מגוון מתחרים מתקדמים, כולל אלה התלויים במודלים חיצוניים להערכה מקורבת של המערכת היעד, ונשארת יעילה בסביבות תובעניות יותר שבהן נתוני האימון והמבחן חולקים את אותו סגנון ונושאים כלליים.
מבחני עומס, מודלים מהעולם האמיתי וטקסטים ארוכים
כדי לדמות שימוש לרעה בעולם האמיתי, המחברים בוחנים את InfoTracer בטקסטים רפואיים רגישים לפרטיות ותכנים מספרות המוגנת בזכויות יוצרים, וכן במאגרים של קוד, ובכמה מערכות מסחריות מרכזיות כגון GPT-3.5, GPT-4o, Claude, Gemini וממשקי API אחרים. גם ללא ידע על ארכיטקטורת המודל או הקורפוסים שבהם הוא אומן, InfoTracer מזהה באמינות האם מערכי נתונים מייצגים מהתחומים הללו סבירים שנמצאו בשימוש באימון, לעתים עם ראיות סטטיסטיות חזקות מתוך כמה אלפי מילים בלבד. המסגרת גם מראה עמידות כאשר תוקפים משנים חלקית או בוחרים מדגמית נתוני אימון: בעוד שעיבוד חוזר כבד יכול להחליש את האות, הדיוק של השיטה בדרך כלל מתאושש כשיוצע יותר טקסט. בהדגמה בהיקף גדול עם למעלה ממיליון מילים המתפרסות על 21 רומנים סיניים, InfoTracer מפרידה באופן נקי בין יצירות ישנות שסביר שנכנסו לאימון לבין רומנים עדכניים שסביר שלא.
מה משמעות הדבר לזכויות על נתונים
מנקודת מבט לא-טכנית, המאמר מראה שגם כאשר מערכות AI אטומות, התנהגותן עדיין נושאת טביעות אצבע מדידות של הטקסטים עליהן הוכשרו. באמצעות ניצול חכם של העדפות בין אלטרנטיבות כמעט זהות, InfoTracer הופכת את טביעות האצבע הללו לראיה מוכנה לבית משפט שהמודל זכר מקורות מסוימים. השיטה אינה דורשת שיתוף פעולה מספקי ה-AI, ואינה משנה את הנתונים המקוריים, מה שהופך אותה להתאמה למחברים, למוסדות ולרגולטורים השואפים לבצע ביקורת על שימוש בלתי-חוקי אפשרי. בעוד שניסויים נוכחיים מתמקדים בטקסט, המחברים טוענים שרעיונות דומים עשויים להתרחב לקול, תמונות ווידאו. ככל שה-AI הגנרטיבי מתרחב לתחומים רגישים, כלי ביקורת בתיבת שחור כאלה עלולים להפוך לאבן יסוד באכיפת כללי פרטיות וזכויות יוצרים בפועל.
ציטוט: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
מילות מפתח: אימות נתוני אימון בבינה מלאכותית, איזוטופים מידעיים, פרטיות נתונים, זכויות יוצרים ובינה מלאכותית, מודלי שפה בתיבת שחור