Clear Sky Science · it
Verifica di dati di addestramento non autorizzati derivati da contenuti generati dall’IA usando isotopi informativi
Perché questo conta per gli utenti di internet di tutti i giorni
I sistemi di IA moderni apprendono da enormi raccolte di testi creati da persone — articoli di notizie, romanzi, codice, perfino post sui social media. Molti di questi materiali sono però coperti da diritti d’autore o contengono informazioni sensibili, e le aziende che sviluppano IA raramente dichiarano esattamente cosa hanno usato. Questo articolo introduce un metodo pratico che consente a persone comuni, editori e autorità di verificare se un sistema IA black-box è stato addestrato sui loro dati, utilizzando soltanto i suoi output. Ciò lo rende potenzialmente rivoluzionario per la tutela della privacy e della proprietà intellettuale nell’era dei potenti chatbot.
Il problema dei dati di addestramento nascosti
I grandi modelli linguistici odierni acquisiscono le loro abilità impressionanti assorbendo una quantità enorme di materiale scritto. Gran parte di questi contenuti viene raccolta dal web pubblico, dove può essere soggetta a licenze restrittive o contenere informazioni sensibili. Diversamente dalle violazioni di dati tradizionali, però, gli sviluppatori di IA non ridistribuiscono i dati grezzi; li incorporano invece nel comportamento del modello. I sistemi commerciali espongono quindi solo il testo generato, non il funzionamento interno o i set di addestramento. Le tecniche forensi esistenti per rilevare se esempi specifici sono stati usati in addestramento si basano in gran parte su statistiche interne come le probabilità dei token, che non sono disponibili per servizi tipo chatbot GPT. Allo stesso tempo, questi modelli sono tarati per evitare di copiare brani parola per parola, quindi semplici controlli di similarità tra il tuo documento e le risposte del modello sono troppo deboli per costituire prova affidabile.
Un’idea nuova: gli isotopi informativi
Gli autori prendono in prestito un concetto dalla chimica, dove gli isotopi sono versioni leggermente diverse dello stesso elemento che possono essere tracciate attraverso le reazioni. Nel testo, un “elemento semantico” è un frammento fine di significato — come un’entità nominata, un verbo o una riga specifica di codice sorgente. Un “isotopo informativo” è un’alternativa contestualmente appropriata che significa la stessa cosa ma appare diversa: per esempio, “New York”, “NYC” e “the Big Apple”. La principale osservazione empirica è che se un modello linguistico ha visto la formulazione originale durante l’addestramento, sviluppa una forte preferenza per quella stessa forma quando è chiamato a scegliere tra più varianti altrettanto ragionevoli nello stesso contesto. Per materiale che il modello non ha mai incontrato in addestramento, questa preferenza è molto più debole, perché può fare affidamento solo sulla conoscenza generale anziché su una memoria diretta.
Come funziona il metodo InfoTracer
Sulla base di questa intuizione, gli autori progettano un quadro in quattro fasi chiamato InfoTracer. Prima, analizza un testo sospetto — come un articolo di giornale, una cartella clinica, un brano di libro o un file di codice — e lo suddivide in elementi semantici, concentrandosi su parti del discorso e righe di codice più propense a lasciare una traccia mnemonica distintiva. Secondo, per ciascun elemento scelto utilizza un modello generativo separato per creare diversi isotopi contestuali: riformulazioni o varianti di codice che si integrano naturalmente nel passaggio circostante. Terzo, filtra questi candidati “sondaggi” per mantenere solo quelli in cui un lettore umano non potrebbe facilmente determinare quale opzione sia la migliore soltanto dal contesto, assicurando che qualsiasi forte preferenza mostrata dall’IA target sia probabilmente dovuta all’esposizione in addestramento più che al buon senso. Infine, InfoTracer interroga ripetutamente l’IA black-box con prompt a scelta multipla che mascherano l’elemento originale e le chiedono di scegliere una completamento dall’insieme di isotopi. Aggregando la frequenza con cui l’IA sceglie la formulazione originale attraverso molti sondaggi, il metodo produce un punteggio di attivazione complessivo che segnala se il testo è probabilmente parte dei dati di addestramento.
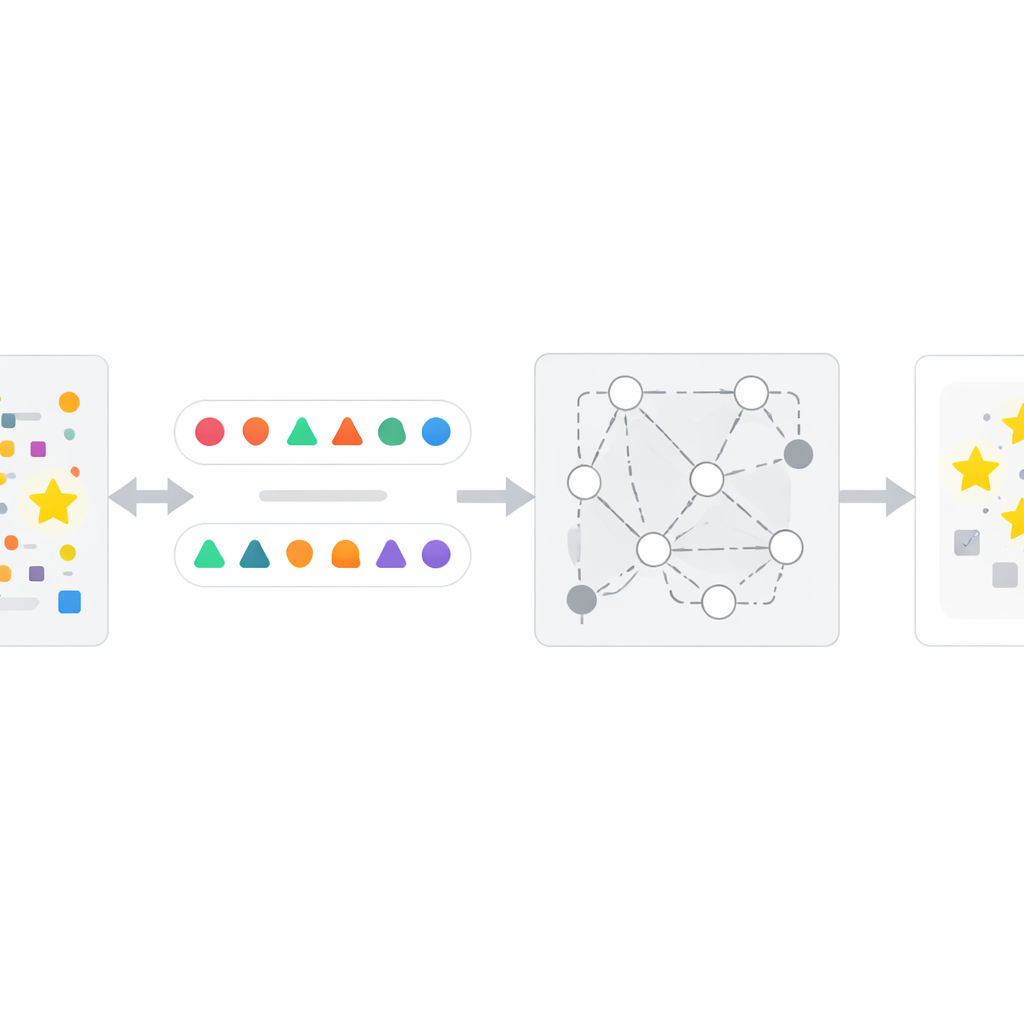
Mettere la tecnica alla prova
I ricercatori valutano InfoTracer su un’ampia selezione di modelli linguistici open e commerciali, usando benchmark costruiti con cura in cui è possibile separare ragionevolmente esempi di addestramento da quelli non usati. Su modelli LLaMA open-source con dati di preaddestramento noti, InfoTracer distingue con altissima precisione i passaggi di Wikipedia membri dai non membri, anche quando sono disponibili solo brevi estratti. Quando si combinano più passaggi dalla stessa fonte, le prestazioni si avvicinano rapidamente a una separazione perfetta, spesso usando meno della lunghezza di un breve articolo. Il metodo supera inoltre una serie di concorrenti all’avanguardia, inclusi quelli che dipendono da modelli surrogati per approssimare il sistema target, e rimane efficace in scenari più impegnativi in cui dati di addestramento e test condividono lo stesso stile e argomenti.
Stress test, modelli del mondo reale e testi lunghi
Per simulare abusi reali, gli autori testano InfoTracer su testi medici sensibili alla privacy e contenuti di libri protetti da copyright, così come su repository di codice, e su diversi grandi sistemi commerciali come GPT-3.5, GPT-4o, Claude, Gemini e altre API. Anche senza alcuna conoscenza dell’architettura del modello o dei corpora di addestramento, InfoTracer rileva in modo affidabile se dataset rappresentativi di questi domini sono stati probabilmente usati per l’addestramento, spesso con forte evidenza statistica da poche migliaia di parole. Il quadro si dimostra robusto anche quando gli aggressori riscrivono parzialmente o campionano selettivamente i dati di addestramento: mentre riscritture massicce possono indebolire il segnale, l’accuratezza del metodo si recupera in gran parte quando è disponibile più testo. In una dimostrazione su larga scala con oltre un milione di parole che coprono 21 romanzi cinesi, InfoTracer separa nettamente opere più vecchie plausibilmente entrate nell’addestramento da romanzi recenti che probabilmente non lo sono.
Cosa significa questo per i diritti sui dati
Da una prospettiva non tecnica, l’articolo mostra che anche quando i sistemi di IA sono opachi, il loro comportamento porta comunque impronte misurabili dei testi su cui sono stati addestrati. Sfruttando astutamente le preferenze tra alternative quasi identiche, InfoTracer trasforma queste impronte in prove utilizzabili in tribunale che un modello ha memorizzato fonti specifiche. Il metodo non richiede la cooperazione dei fornitori di IA, né modifica i dati originali, rendendolo adatto ad autori, istituzioni e regolatori che vogliano verificare un potenziale uso improprio. Sebbene gli esperimenti attuali si concentrino sul testo, gli autori sostengono che idee simili potrebbero estendersi ad audio, immagini e video. Man mano che l’IA generativa si espande in domini sensibili, strumenti di verifica black-box come questo potrebbero diventare un pilastro dell’applicazione pratica delle regole su privacy e copyright.
Citazione: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Parole chiave: verifica dei dati di addestramento IA, isotopi informativi, privacy dei dati, copyright e IA, modelli linguistici black-box