Clear Sky Science · fr
Auditer l'utilisation non autorisée de données d'entraînement issues de contenus générés par l'IA à l'aide d'isotopes d'information
Pourquoi cela compte pour les internautes
Les systèmes d'IA modernes apprennent à partir d'immenses collections de textes créés par des humains — articles de presse, romans, code, voire publications sur les réseaux sociaux. Mais nombre de ces contenus sont protégés par le droit d'auteur ou contiennent des informations très personnelles, et les entreprises d'IA révèlent rarement précisément ce qu'elles ont utilisé. Cet article présente une méthode réalisable pour que n'importe qui — particuliers, éditeurs ou régulateurs — puisse vérifier si un système d'IA en boîte noire a été entraîné sur leurs données, en n'utilisant que ses sorties. Cela pourrait changer la donne pour la protection de la vie privée et de la propriété intellectuelle à l'ère des chatbots puissants.
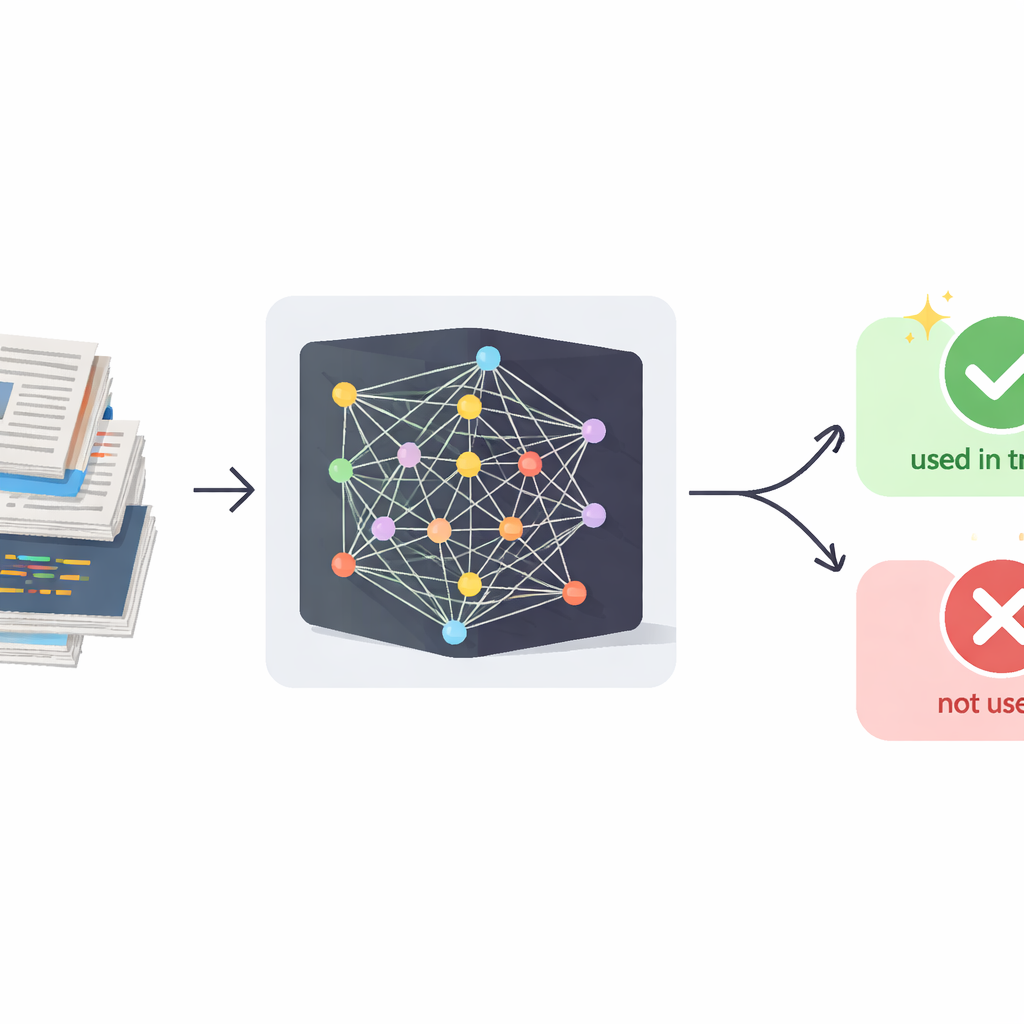
Le problème des données d'entraînement cachées
Les grands modèles de langage d'aujourd'hui acquièrent leurs compétences impressionnantes en absorbant d'énormes quantités de textes. Une grande partie de ce contenu est récupérée sur l'internet public, où il peut être soumis à des licences strictes ou contenir des informations sensibles. Contrairement aux fuites de données classiques, les développeurs d'IA ne redistribuent pas les données brutes ; ils les intègrent plutôt au comportement du modèle. Les systèmes commerciaux exposent alors uniquement du texte généré, et non leurs mécanismes internes ou leurs jeux d'entraînement. Les techniques médico-légales existantes pour détecter si des exemples spécifiques ont servi à l'entraînement reposent principalement sur des statistiques internes comme les probabilités de tokens, qui ne sont pas accessibles pour des services de type chatbot GPT. Par ailleurs, ces modèles sont conçus pour éviter de recopier des passages mot pour mot, si bien que de simples vérifications de similarité entre votre document et les réponses du modèle sont trop faibles pour constituer des preuves fiables.
Une nouvelle idée : les isotopes d'information
Les auteurs empruntent un concept à la chimie, où les isotopes sont des variantes légèrement différentes d'un même élément traçables au cours de réactions. Dans le texte, un « élément sémantique » est une unité fine de sens — comme une entité nommée, un verbe ou une ligne précise de code source. Un « isotope d'information » est une alternative adaptée au contexte qui signifie la même chose mais a une apparence différente : par exemple « New York », « NYC » et « the Big Apple ». La constatation empirique clé est que si un modèle de langage a vu la formulation originale pendant l'entraînement, il développe une forte préférence pour cette forme exacte lorsqu'on lui demande de choisir parmi plusieurs variantes également plausibles dans le même contexte. Pour un contenu que le modèle n'a jamais vu, cette préférence est beaucoup plus faible, car il ne peut s'appuyer que sur des connaissances générales plutôt que sur une mémoire directe.
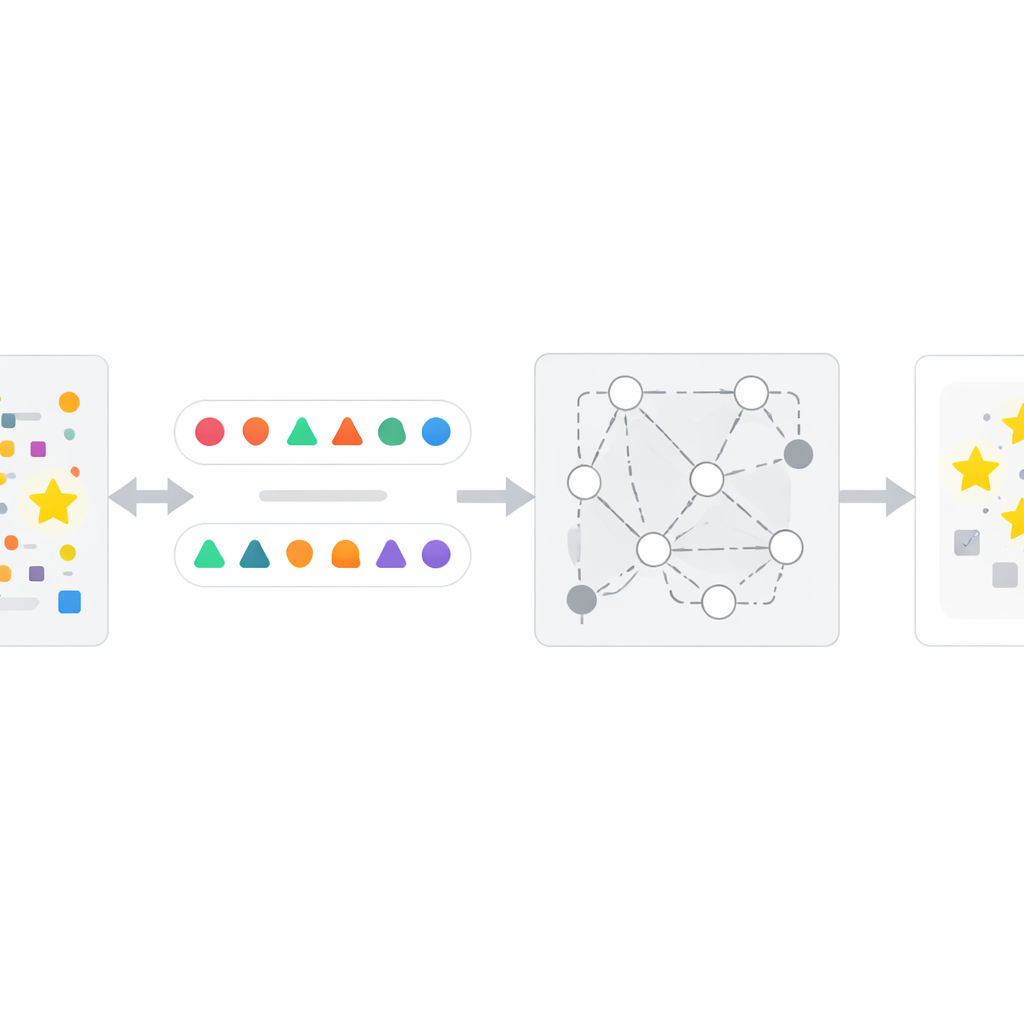
Comment fonctionne la méthode InfoTracer
S'appuyant sur cette observation, les auteurs conçoivent un cadre en quatre étapes appelé InfoTracer. D'abord, il analyse un texte suspect — par exemple un article de presse, un dossier médical, un extrait de livre ou un fichier de code — et le découpe en éléments sémantiques, en se concentrant sur les parties du discours et les lignes de code les plus susceptibles de laisser une trace mémorielle distinctive. Ensuite, pour chaque élément choisi, il utilise un modèle génératif distinct pour créer plusieurs isotopes adaptés au contexte : différentes formulations ou variantes de code qui s'insèrent naturellement dans le passage environnant. Troisièmement, il filtre ces « sondes » candidates pour ne retenir que celles pour lesquelles un lecteur humain ne pourrait pas facilement déterminer quelle option est la meilleure à partir du contexte seul, garantissant que toute forte préférence affichée par l'IA cible est vraisemblablement due à une exposition lors de l'entraînement plutôt qu'au sens commun. Enfin, InfoTracer interroge de manière répétée l'IA boîte noire avec des invites à choix multiple qui masquent l'élément original et lui demandent de choisir une complétion parmi l'ensemble d'isotopes. En agrégeant la fréquence à laquelle l'IA sélectionne la formulation originale sur de nombreuses sondes, la méthode produit un score d'activation global qui indique si le texte faisait probablement partie des données d'entraînement.
Mettre la technique à l'épreuve
Les chercheurs évaluent InfoTracer sur une large sélection de modèles de langage open source et commerciaux, en utilisant des bancs d'essai soigneusement construits où ils peuvent raisonnablement séparer exemples d'entraînement et non-exemples. Sur des modèles LLaMA open source avec des données de préentraînement connues, InfoTracer distingue avec une très grande précision les passages Wikipedia membres des non-membres, même lorsque seuls de courts extraits sont disponibles. Lorsque plusieurs passages d'une même source sont combinés, la performance approche rapidement d'une séparation parfaite, souvent avec moins de texte que la longueur d'un court article. La méthode surpasse également une gamme de concurrents de pointe, y compris ceux qui dépendent de modèles substituts pour approximer le système cible, et reste efficace dans des scénarios plus exigeants où les données d'entraînement et de test partagent le même style et les mêmes thèmes.
Tests de résistance, modèles réels et textes longs
Pour simuler des abus réels, les auteurs testent InfoTracer sur des textes médicaux sensibles et du contenu de livres protégés par le droit d'auteur, ainsi que sur des dépôts de code, et sur plusieurs systèmes commerciaux majeurs tels que GPT-3.5, GPT-4o, Claude, Gemini et d'autres API. Même sans connaissance de l'architecture du modèle ou des corpus d'entraînement, InfoTracer détecte de manière fiable si des jeux de données représentatifs de ces domaines ont probablement été utilisés à l'entraînement, souvent avec une preuve statistique solide à partir de seulement quelques milliers de mots. Le cadre se montre également robuste lorsque des attaquants réécrivent partiellement ou échantillonnent sélectivement les données d'entraînement : si des réécritures lourdes peuvent affaiblir le signal, la précision de la méthode se rétablit en grande partie lorsque davantage de texte est disponible. Dans une démonstration à grande échelle portant sur plus d'un million de mots couvrant 21 romans chinois, InfoTracer sépare nettement les œuvres anciennes susceptibles d'avoir été intégrées à l'entraînement des romans récents qui ne l'ont probablement pas été.
Ce que cela implique pour les droits sur les données
Vu hors du cadre technique, l'article montre que, même lorsque les systèmes d'IA sont opaques, leur comportement porte néanmoins des empreintes mesurables des textes sur lesquels ils ont été entraînés. En exploitant habilement les préférences entre alternatives presque identiques, InfoTracer transforme ces empreintes en preuves exploitables en justice qu'un modèle a mémorisé des sources spécifiques. La méthode ne requiert pas la coopération des fournisseurs d'IA, ni ne modifie les données originales, ce qui la rend adaptée aux auteurs, aux institutions et aux régulateurs souhaitant auditer un usage potentiel abusif. Alors que les expériences actuelles se concentrent sur le texte, les auteurs soutiennent que des idées similaires pourraient s'étendre à l'audio, aux images et à la vidéo. À mesure que l'IA générative s'étend dans des domaines sensibles, de tels outils d'audit boîte noire pourraient devenir un pilier de l'application pratique des règles de confidentialité et du droit d'auteur.
Citation: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Mots-clés: audit des données d'entraînement IA, isotopes d'information, confidentialité des données, droits d'auteur et IA, modèles linguistiques boîte noire