Clear Sky Science · ru
Аудит несанкционированных обучающих данных из контента, сгенерированного ИИ, с помощью информационных изотопов
Почему это важно для обычных пользователей интернета
Современные системы ИИ обучаются на огромных коллекциях текстов, созданных людьми — новостных материалах, романах, коде и даже сообщениях в соцсетях. Многие из этих материалов защищены авторским правом или содержат конфиденциальную информацию, при этом компании, разрабатывающие ИИ, редко раскрывают точный состав использованных данных. В этой статье предложен практический способ для обычных людей, издателей и регуляторов проверить, использовались ли их данные при обучении закрытой модели ИИ, опираясь только на её ответы. Это может существенно поменять правила игры в защите приватности и интеллектуальной собственности в эпоху мощных чат-ботов.
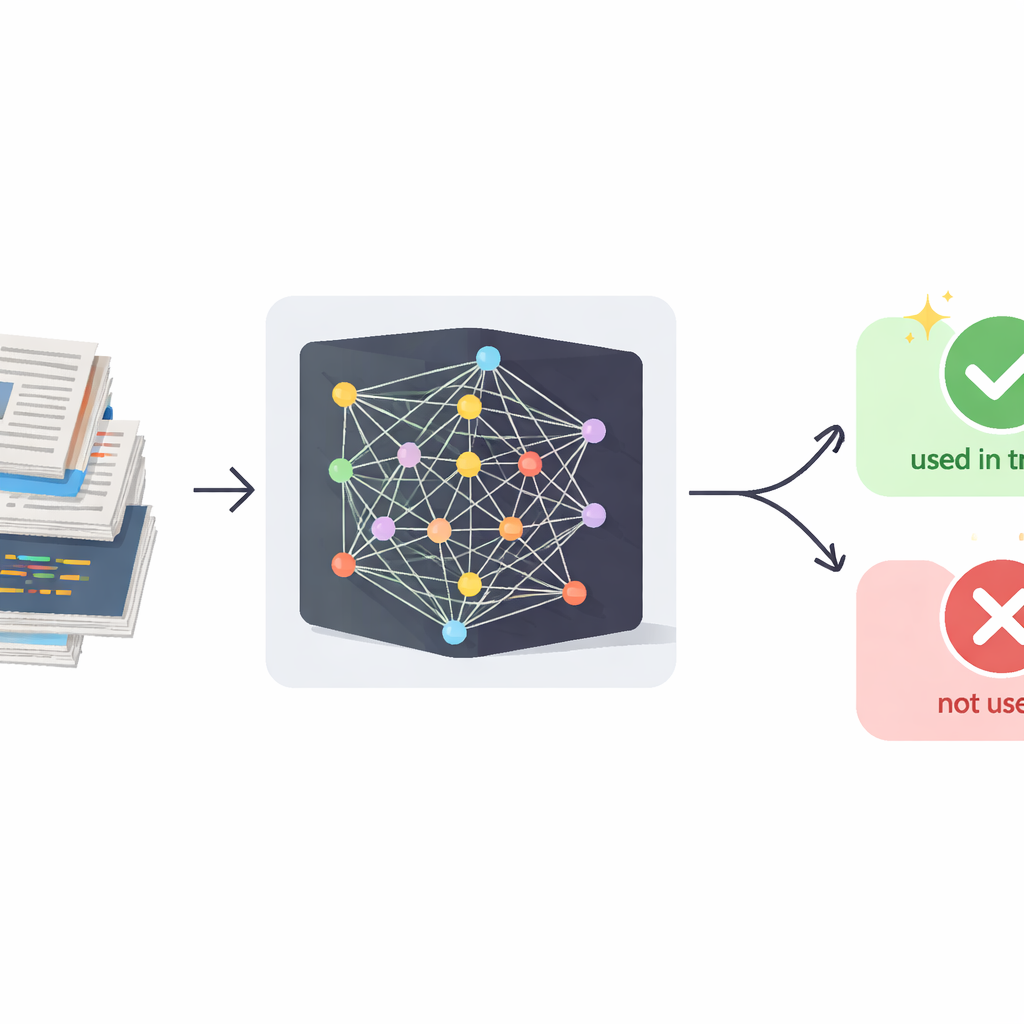
Проблема скрытых обучающих данных
Современные большие языковые модели приобретают свои впечатляющие навыки, поглощая колоссальные объёмы текста. Большая часть этого контента собирается из открытого интернета, где он может быть покрыт строгими лицензиями или содержать чувствительные сведения. В отличие от обычных утечек данных, разработчики ИИ не распространяют сырые данные — они интегрируют их в поведение модели. Коммерческие сервисы затем возвращают только сгенерированный текст, но не внутреннюю структуру или наборы данных обучения. Существующие судебно-технические методы обнаружения использования конкретных примеров в обучении в основном опираются на внутреннюю статистику (например, вероятности токенов), которая недоступна для сервисов типа чат-ботов GPT. Одновременно эти модели настраиваются так, чтобы избегать дословного копирования, поэтому простые проверки на схожесть между вашим документом и ответами модели слишком слабы, чтобы служить надёжным доказательством.
Новая идея: информационные изотопы
Авторы заимствуют понятие из химии, где изотопы — это слегка разные версии одного и того же элемента, которые можно отслеживать в реакциях. В тексте «семантический элемент» — это тонкая единица смысла, например именованная сущность, глагол или строка кода. «Информационный изотоп» — это контекстно уместная альтернатива, которая означает то же самое, но выглядит иначе: например, «New York», «NYC» или «the Big Apple». Ключевой эмпирический вывод заключается в том, что если языковая модель видела исходную формулировку во время обучения, она развивает сильное предпочтение этой точной формы при выборе между несколькими равноразумными вариантами в том же контексте. Для материалов, которых модель не видела в обучении, такое предпочтение намного слабее, потому что модель опирается на общие знания, а не на прямую память.
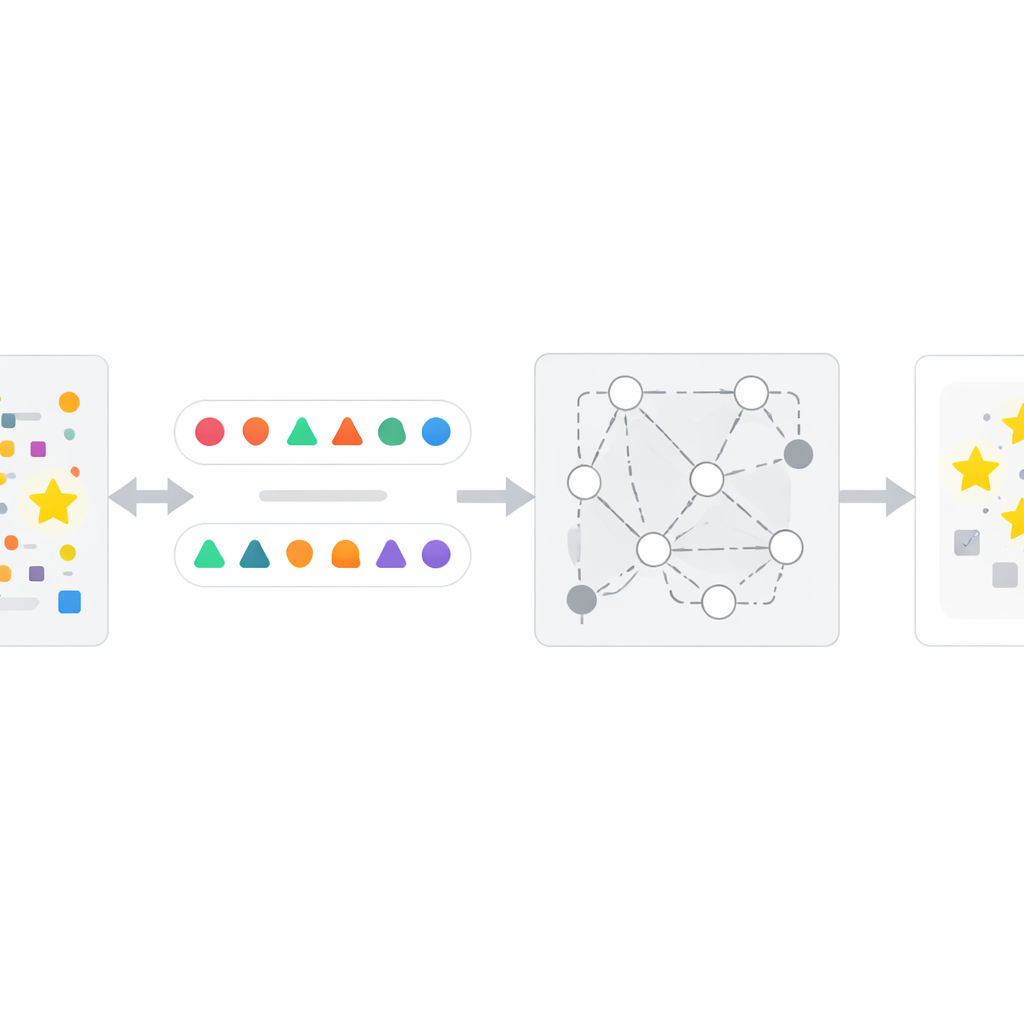
Как работает метод InfoTracer
Опираясь на это наблюдение, авторы разработали четырёхшаговую схему под названием InfoTracer. Сначала он сканирует подозреваемый текст — например новостную статью, медицинскую запись, отрывок книги или файл с кодом — и разбивает его на семантические элементы, фокусируясь на частях речи и строках кода, которые наиболее вероятно оставляют характерный след в памяти. Во-вторых, для каждого выбранного элемента отдельная генеративная модель создаёт несколько контекстно-осмысленных изотопов: разные формулировки или варианты кода, которые по-прежнему естественно вписываются в окружающий отрывок. В-третьих, кандидаты-«зондов» фильтруются, чтобы оставить только те, где человеку-похожему читателю было бы трудно однозначно определить лучший вариант только по контексту; это гарантирует, что сильное предпочтение со стороны целевой модели скорее вызвано экспозицией в обучении, а не здравым смыслом. Наконец, InfoTracer многократно опрашивает закрытую модель с множественным выбором, замаскировав исходный элемент и попросив её выбрать завершение из набора изотопов. Агрегируя, как часто модель выбирает исходную формулировку по множеству зондов, метод даёт итоговый показатель активации, сигнализирующий о том, была ли эта часть текста, вероятно, частью данных обучения.
Проверка метода в действии
Исследователи оценили InfoTracer на широком наборе открытых и коммерческих языковых моделей, используя тщательно составленные бенчмарки, где можно разумно отделить примеры из обучения от непринятых в обучение. На открытых моделях LLaMA с известными предобучающими корпусами InfoTracer с высокой точностью различает вики-отрывки, входящие в набор, и не входящие, даже когда доступны лишь короткие фрагменты. При комбинировании нескольких отрывков из одного источника производительность быстро стремится к идеальному разделению, часто требуя меньше текста, чем короткая научная статья. Метод также превосходит ряд современных конкурентов, включая подходы, опирающиеся на суррогатные модели для аппроксимации целевой системы, и остаётся эффективным в более сложных настройках, где обучающие и тестовые данные имеют схожий стиль и тематику.
Стресс-тесты, реальные модели и длинные тексты
Чтобы смоделировать реальные злоупотребления, авторы проверяли InfoTracer на конфиденциальных медицинских текстах и защищённом авторским правом содержимом книг, а также на репозиториях кода и нескольких основных коммерческих системах, таких как GPT-3.5, GPT-4o, Claude, Gemini и других API. Даже без каких-либо сведений о архитектуре модели или корпусах обучения InfoTracer надёжно выявляет, использовались ли представительные наборы данных из этих доменов при обучении, зачастую давая сильные статистические доказательства на основе всего нескольких тысяч слов. Фреймворк также показывает устойчивость, когда злоумышленники частично переписывают или избирательно выбирают части обучающего материала: при сильном переписывании сигнал может ослабевать, но точность в значительной степени восстанавливается при наличии большего объёма текста. В крупном демонстрационном испытании более чем на миллион слов, охватывающем 21 китайский роман, InfoTracer чётко разделил более старые произведения, которые, по-видимому, попали в обучение, и более поздние романы, которые, вероятно, не использовались.
Что это значит для прав на данные
С нетехнической точки зрения статья показывает, что даже при непрозрачности систем ИИ их поведение всё ещё несёт измеримые отпечатки текстов, на которых они обучались. Хитро эксплуатируя предпочтения между почти идентичными альтернативами, InfoTracer превращает эти отпечатки в доказательства, пригодные для суда, что модель запомнила конкретные источники. Метод не требует сотрудничества с поставщиками ИИ и не модифицирует исходные данные, что делает его доступным авторам, организациям и регуляторам, стремящимся провести аудит возможного злоупотребления. Хотя текущие эксперименты сосредоточены на тексте, авторы утверждают, что похожие идеи можно распространить на аудио, изображения и видео. По мере того как генеративный ИИ проникает в чувствительные области, такие инструменты аудита «черного ящика» могут стать краеугольным камнем обеспечения соблюдения правил приватности и авторского права на практике.
Цитирование: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Ключевые слова: аудит обучающих данных ИИ, информационные изотопы, конфиденциальность данных, авторское право и ИИ, языковые модели «черного ящика»