Clear Sky Science · es
Auditoría de datos de entrenamiento no autorizados a partir de contenido generado por IA usando isótopos de información
Por qué esto importa para los usuarios cotidianos de internet
Los sistemas de IA modernos aprenden a partir de enormes colecciones de texto creado por personas: noticias, novelas, código e incluso publicaciones en redes sociales. Pero muchos de esos materiales están protegidos por derechos de autor o son profundamente personales, y las compañías de IA rara vez revelan exactamente qué usaron. Este artículo presenta una forma práctica para que personas corrientes, editoriales y reguladores verifiquen si un sistema de IA de caja negra se entrenó con sus datos, usando únicamente sus salidas. Eso lo convierte en un posible cambio de juego para proteger la privacidad y la propiedad intelectual en la era de los potentes chatbots.
El problema de los datos de entrenamiento ocultos
Los grandes modelos de lenguaje actuales adquieren sus impresionantes habilidades al absorber ingentes cantidades de material escrito. Gran parte de ese contenido se rastrea desde internet público, donde puede estar sujeto a licencias estrictas o contener información sensible. A diferencia de las filtraciones de datos tradicionales, no obstante, los desarrolladores de IA no redistribuyen los datos en bruto; en cambio, los incorporan al comportamiento del modelo. Los sistemas comerciales exponen únicamente texto generado, no sus mecanismos internos ni los conjuntos de entrenamiento. Las técnicas forenses existentes para detectar si ejemplos concretos se usaron en entrenamiento dependen en su mayoría de estadísticas internas, como probabilidades de tokens, que no están disponibles en servicios tipo chatbot estilo GPT. Al mismo tiempo, estos modelos se ajustan para evitar copiar pasajes literal y textualmente, por lo que comprobaciones simples de similitud entre su documento y las respuestas del modelo son demasiado débiles para servir como evidencia fiable.
Una idea nueva: isótopos de información
Los autores toman prestado un concepto de la química, donde los isótopos son versiones ligeramente distintas del mismo elemento que pueden rastrearse a través de reacciones. En el texto, un «elemento semántico» es una pieza fina de significado—como una entidad nombrada, un verbo o una línea específica de código fuente. Un «isótopo de información» es una alternativa adecuada al contexto que significa lo mismo pero se ve diferente: por ejemplo, «Nueva York», «NYC» y «la Gran Manzana». El hallazgo empírico clave es que si un modelo de lenguaje vio la redacción original durante el entrenamiento, desarrolla una fuerte preferencia por esa forma exacta cuando se le pide elegir entre varias variantes igualmente razonables en el mismo contexto. Para material que el modelo no vio en entrenamiento, esta preferencia es mucho más débil, porque sólo puede apoyarse en conocimiento general en lugar de una memoria directa.
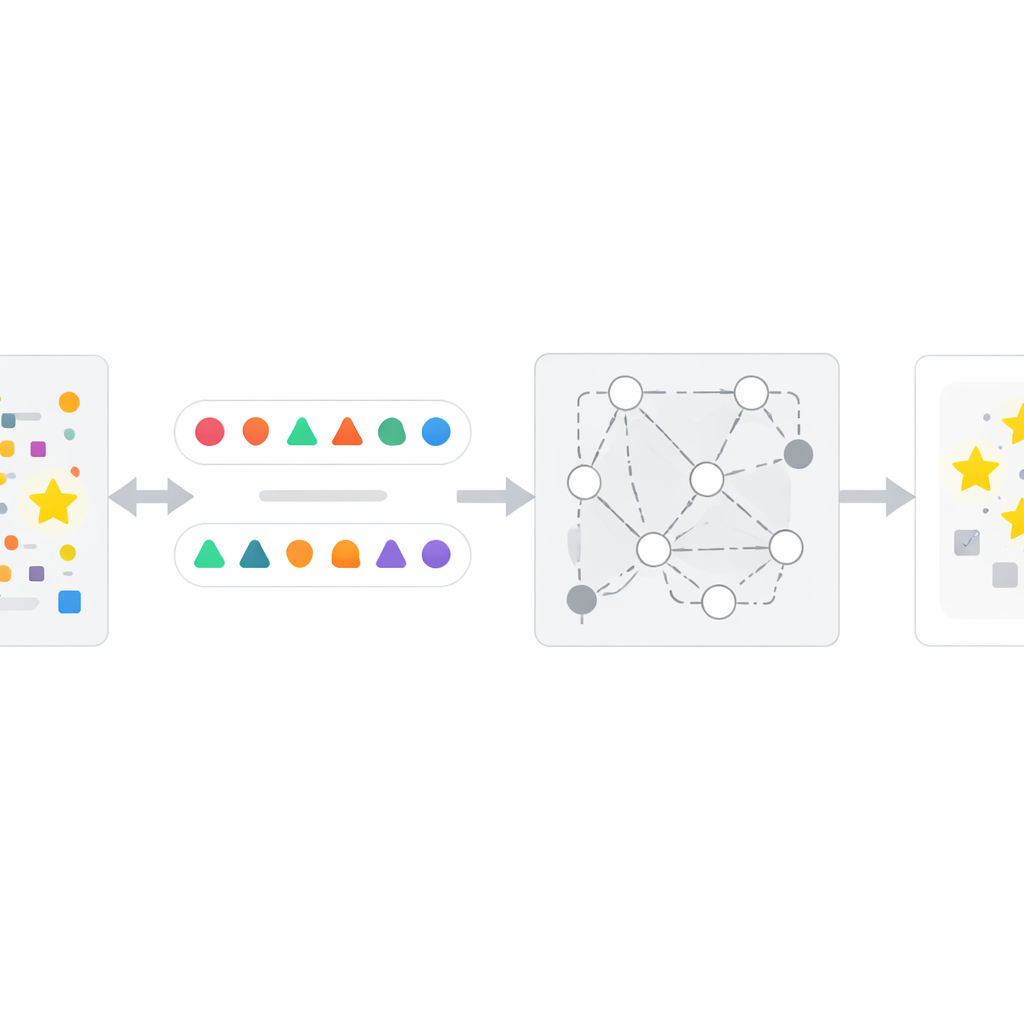
Cómo funciona el método InfoTracer
Basándose en esta idea, los autores diseñan un marco de cuatro pasos llamado InfoTracer. Primero, analiza un texto sospechoso—como un artículo de noticias, un historial médico, un pasaje de libro o un archivo de código—y lo descompone en elementos semánticos, centrándose en partes del discurso y líneas de código que probablemente dejen una huella de memoria distintiva. En segundo lugar, para cada elemento elegido usa un modelo generativo separado para crear varios isótopos conscientes del contexto: diferentes frases o variantes de código que aún encajan de forma natural en el pasaje circundante. Tercero, filtra estos candidatos «sondas» para conservar sólo aquellos donde un lector con criterio humano no podría decir fácilmente cuál opción es la mejor a partir del contexto, asegurando que cualquier preferencia marcada mostrada por la IA objetivo probablemente se deba a la exposición en el entrenamiento y no al sentido común. Finalmente, InfoTracer consulta repetidamente a la IA de caja negra con indicaciones de elección múltiple que enmascaran el elemento original y le piden escoger una continuación del conjunto de isótopos. Al agregar con qué frecuencia la IA elige la redacción original a través de muchas sondas, el método produce una puntuación de activación general que señala si es probable que el texto formara parte de los datos de entrenamiento.
Poniendo la técnica a prueba
Los investigadores evalúan InfoTracer en una amplia selección de modelos de lenguaje abiertos y comerciales, usando bancos de prueba construidos cuidadosamente donde pueden separar razonablemente ejemplos de entrenamiento de no entrenamiento. En modelos LLaMA de código abierto con datos de preentrenamiento conocidos, InfoTracer distingue pasajes de Wikipedia que son miembros del conjunto de entrenamiento de los que no lo son con muy alta precisión, incluso cuando sólo hay fragmentos cortos disponibles. Cuando se combinan varios pasajes de la misma fuente, el rendimiento se acerca rápidamente a una separación perfecta, a menudo usando menos que la longitud de un artículo corto. El método también supera a una serie de competidores de última generación, incluidos aquellos que dependen de modelos sustitutos para aproximar el sistema objetivo, y sigue siendo efectivo en configuraciones más exigentes donde los datos de entrenamiento y de prueba comparten el mismo estilo y temas generales.
Pruebas de estrés, modelos del mundo real y textos largos
Para imitar el abuso en el mundo real, los autores prueban InfoTracer en textos médicos sensibles para la privacidad y contenido de libros con derechos de autor, así como en repositorios de código, y en varios sistemas comerciales importantes como GPT-3.5, GPT-4o, Claude, Gemini y otras API. Incluso sin ningún conocimiento sobre la arquitectura del modelo o los corpus de entrenamiento, InfoTracer detecta de manera fiable si conjuntos de datos representativos de estos dominios probablemente se usaron en entrenamiento, a menudo con evidencia estadística fuerte a partir de sólo unos pocos miles de palabras. El marco también demuestra ser robusto cuando los atacantes reescriben parcialmente o muestrean selectivamente los datos de entrenamiento: aunque una reescritura intensa puede debilitar la señal, la precisión del método se recupera en gran medida cuando hay más texto disponible. En una demostración a gran escala con más de un millón de palabras que abarcan 21 novelas chinas, InfoTracer separó claramente obras antiguas que plausiblemente entraron en el entrenamiento de novelas recientes que probablemente no lo hicieron.
Qué significa esto para los derechos sobre los datos
Visto desde una perspectiva no técnica, el artículo muestra que incluso cuando los sistemas de IA son opacos, su comportamiento sigue llevando huellas medibles de los textos con los que se entrenaron. Al explotar hábilmente las preferencias entre alternativas casi idénticas, InfoTracer convierte estas huellas en evidencia apta para tribunales de que un modelo ha memorizado fuentes específicas. El método no requiere la cooperación de los proveedores de IA, ni modifica los datos originales, lo que lo hace adecuado para autores, instituciones y reguladores que buscan auditar un posible uso indebido. Aunque los experimentos actuales se centran en texto, los autores sostienen que ideas similares podrían extenderse a audio, imágenes y vídeo. A medida que la IA generativa continúa expandiéndose hacia dominios sensibles, tales herramientas de auditoría de caja negra podrían convertirse en una piedra angular para hacer cumplir en la práctica las normas de privacidad y derechos de autor.
Cita: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Palabras clave: auditoría de datos de entrenamiento de IA, isótopos de información, privacidad de datos, derechos de autor y IA, modelos de lenguaje de caja negra