Clear Sky Science · pl
Audyting nieautoryzowanych danych treningowych z treści generowanych przez AI przy użyciu izotopów informacji
Dlaczego to ma znaczenie dla zwykłych użytkowników internetu
Współczesne systemy AI uczą się na ogromnych zbiorach tekstów stworzonych przez ludzi — artykułach informacyjnych, powieściach, kodzie, a nawet wpisach w mediach społecznościowych. Wiele z tych materiałów jest jednak objętych prawami autorskimi lub zawiera dane o charakterze osobistym, a firmy rozwijające AI rzadko ujawniają dokładnie, czego użyły. Artykuł przedstawia praktyczny sposób, dzięki któremu zwykli ludzie, wydawcy i regulatorzy mogą sprawdzić, czy czarno-skrzynkowy system AI był trenowany na ich danych, korzystając wyłącznie z jego wyjść. To może zmienić zasady gry w ochronie prywatności i własności intelektualnej w erze potężnych chatbotów.
Problem ukrytych danych treningowych
Dzisiejsze duże modele językowe zdobywają swoje imponujące umiejętności, wchłaniając ogromne ilości materiałów pisanych. Duża część tych treści jest zeskrobywana z publicznego internetu, gdzie może podlegać surowym licencjom lub zawierać wrażliwe informacje. W odróżnieniu od tradycyjnych naruszeń danych, twórcy AI zwykle nie rozpowszechniają surowych danych; zamiast tego „wypiekają” je w zachowaniu modelu. Komercyjne systemy udostępniają jedynie generowany tekst, nie swoje wnętrza ani zbiory treningowe. Istniejące techniki kryminalistyczne do wykrywania, czy konkretne przykłady były użyte w treningu, opierają się przeważnie na wewnętrznych statystykach, takich jak prawdopodobieństwa tokenów, które są niedostępne w usługach typu GPT. Równocześnie modele są dostrajane, by unikać kopiowania fragmentów słowo w słowo, więc proste porównania podobieństwa między twoim dokumentem a odpowiedziami modelu są zbyt słabe, by stanowić wiarygodny dowód.
Nowy pomysł: izotopy informacji
Autorzy zapożyczają koncepcję z chemii, gdzie izotopy to nieco odmienne wersje tego samego pierwiastka, które można śledzić w reakcjach. W tekście „element semantyczny” to drobny fragment znaczenia — na przykład nazwa własna, czasownik lub konkretna linia kodu. „Izotop informacji” to odpowiedni kontekstowo wariant, który znaczy to samo, lecz wygląda inaczej: na przykład „New York”, „NYC” i „the Big Apple”. Kluczowe odkrycie empiryczne jest takie, że jeśli model językowy widział w treningu oryginalne sformułowanie, rozwija silną preferencję dla tej właśnie formy, gdy proszony jest o wybór spośród kilku równie rozsądnych wariantów w tym samym kontekście. Dla materiału, którego model nigdy nie widział podczas treningu, ta preferencja jest znacznie słabsza, ponieważ model może polegać jedynie na ogólnej wiedzy zamiast bezpośredniej pamięci.
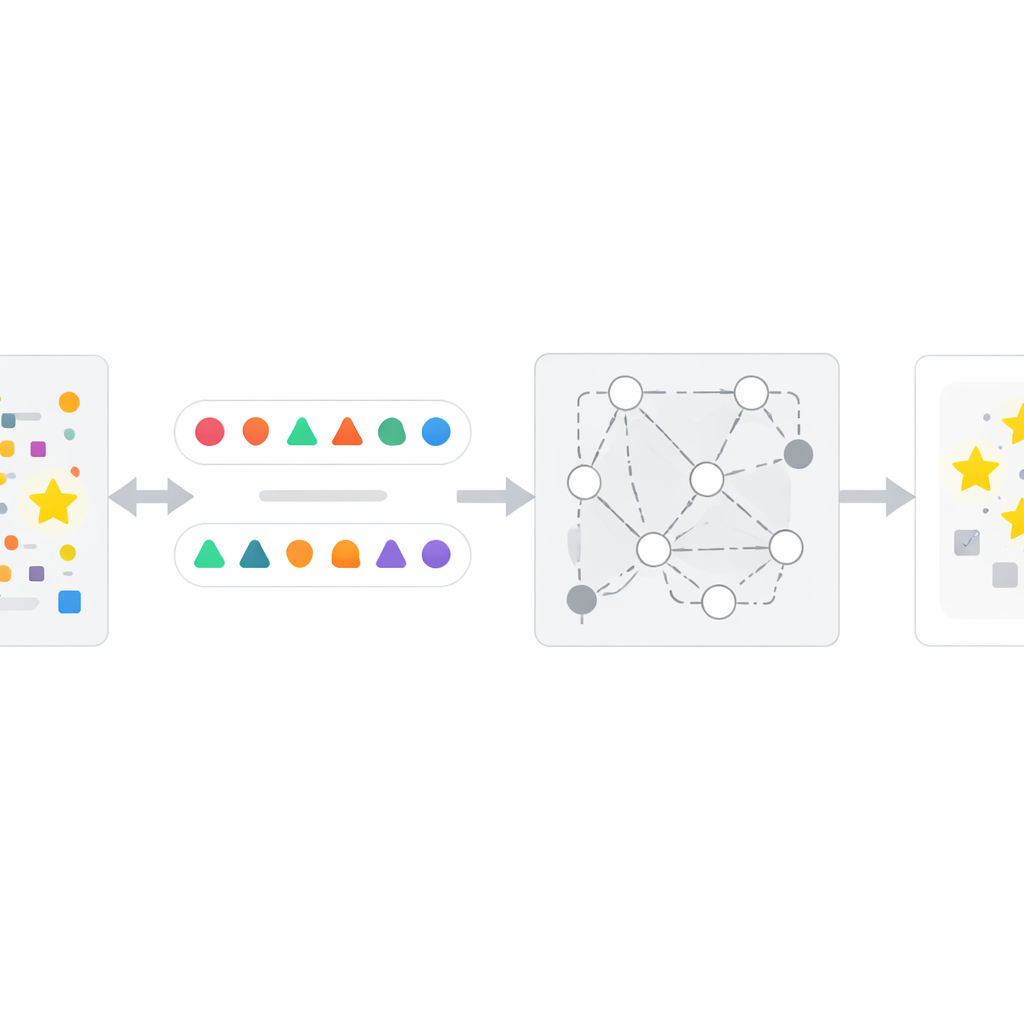
Jak działa metoda InfoTracer
Wykorzystując to spostrzeżenie, autorzy zaprojektowali czterostopniowe ramy nazwane InfoTracer. Po pierwsze, skanuje się podejrzany tekst — na przykład artykuł informacyjny, dokumentację medyczną, fragment książki lub plik z kodem — i dzieli go na elementy semantyczne, koncentrując się na częściach mowy i liniach kodu, które najpewniej pozostawią charakterystyczny ślad pamięciowy. Po drugie, dla każdego wybranego elementu używa się oddzielnego modelu generatywnego do stworzenia kilku kontekstowo odpowiednich izotopów: różnych sformułowań lub wariantów kodu, które nadal naturalnie pasują do otaczającego fragmentu. Po trzecie, filtruje się te kandydackie „sondy”, pozostawiając tylko te, w których czytelnik ludzki nie byłby w stanie łatwo określić, która opcja jest najlepsza tylko na podstawie kontekstu — co zapewnia, że każda silna preferencja pokazywana przez docelowe AI jest prawdopodobnie wynikiem ekspozycji treningowej, a nie zdrowego rozsądku. Wreszcie, InfoTracer wielokrotnie zapytuje czarno-skrzynkowy AI za pomocą wielokrotnego wyboru, maskując oryginalny element i prosząc o wybór uzupełnienia z zestawu izotopów. Agregując, jak często AI wybiera oryginalne sformułowanie w wielu sondach, metoda generuje ogólny wynik aktywacji, który sygnalizuje, czy tekst najprawdopodobniej był częścią danych treningowych.
Testowanie techniki
Badacze oceniają InfoTracer na szerokim zestawie otwartych i komercyjnych modeli językowych, korzystając z starannie skonstruowanych benchmarków, w których można rozsądnie oddzielić przykłady treningowe od nietreningowych. W otwartoźródłowych modelach LLaMA z znanymi danymi wstępnego treningu, InfoTracer z bardzo wysoką dokładnością odróżnia fragmenty Wikipedii będące członkami zbioru treningowego od tych nienależących, nawet gdy dostępne są tylko krótkie fragmenty. Gdy łączy się wiele fragmentów z tego samego źródła, wydajność szybko zbliża się do idealnego rozdzielenia, często przy użyciu mniej niż długość krótkiego artykułu. Metoda przewyższa też szereg konkurentów ze stanu techniki, w tym tych opierających się na modelach zastępczych do przybliżania systemu docelowego, i pozostaje skuteczna w bardziej wymagających ustawieniach, gdzie dane treningowe i testowe dzielą ten sam ogólny styl i tematy.
Testy obciążeniowe, modele ze świata rzeczywistego i długie teksty
Aby naśladować nadużycia w świecie rzeczywistym, autorzy testują InfoTracer na wrażliwych prywatnościowo tekstach medycznych i treściach chronionych prawem autorskim książek, a także w repozytoriach kodu oraz na kilku głównych systemach komercyjnych takich jak GPT-3.5, GPT-4o, Claude, Gemini i innych interfejsach API. Nawet bez wiedzy o architekturze modelu czy korpusach treningowych, InfoTracer wiarygodnie wykrywa, czy reprezentatywne zbiory danych z tych domen prawdopodobnie były użyte w treningu, często dostarczając silnych dowodów statystycznych przy zaledwie kilku tysiącach słów. Ramy te dowodzą też odporności, gdy atakujący częściowo przepisywali lub selektywnie próbkowali dane treningowe: choć silne przepisywanie może osłabić sygnał, dokładność metody w dużej mierze odtwarza się, gdy dostępny jest większy fragment tekstu. W demonstracji na dużą skalę, obejmującej ponad milion słów z 21 chińskich powieści, InfoTracer wyraźnie oddzielił starsze dzieła, które prawdopodobnie weszły do treningu, od nowszych powieści, które najprawdopodobniej tego nie zrobiły.
Co to oznacza dla praw do danych
Z perspektywy nietechnicznej artykuł pokazuje, że nawet gdy systemy AI są nieprzejrzyste, ich zachowanie nadal niesie mierzalne odciski palców tekstów, na których były trenowane. Dzięki sprytnemu wykorzystaniu preferencji między niemal identycznymi alternatywami, InfoTracer zamienia te odciski w dowody gotowe do użycia w sądzie, że model zapamiętał konkretne źródła. Metoda nie wymaga współpracy dostawców AI ani modyfikowania oryginalnych danych, co czyni ją odpowiednią dla autorów, instytucji i regulatorów chcących przeprowadzić audyt potencjalnego nadużycia. Choć obecne eksperymenty skupiają się na tekście, autorzy argumentują, że podobne pomysły można rozszerzyć na audio, obrazy i wideo. W miarę jak generatywne AI zagłębia się w wrażliwe domeny, takie narzędzia do audytu czarnych skrzynek mogą stać się fundamentem egzekwowania zasad prywatności i praw autorskich w praktyce.
Cytowanie: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Słowa kluczowe: audyting danych treningowych AI, izotopy informacji, prywatność danych, prawa autorskie i AI, czarne skrzynki modeli językowych