Clear Sky Science · de
Prüfung unerlaubter Trainingsdaten aus KI-generierten Inhalten mithilfe von Informationsisotopen
Warum das für alltägliche Internetnutzer wichtig ist
Moderne KI-Systeme lernen aus riesigen Sammlungen menschlich erstellter Texte – Nachrichtenartikel, Romane, Code und sogar Beiträge in sozialen Medien. Viele dieser Materialien sind jedoch urheberrechtlich geschützt oder sehr persönlich, und KI-Unternehmen geben selten genau an, was sie verwendet haben. Dieses Papier stellt eine praktische Methode vor, mit der gewöhnliche Menschen, Verlage und Aufsichtsbehörden prüfen können, ob ein Black-Box-KI-System mit ihren Daten trainiert wurde – allein anhand der Ausgaben des Systems. Das könnte ein Wendepunkt sein, um Privatsphäre und geistiges Eigentum im Zeitalter leistungsfähiger Chatbots zu schützen.
Das Problem versteckter Trainingsdaten
Die heutigen großen Sprachmodelle erwerben ihre beeindruckenden Fähigkeiten, indem sie enorme Mengen schriftlicher Materialien aufnehmen. Ein Großteil dieses Inhalts wird aus dem öffentlichen Internet gekratzt, wo er strengen Lizenzen unterliegen oder sensible Informationen enthalten kann. Anders als bei traditionellen Datenpannen geben KI-Entwickler jedoch nicht die Rohdaten weiter; stattdessen sind diese im Verhalten des Modells eingebacken. Kommerzielle Systeme geben dann nur generierten Text preis, nicht ihre internen Abläufe oder Trainingssätze. Bestehende forensische Techniken zur Feststellung, ob bestimmte Beispiele im Training verwendet wurden, stützen sich meist auf interne Statistiken wie Token-Wahrscheinlichkeiten, die für Dienste wie GPT-ähnliche Chatbots nicht verfügbar sind. Gleichzeitig sind diese Modelle darauf getrimmt, Passagen nicht wortwörtlich zu kopieren, sodass einfache Ähnlichkeitsprüfungen zwischen Ihrem Dokument und den Antworten des Modells zu schwach sind, um als verlässlicher Beweis zu dienen.
Eine neue Idee: Informationsisotope
Die Autoren entlehnen ein Konzept aus der Chemie, wo Isotope leicht unterschiedliche Versionen desselben Elements sind, die man in Reaktionen verfolgen kann. Im Text ist ein „semantisches Element" ein feingliedriger Bedeutungsbestandteil – etwa ein benannter Ausdruck, ein Verb oder eine bestimmte Codezeile. Ein „Informationsisotop" ist eine kontextangemessene Alternative, die dasselbe meint, aber anders aussieht: zum Beispiel „New York“, „NYC" und „the Big Apple“. Die entscheidende empirische Beobachtung ist, dass ein Sprachmodell, das die ursprüngliche Wortwahl während des Trainings gesehen hat, eine starke Präferenz für genau diese Form entwickelt, wenn es aufgefordert wird, unter mehreren gleichermaßen sinnvollen Varianten im selben Kontext zu wählen. Für Material, das das Modell nie gesehen hat, ist diese Präferenz deutlich schwächer, weil es sich nur auf allgemeines Wissen statt auf direkte Erinnerung stützen kann.
Wie die InfoTracer-Methode funktioniert
Aufbauend auf dieser Einsicht entwerfen die Autoren ein vierstufiges Rahmenwerk namens InfoTracer. Zuerst durchsucht es einen verdächtigen Text – etwa einen Zeitungsartikel, eine Krankenakte, einen Buchauszug oder eine Code-Datei – und zerlegt ihn in semantische Elemente, wobei es sich auf Wortarten und Codezeilen konzentriert, die wahrscheinlich eine unterscheidbare Erinnerungsspuren hinterlassen. Zweitens verwendet es für jedes ausgewählte Element ein separates generatives Modell, um mehrere kontextbewusste Isotope zu erzeugen: unterschiedliche Formulierungen oder Codevarianten, die sich natürlich in den umgebenden Absatz einfügen. Drittens filtert es diese Kandidaten-„Sonden“, sodass nur diejenigen übrig bleiben, bei denen ein menschlicher Leser aus dem Kontext allein nicht leicht erkennen könnte, welche Option am besten passt; so ist sichergestellt, dass jede starke Präferenz des Ziel-KI-Systems eher auf Trainingsexposition als auf Allgemeinwissen zurückzuführen ist. Schließlich befragt InfoTracer das Black-Box-KI-System wiederholt mit Multiple-Choice-Prompts, die das ursprüngliche Element maskieren und es auffordern, eine Vervollständigung aus dem Isotopensatz zu wählen. Durch Aggregation, wie oft die KI die ursprüngliche Wortwahl über viele Sonden hinweg auswählt, erzeugt die Methode einen Gesamtaktivierungsscore, der anzeigt, ob der Text wahrscheinlich Teil der Trainingsdaten war.
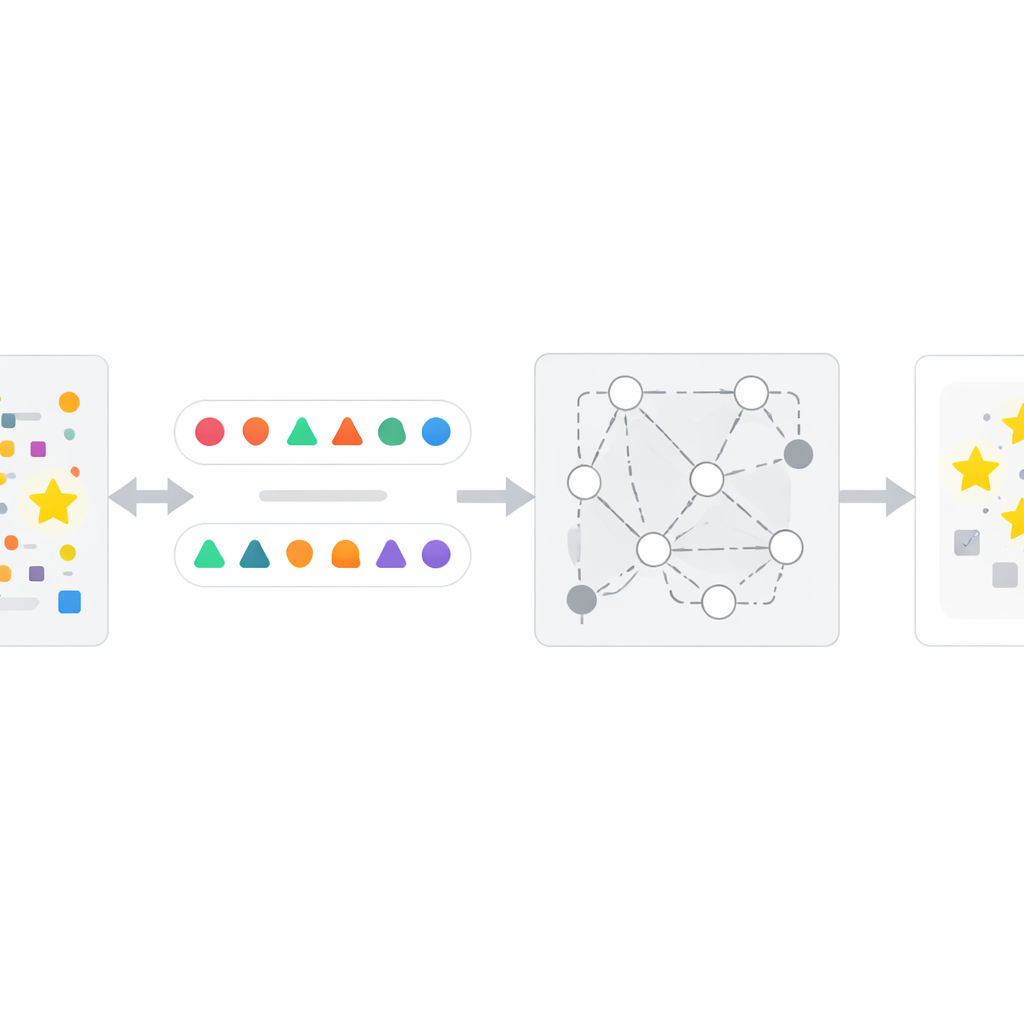
Die Technik in der Praxis
Die Forschenden bewerten InfoTracer an einer breiten Auswahl offener und kommerzieller Sprachmodelle und verwenden sorgfältig konstruierte Benchmarks, bei denen sie Trainingsbeispiele vernünftigerweise von Nicht-Trainingsbeispielen trennen können. Bei Open-Source-LLaMA-Modellen mit bekannten Vortrainingsdaten unterscheidet InfoTracer Mitglieds- von Nicht-Mitglieds-Wikipedia-Passagen mit sehr hoher Genauigkeit, selbst wenn nur kurze Ausschnitte zur Verfügung stehen. Wenn mehrere Passagen derselben Quelle kombiniert werden, nähert sich die Leistung schnell einer perfekten Trennung an, oft unter Verwendung von weniger Text als die Länge einer kurzen wissenschaftlichen Arbeit. Die Methode übertrifft auch eine Reihe von leistungsfähigen Konkurrenten, einschließlich solcher, die auf Ersatzmodellen beruhen, um das Zielsystem zu approximieren, und bleibt in anspruchsvolleren Szenarien wirksam, in denen Trainings- und Testdaten denselben Stil und dieselben Themen teilen.
Stresstests, reale Modelle und lange Texte
Um realen Missbrauch zu simulieren, testen die Autoren InfoTracer an datenschutzsensiblen medizinischen Texten und urheberrechtlich geschützten Buchinhalten sowie Code-Repositories und an mehreren großen kommerziellen Systemen wie GPT-3.5, GPT-4o, Claude, Gemini und anderen APIs. Selbst ohne Kenntnis der Modellarchitektur oder der Trainingskorpora erkennt InfoTracer zuverlässig, ob repräsentative Datensätze aus diesen Bereichen wahrscheinlich im Training verwendet wurden, häufig mit starken statistischen Belegen bereits nach wenigen Tausend Wörtern. Das Rahmenwerk erweist sich auch als robust gegenüber Angreifern, die Trainingsdaten teilweise umschreiben oder selektiv sampeln: Während starkes Umschreiben das Signal abschwächen kann, erholt sich die Genauigkeit weitgehend, wenn mehr Text verfügbar ist. In einer großangelegten Demonstration mit über einer Million Wörtern aus 21 chinesischen Romanen trennt InfoTracer klar ältere Werke, die plausibel in Trainingsdaten gelangt sein könnten, von neueren Romanen, die wahrscheinlich nicht enthalten waren.
Was das für Datenrechte bedeutet
Aus nicht-technischer Perspektive zeigt das Papier, dass das Verhalten von KI-Systemen trotz ihrer Undurchsichtigkeit messbare Fingerabdrücke der Texte trägt, auf denen sie trainiert wurden. Indem InfoTracer Präferenzen zwischen nahezu identischen Alternativen geschickt ausnutzt, verwandelt die Methode diese Fingerabdrücke in gerichtsverwertbare Beweise dafür, dass ein Modell bestimmte Quellen memoriert hat. Die Methode benötigt keine Kooperation der KI-Anbieter und verändert die Originaldaten nicht, was sie für Autoren, Institutionen und Aufsichtsbehörden geeignet macht, die möglichen Missbrauch prüfen wollen. Obwohl die aktuellen Experimente sich auf Text konzentrieren, argumentieren die Autoren, dass ähnliche Ideen auf Audio, Bilder und Video übertragbar sind. Mit der fortschreitenden Ausbreitung generativer KI in sensiblen Bereichen könnten derartige Black-Box-Audit-Tools zu einem Eckpfeiler der Durchsetzung von Datenschutz- und Urheberrechtsregeln in der Praxis werden.
Zitation: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Schlüsselwörter: Prüfung von KI-Trainingsdaten, Informationsisotope, Datenschutz, Urheberrecht und KI, Black-Box-Sprachmodelle