Clear Sky Science · pt
Auditoria de dados de treinamento não autorizados a partir de conteúdo gerado por IA usando isótopos de informação
Por que isso importa para usuários comuns da internet
Sistemas de IA modernos aprendem a partir de enormes coleções de textos criados por pessoas — notícias, romances, código e até postagens em redes sociais. Mas muitos desses materiais são protegidos por direitos autorais ou são profundamente pessoais, e as empresas de IA raramente revelam exatamente o que utilizaram. Este artigo apresenta um método prático para que pessoas comuns, editoras e reguladores verifiquem se um sistema de IA caixa-preta foi treinado com seus dados, usando apenas suas saídas. Isso pode mudar o jogo na proteção da privacidade e da propriedade intelectual na era de chatbots poderosos.
O problema dos dados de treinamento ocultos
Os grandes modelos de linguagem de hoje adquiriam suas habilidades impressionantes absorvendo vastas quantidades de material escrito. Grande parte desse conteúdo é raspada da internet pública, onde pode estar sujeita a licenças restritivas ou conter informações sensíveis. Diferentemente de vazamentos de dados tradicionais, porém, desenvolvedores de IA não redistribuem os dados brutos; em vez disso, eles os incorporam ao comportamento do modelo. Sistemas comerciais expõem então apenas o texto gerado, não seus mecanismos internos nem os conjuntos de treinamento. Técnicas forenses existentes para detectar se exemplos específicos foram usados no treinamento dependem principalmente de estatísticas internas, como probabilidades de tokens, que não estão disponíveis em serviços estilo chatbot GPT. Ao mesmo tempo, esses modelos são ajustados para evitar copiar trechos literalmente, de modo que verificações simples de similaridade entre seu documento e as respostas do modelo são fracas demais para servir como evidência confiável.
Uma ideia nova: isótopos de informação
Os autores tomam emprestado um conceito da química, onde isótopos são versões ligeiramente diferentes do mesmo elemento que podem ser rastreadas através de reações. Em texto, um “elemento semântico” é uma unidade fina de significado — como uma entidade nomeada, um verbo ou uma linha específica de código-fonte. Um “isótopo de informação” é uma alternativa apropriada ao contexto que significa a mesma coisa, mas parece diferente: por exemplo, “New York”, “NYC” e “the Big Apple”. A constatação empírica central é que, se um modelo de linguagem viu a redação original durante o treinamento, ele desenvolve uma preferência forte por essa forma exata quando solicitado a escolher entre várias variantes igualmente plausíveis no mesmo contexto. Para material que o modelo nunca viu em treinamento, essa preferência é bem mais fraca, porque ele conta apenas com conhecimento geral em vez de memória direta.
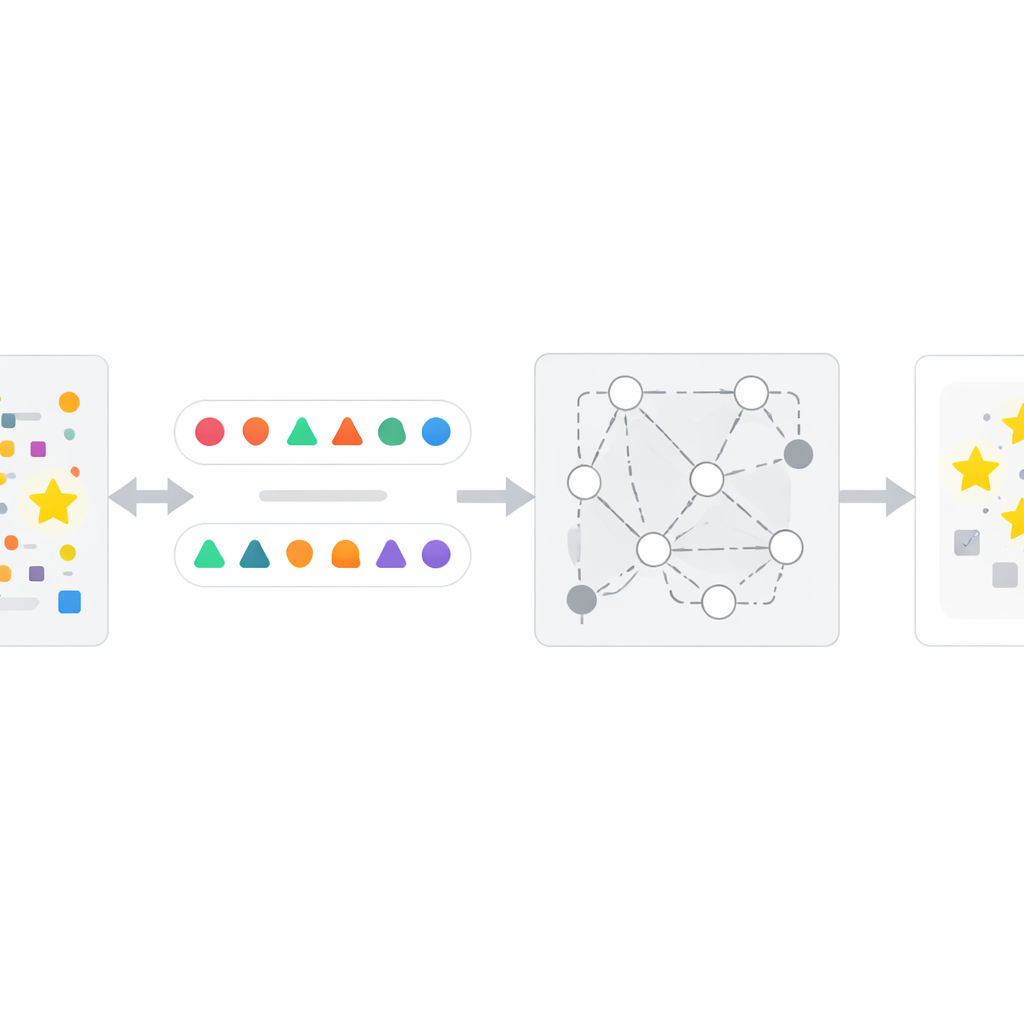
Como funciona o método InfoTracer
Com base nessa percepção, os autores desenham um quadro de quatro etapas chamado InfoTracer. Primeiro, ele escaneia um texto suspeito — como um artigo de notícia, prontuário médico, trecho de livro ou arquivo de código — e o divide em elementos semânticos, focando em classes gramaticais e linhas de código que provavelmente deixam um traço de memória distintivo. Segundo, para cada elemento escolhido, usa-se um modelo generativo separado para criar várias isótopos contextualmente apropriados: diferentes formulações ou variantes de código que ainda se encaixam naturalmente no trecho circundante. Terceiro, filtra-se esses candidatos “sondas” para manter apenas aqueles em que um leitor humano razoável não poderia facilmente discernir qual opção é a melhor pelo contexto sozinho, assegurando que qualquer preferência forte demonstrada pela IA-alvo seja provavelmente devido à exposição no treinamento, e não ao senso comum. Finalmente, o InfoTracer consulta repetidamente a IA caixa-preta com prompts de múltipla escolha que mascaram o elemento original e pedem que ela escolha uma continuação dentre o conjunto de isótopos. Ao agregar a frequência com que a IA escolhe a redação original através de muitas sondas, o método produz uma pontuação de ativação geral que sinaliza se o texto provavelmente fez parte dos dados de treinamento.
Testando a técnica
Os pesquisadores avaliam o InfoTracer em uma ampla seleção de modelos de linguagem abertos e comerciais, usando benchmarks cuidadosamente construídos onde podem razoavelmente separar exemplos de treinamento de não-treinamento. Em modelos LLaMA de código aberto com dados de pré-treinamento conhecidos, o InfoTracer distingue com altíssima precisão trechos da Wikipédia que fazem parte do treinamento daqueles que não fazem, mesmo quando estão disponíveis apenas curtos fragmentos. Quando múltiplos trechos da mesma fonte são combinados, o desempenho rapidamente se aproxima de separação perfeita, frequentemente usando menos que o tamanho de um artigo curto. O método também supera uma série de concorrentes de última geração, incluindo aqueles que dependem de modelos substitutos para aproximar o sistema alvo, e permanece eficaz em cenários mais exigentes onde dados de treinamento e de teste compartilham o mesmo estilo e tópicos gerais.
Testes de estresse, modelos do mundo real e textos longos
Para imitar abusos do mundo real, os autores testam o InfoTracer em textos médicos sensíveis à privacidade e em conteúdo de livros protegidos por direitos autorais, assim como em repositórios de código, e em vários grandes sistemas comerciais como GPT-3.5, GPT-4o, Claude, Gemini e outras APIs. Mesmo sem qualquer conhecimento sobre a arquitetura do modelo ou corpora de treinamento, o InfoTracer detecta de forma confiável se conjuntos representativos desses domínios provavelmente foram usados no treinamento, muitas vezes com forte evidência estatística a partir de apenas alguns milhares de palavras. A estrutura também se mostra robusta quando atacantes reescrevem parcialmente ou amostram seletivamente os dados de treinamento: embora reescritas intensas possam enfraquecer o sinal, a precisão do método se recupera amplamente quando mais texto está disponível. Em uma demonstração em grande escala com mais de um milhão de palavras abrangendo 21 romances chineses, o InfoTracer separa claramente obras mais antigas que plausivelmente entraram no treinamento de romances recentes que provavelmente não entraram.
O que isso significa para os direitos sobre dados
Visto de uma perspectiva não técnica, o artigo mostra que, mesmo quando sistemas de IA são opacos, seu comportamento ainda carrega impressões digitais mensuráveis dos textos com os quais foram treinados. Ao explorar de forma inteligente preferências entre alternativas quase idênticas, o InfoTracer transforma essas impressões digitais em evidência adequada para tribunais de que um modelo memorizou fontes específicas. O método não exige cooperação dos provedores de IA, nem modifica os dados originais, tornando-o adequado para autores, instituições e reguladores que buscam auditar possíveis usos indevidos. Embora experimentos atuais se concentrem em texto, os autores argumentam que ideias similares poderiam se estender a áudio, imagens e vídeo. À medida que a IA generativa continua a se expandir em domínios sensíveis, ferramentas de auditoria caixa-preta como esta podem se tornar pilares da aplicação prática de regras de privacidade e direitos autorais.
Citação: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Palavras-chave: auditoria de dados de treinamento de IA, isótopos de informação, privacidade de dados, direitos autorais e IA, modelos de linguagem caixa-preta