Clear Sky Science · nl
Auditen van ongeautoriseerde trainingsdata uit AI‑gegenereerde content met informatie‑isotopen
Waarom dit ertoe doet voor dagelijkse internetgebruikers
Moderne AI‑systemen leren van enorme verzamelingen door mensen gemaakte tekst — nieuwsartikelen, romans, code, zelfs berichten op sociale media. Veel van dit materiaal is echter auteursrechtelijk beschermd of sterk persoonlijk, en AI‑bedrijven maken zelden precies bekend wat ze hebben gebruikt. Dit artikel introduceert een praktische methode waarmee gewone mensen, uitgevers en toezichthouders kunnen nagaan of een black‑box AI‑systeem op hun data is getraind, door alleen naar de uitkomsten van het systeem te kijken. Dat kan een doorbraak betekenen voor de bescherming van privacy en intellectueel eigendom in het tijdperk van krachtige chatbots.
Het probleem van verborgen trainingsdata
De huidige grote taalmodellen verwerven hun indrukwekkende vaardigheden door enorme hoeveelheden geschreven materiaal op te nemen. Veel van die inhoud is van het openbare internet gescraped, waar het onder strikte licenties kan vallen of gevoelige informatie kan bevatten. In tegenstelling tot traditionele datalekken distribueren AI‑ontwikkelaars echter niet de ruwe data opnieuw; in plaats daarvan wordt die opgenomen in het gedrag van het model. Commerciële systemen tonen dan alleen de gegenereerde tekst, niet hun interne werking of trainingssets. Bestaande forensische technieken om te detecteren of specifieke voorbeelden in de training zijn gebruikt, vertrouwen meestal op interne statistieken zoals token‑kansen, die niet beschikbaar zijn voor diensten zoals GPT‑achtige chatbots. Tegelijkertijd zijn deze modellen afgestemd om teksten niet woordelijk te kopiëren, dus eenvoudige overeenkomsten tussen uw document en de reacties van het model zijn te zwak om als betrouwbaar bewijs te dienen.
Een nieuw idee: informatie‑isotopen
De auteurs lenen een concept uit de scheikunde, waar isotopen licht verschillende versies van hetzelfde element zijn die door reacties te volgen zijn. In tekst is een "semantisch element" een fijnmazig stukje betekenis — zoals een benoemde entiteit, een werkwoord of een specifieke regel broncode. Een "informatie‑isotoop" is een context‑geschikte alternatief die hetzelfde betekent maar er anders uitziet: bijvoorbeeld „New York", „NYC" en „the Big Apple". De belangrijkste empirische bevinding is dat als een taalmodel de oorspronkelijke bewoording tijdens training heeft gezien, het een sterke voorkeur ontwikkelt voor die exacte vorm wanneer het gevraagd wordt te kiezen tussen meerdere, even redelijke varianten in dezelfde context. Voor materiaal waarop het model nooit is getraind, is deze voorkeur veel zwakker, omdat het dan alleen op algemene kennis kan steunen in plaats van direct geheugen.
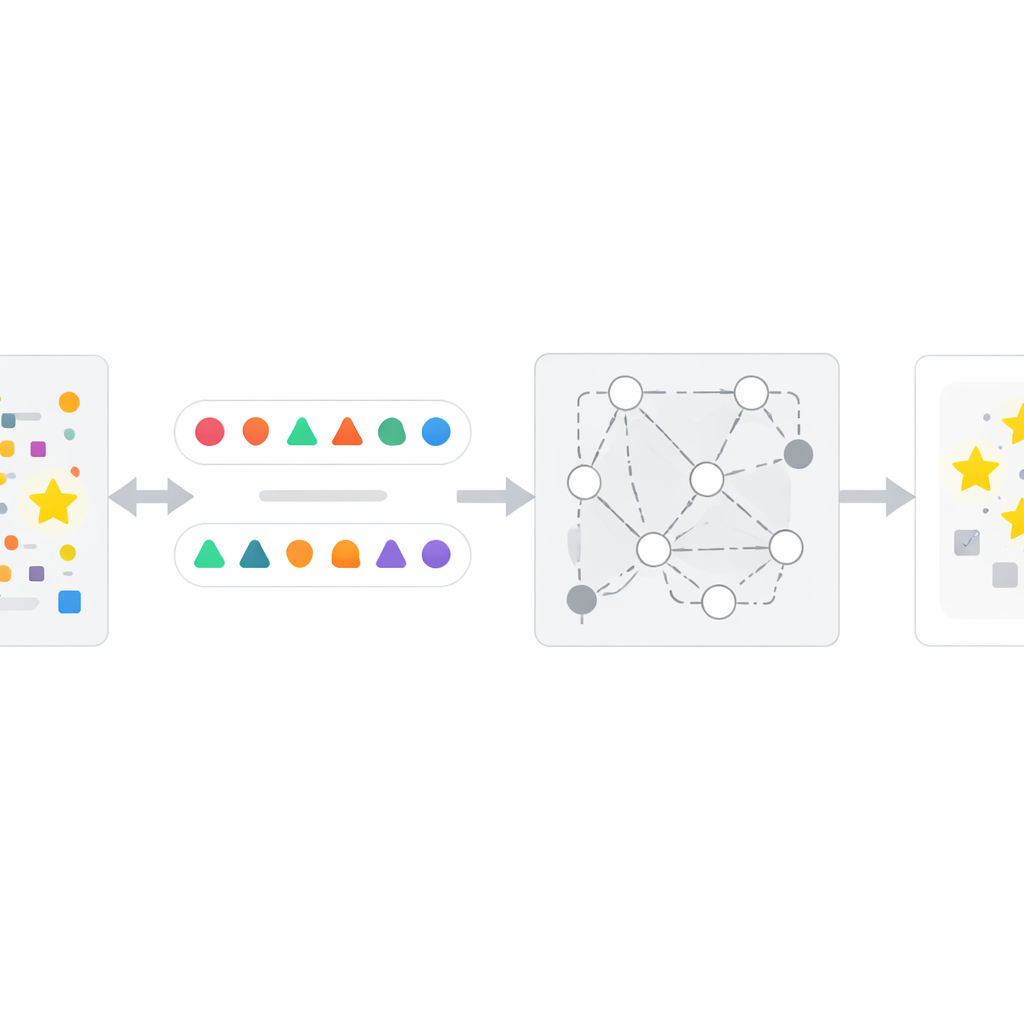
Hoe de InfoTracer‑methode werkt
Voortbouwend op dit inzicht ontwerpen de auteurs een vierstappenraamwerk genaamd InfoTracer. Ten eerste scant het een verdacht stuk tekst — zoals een nieuwsartikel, medisch dossier, boekpassage of codebestand — en splitst het in semantische elementen, met focus op woordsoorten en coderegels die het meest waarschijnlijk een herkenbare geheugenafdruk achterlaten. Ten tweede gebruikt het voor elk gekozen element een afzonderlijk generatief model om meerdere context‑bewuste isotopen te maken: verschillende bewoordingen of codevarianten die nog steeds natuurlijk in de omliggende passage passen. Ten derde filtert het deze kandidaat‑"probes" zodat alleen die overblijven waarbij een menselijke lezer niet gemakkelijk aan de hand van de context kan bepalen welke optie het beste is, waarmee wordt gegarandeerd dat elke sterke voorkeur van de doel‑AI waarschijnlijk voortkomt uit trainingsblootstelling en niet uit gezond verstand. Ten slotte ondervraagt InfoTracer herhaaldelijk de black‑box AI met meerkeuze‑prompts die het oorspronkelijke element maskeren en het vragen een voltooiing uit de isotopenset te kiezen. Door te aggregeren hoe vaak de AI de oorspronkelijke bewoording kiest over veel probes heen, produceert de methode een overall activatiescore die aangeeft of de tekst waarschijnlijk deel uitmaakte van de trainingsdata.
De techniek op de proef gesteld
De onderzoekers evalueren InfoTracer op een brede selectie van open en commerciële taalmodellen, met zorgvuldig geconstrueerde benchmarks waarbij ze redelijkerwijs trainingsvoorbeelden kunnen scheiden van niet‑trainingsvoorbeelden. Op open‑source LLaMA‑modellen met bekende pretrainingdata onderscheidt InfoTracer met zeer hoge nauwkeurigheid member‑ van non‑member‑Wikipedia‑passages, zelfs wanneer slechts korte fragmenten beschikbaar zijn. Wanneer meerdere passages uit dezelfde bron worden gecombineerd, nadert de prestatie snel perfecte scheiding, vaak met minder tekst dan de lengte van een kort artikel. De methode verslaat ook een reeks state‑of‑the‑art concurrenten, inclusief die welke afhankelijk zijn van surrogate‑modellen om het doelsysteem te benaderen, en blijft effectief in veeleisender opstellingen waarin trainings‑ en testdata dezelfde algemene stijl en onderwerpen delen.
Stress‑tests, real‑world modellen en lange teksten
Om echt‑wereldmisbruik na te bootsen testen de auteurs InfoTracer op privacy‑gevoelige medische tekst en auteursrechtelijk beschermd boekmateriaal, evenals code‑repositories, en op meerdere grote commerciële systemen zoals GPT‑3.5, GPT‑4o, Claude, Gemini en andere API's. Zelfs zonder enige kennis van modelarchitectuur of trainingscorpora detecteert InfoTracer betrouwbaar of representatieve datasets uit deze domeinen waarschijnlijk in de training zijn gebruikt, vaak met sterk statistisch bewijs van slechts een paar duizend woorden. Het raamwerk blijkt ook robuust wanneer aanvallers de trainingsdata deels herschrijven of selectief sampelen: hoewel zware herschrijving het signaal kan verzwakken, herstelt de nauwkeurigheid grotendeels wanneer meer tekst beschikbaar is. In een grootschalige demonstratie met meer dan een miljoen woorden verspreid over 21 Chinese romans scheidt InfoTracer duidelijk oudere werken die plausibel in de training zijn gekomen van recente romans die dat waarschijnlijk niet zijn.
Wat dit betekent voor datarechten
Vanuit een niet‑technisch perspectief laat het artikel zien dat zelfs wanneer AI‑systemen ondoorzichtig zijn, hun gedrag nog steeds meetbare vingerafdrukken draagt van de teksten waarop ze zijn getraind. Door slim gebruik te maken van voorkeuren tussen bijna identieke alternatieven, zet InfoTracer deze vingerafdrukken om in gerechtvaardigd bewijs dat een model specifieke bronnen heeft gememoriseerd. De methode vereist geen medewerking van AI‑leveranciers, noch wijzigt ze oorspronkelijke data, waardoor ze geschikt is voor auteurs, instellingen en toezichthouders die mogelijke misbruik willen auditen. Hoewel de huidige experimenten zich op tekst richten, betogen de auteurs dat vergelijkbare ideeën zich zouden kunnen uitstrekken tot audio, beelden en video. Naarmate generatieve AI zich verder uitbreidt naar gevoelige domeinen, zouden dergelijke black‑box audittinstrumenten een hoeksteen kunnen worden voor de handhaving van privacy‑ en auteursrechtregels in de praktijk.
Bronvermelding: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Trefwoorden: AI trainingsdata-audit, informatie-isotopen, gegevensprivacy, auteursrecht en AI, black-box taalmodellen