Clear Sky Science · en
Auditing unauthorized training data from AI generated content using information isotopes
Why this matters for everyday internet users
Modern AI systems learn from huge collections of human-created text—news stories, novels, code, even social media posts. But many of these materials are copyrighted or deeply personal, and AI companies rarely reveal exactly what they used. This paper introduces a practical way for ordinary people, publishers, and regulators to check whether a black-box AI system has been trained on their data, using only its outputs. That makes it a potential game changer for protecting privacy and intellectual property in the age of powerful chatbots.
The problem of hidden training data
Today’s large language models gain their impressive skills by absorbing vast amounts of written material. Much of this content is scraped from the public internet, where it may be covered by strict licenses or contain sensitive information. Unlike traditional data breaches, however, AI developers do not redistribute the raw data; instead, they bake it into model behavior. Commercial systems then expose only generated text, not their internal workings or training sets. Existing forensic techniques for detecting whether specific examples were used in training mostly rely on internal statistics such as token probabilities, which are unavailable for services like GPT-style chatbots. At the same time, these models are tuned to avoid copying passages verbatim, so simple similarity checks between your document and the model’s replies are too weak to serve as reliable evidence.
A new idea: information isotopes
The authors borrow a concept from chemistry, where isotopes are slightly different versions of the same element that can be traced through reactions. In text, a “semantic element” is a fine-grained piece of meaning—such as a named entity, a verb, or a specific line of source code. An “information isotope” is a context-appropriate alternative that means the same thing but looks different: for example, “New York,” “NYC,” and “the Big Apple.” The key empirical finding is that if a language model saw the original wording during training, it develops a strong preference for that exact form when asked to choose among multiple, equally reasonable variants in the same context. For material the model never trained on, this preference is much weaker, because it can only rely on general knowledge instead of direct memory.
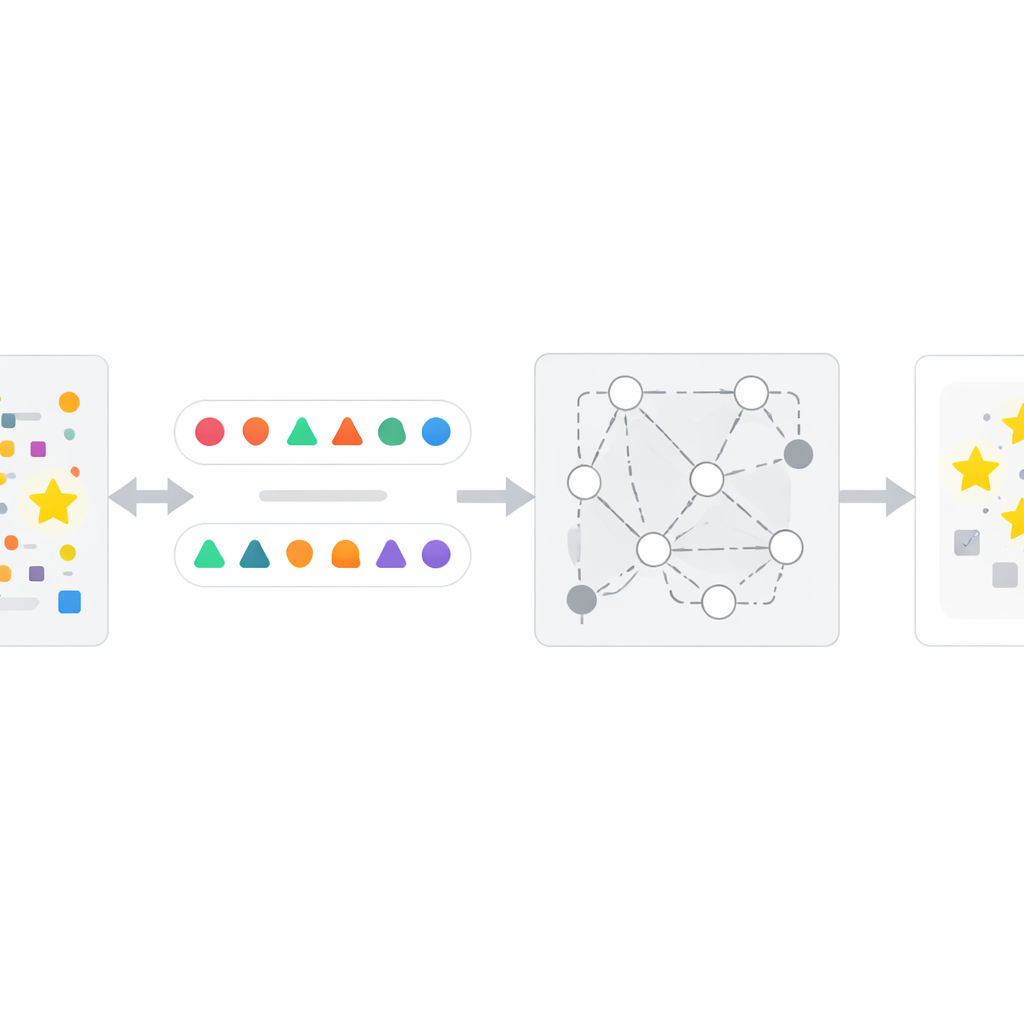
How the InfoTracer method works
Building on this insight, the authors design a four-step framework called InfoTracer. First, it scans a suspected text—such as a news article, medical record, book passage, or code file—and breaks it into semantic elements, focusing on parts of speech and code lines that are most likely to leave a distinctive memory trace. Second, for each chosen element it uses a separate generative model to create several context-aware isotopes: different phrasings or code variants that still fit naturally into the surrounding passage. Third, it filters these candidate “probes” to keep only those where a human-like reader could not easily tell which option is best from context alone, ensuring that any strong preference shown by the target AI is likely due to training exposure rather than common sense. Finally, InfoTracer repeatedly queries the black-box AI with multiple-choice prompts that mask the original element and ask it to pick a completion from the isotope set. By aggregating how often the AI chooses the original wording across many probes, the method produces an overall activation score that signals whether the text was likely part of the training data.
Putting the technique to the test
The researchers evaluate InfoTracer on a wide selection of open and commercial language models, using carefully constructed benchmarks where they can reasonably separate training examples from non-training ones. On open-source LLaMA models with known pretraining data, InfoTracer distinguishes member from non-member Wikipedia passages with very high accuracy, even when only short snippets are available. When multiple passages from the same source are combined, performance quickly approaches perfect separation, often using less than the length of a short paper. The method also beats a range of state-of-the-art competitors, including those that depend on surrogate models to approximate the target system, and remains effective in more demanding setups where training and test data share the same overall style and topics.
Stress tests, real-world models, and long texts
To mimic real-world abuse, the authors test InfoTracer on privacy-sensitive medical text and copyrighted book content, as well as code repositories, and on several major commercial systems such as GPT-3.5, GPT-4o, Claude, Gemini, and other APIs. Even without any knowledge of model architecture or training corpora, InfoTracer reliably detects whether representative datasets from these domains were likely used in training, often with strong statistical evidence from only a few thousand words. The framework also proves robust when attackers partially rewrite or selectively sample the training data: while heavy rewriting can weaken the signal, the method’s accuracy largely recovers when more text is available. In a large-scale demonstration with over a million words spanning 21 Chinese novels, InfoTracer cleanly separates older works that plausibly entered training from recent novels that likely did not.
What this means for data rights
Viewed from a non-technical perspective, the paper shows that even when AI systems are opaque, their behavior still carries measurable fingerprints of the texts they were trained on. By cleverly exploiting preferences among nearly identical alternatives, InfoTracer turns these fingerprints into court-ready evidence that a model has memorized specific sources. The method does not require cooperation from AI providers, nor does it modify original data, making it suitable for authors, institutions, and regulators seeking to audit potential misuse. While current experiments focus on text, the authors argue that similar ideas could extend to audio, images, and video. As generative AI continues to expand into sensitive domains, such black-box auditing tools could become a cornerstone of enforcing privacy and copyright rules in practice.
Citation: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Keywords: AI training data auditing, information isotopes, data privacy, copyright and AI, black-box language models