Clear Sky Science · ar
مراجعة بيانات التدريب غير المصرّح بها من محتوى مُولَّد بواسطة الذكاء الاصطناعي باستخدام نظائر المعلومات
لماذا هذا مهم لمستخدمي الإنترنت العاديين
تعلم أنظمة الذكاء الاصطناعي الحديثة من مجموعات هائلة من النصوص التي أنشأها البشر — مثل الأخبار والروايات والشفرات وحتى منشورات وسائل التواصل الاجتماعي. لكن العديد من هذه المواد محمية بحقوق النشر أو شخصية للغاية، وشركات الذكاء الاصطناعي نادراً ما تكشف بالضبط ما الذي استخدمته. تقدم هذه الورقة طريقة عملية للأشخاص العاديين والناشرين والجهات الرقابية للتحقق مما إذا كان نظام ذكاء اصطناعي صندوق أسود قد تم تدريبه على بياناتهم، باستخدام مخرجاته فقط. وهذا يجعلها تغييراً محتملاً لقواعد اللعبة في حماية الخصوصية والملكية الفكرية في عصر الشات بوتات القوية.
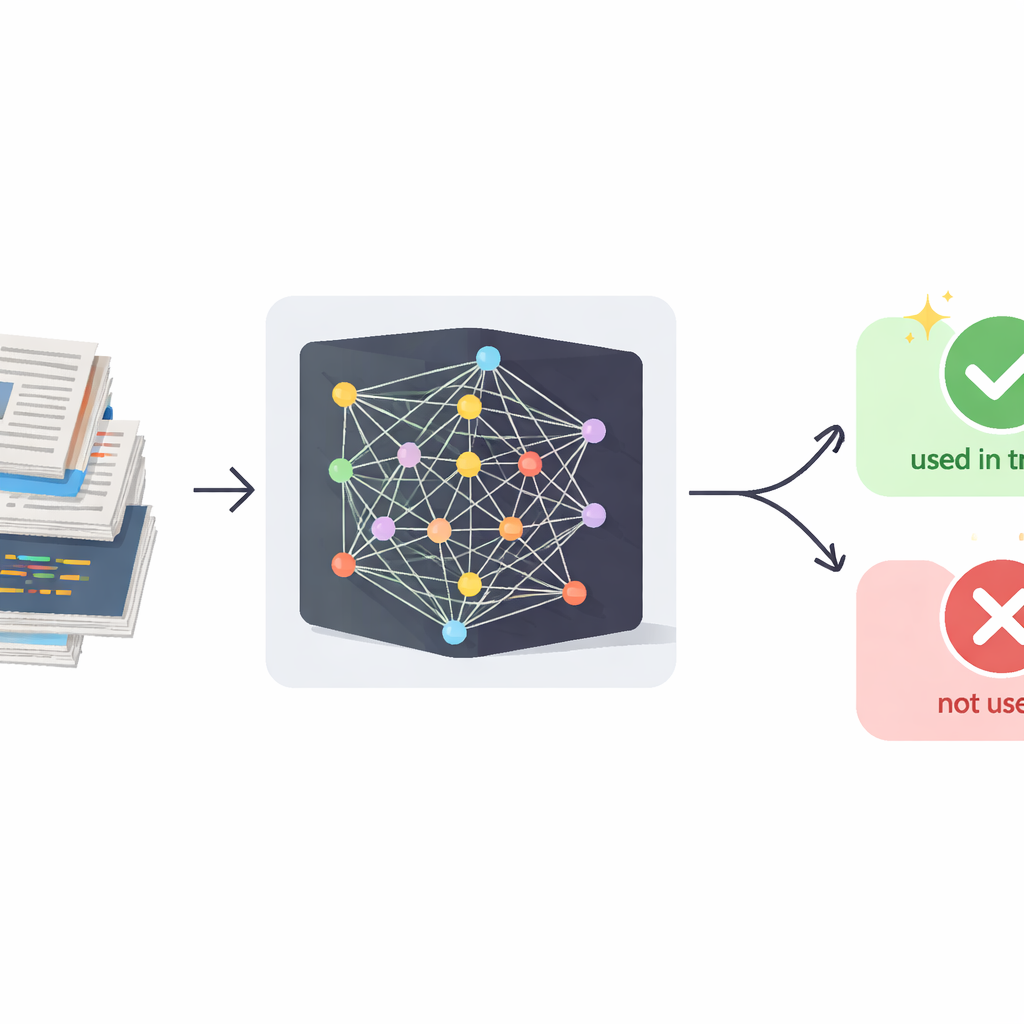
مشكلة بيانات التدريب المخفية
تكتسب نماذج اللغة الكبيرة المعاصرة مهاراتها المذهلة بامتصاص كميات هائلة من المواد المكتوبة. كثير من هذا المحتوى يجري جمعه من الإنترنت العام، حيث قد يخضع لرخص صارمة أو يتضمن معلومات حساسة. خلافاً لخرق البيانات التقليدي، لا يعيد مطورو الذكاء الاصطناعي توزيع البيانات الخام؛ بل يدمجونها في سلوك النموذج. ثم تعرض الأنظمة التجارية نصوصاً مُولَّدة فقط، وليس آلياتها الداخلية أو مجموعات تدريبها. تقنيات الأدلة الجنائية الحالية للكشف عما إذا استُخدمت أمثلة محددة في التدريب تعتمد في الغالب على إحصاءات داخلية مثل احتمالات الرموز، وهي غير متاحة للخدمات مثل الشات بوتات بنمط GPT. في الوقت نفسه، تُعدَّل هذه النماذج لتجنب نسخ المقاطع حرفياً، لذا فإن الفحوص البسيطة للتشابه بين مستندك وردود النموذج ضعيفة جداً لتكون دليلاً موثوقاً.
فكرة جديدة: نظائر المعلومات
يستعير المؤلفون مفهوماً من الكيمياء، حيث تكون النظائر إصدارات مختلفة قليلاً من نفس العنصر يمكن تتبعها عبر التفاعلات. في النص، «العنصر الدلالي» هو قطعة دقيقة من المعنى — مثل كيان مسمّى أو فعل أو سطر محدد من الشيفرة المصدرية. «نظير المعلومات» هو بديل مناسب للسياق يحمل المعنى نفسه لكنه يبدو مختلفاً: على سبيل المثال «نيويورك»، «NYC»، و«التفاحة الكبيرة». النتيجة التجريبية الأساسية هي أنه إذا أعطى نموذج اللغة مثيلاً للصياغة الأصلية أثناء التدريب، فإنه يطوّر تفضيلاً قوياً لتلك الصياغة بالذات عند طلب الاختيار بين عدة بدائل متساوية المعقولية في نفس السياق. بالنسبة للمواد التي لم تُدرّب عليها النموذج، يكون هذا التفضيل أضعف بكثير، لأن النموذج لا يمكنه الاعتماد إلا على معرفة عامة بدلاً من ذاكرة مباشرة.
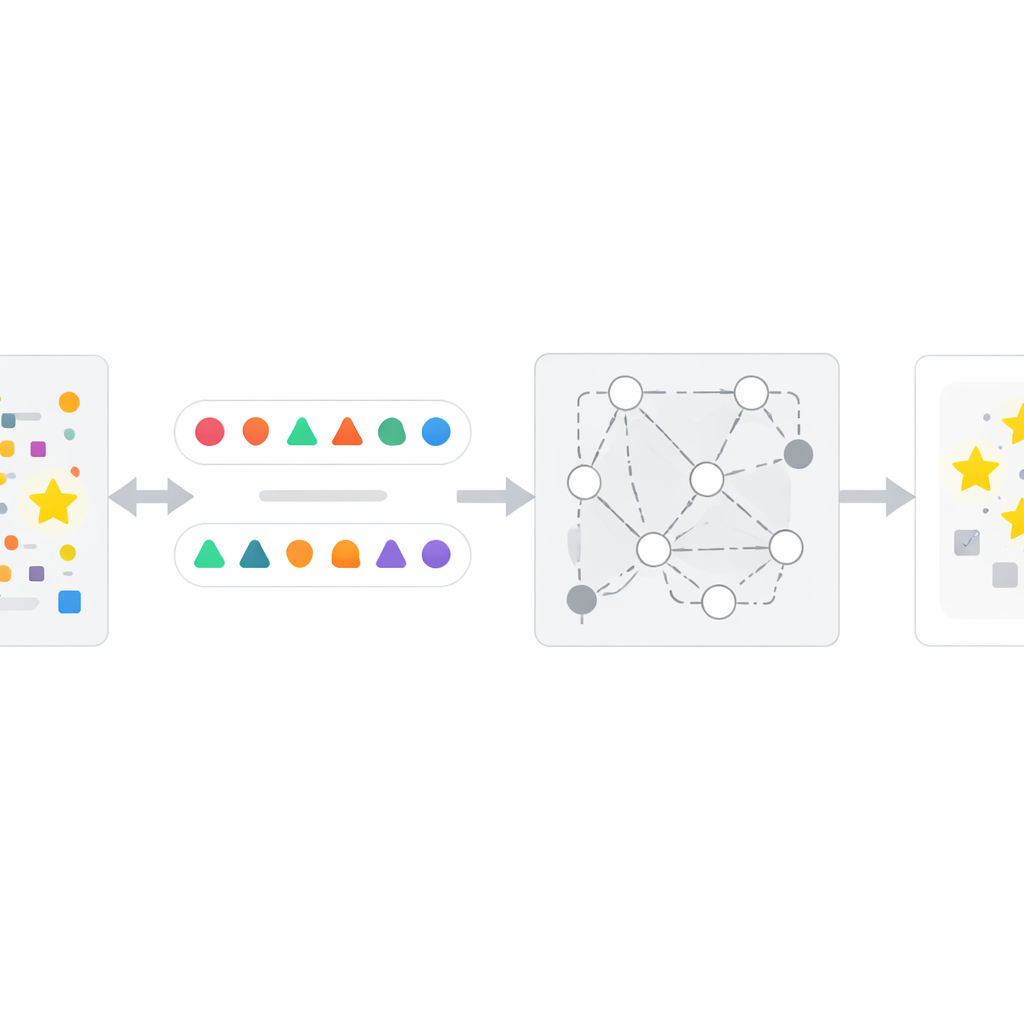
كيف تعمل طريقة InfoTracer
بناءً على هذه البصيرة، يصمم المؤلفون إطار عمل من أربع خطوات يُسمى InfoTracer. أولاً، يفحص النص المشتبه — مثل مقال إخباري أو سجل طبي أو مقطع من كتاب أو ملف شيفرة — ويقسّمه إلى عناصر دلالية، مع التركيز على أجزاء الكلام وسطور الشيفرة التي تُرجَّح أن تترك أثر ذاكرة مميز. ثانياً، لكل عنصر مختار يستخدم نموذجاً توليدياً منفصلاً لإنشاء عدة نظائر ملائمة للسياق: صيغ أو متغيرات شيفرة مختلفة لا تزال تلائم المقطع المحيط طبيعياً. ثالثاً، يفلتر هذه «المجسات» المرشحة ليبقي فقط تلك التي لا يستطيع القارئ البشري بسهولة تحديد أي خيار هو الأفضل من السياق وحده، مما يضمن أن أي تفضيل قوي يظهره الذكاء الاصطناعي الهدف يرجع على الأرجح إلى التعرض في التدريب وليس إلى الحس السليم. أخيراً، يطرح InfoTracer على نموذج الصندوق الأسود مراراً أسئلة اختيار متعدد تُخفي العنصر الأصلي وتطلب منه اختيار إكمال من مجموعة النظائر. من خلال تجميع عدد المرات التي يختار فيها الذكاء الاصطناعي الصياغة الأصلية عبر مجسات عديدة، تنتج الطريقة درجة تفعيل كلية تشير إلى ما إذا كان من المحتمل أن يكون النص جزءاً من بيانات التدريب.
تجريب التقنية
يقيم الباحثون InfoTracer على مجموعة واسعة من نماذج اللغة المفتوحة والتجارية، مستخدمين معايير مصممة بعناية حيث يمكنهم فصل أمثلة التدريب عن غيرها بصورة معقولة. على نماذج LLaMA مفتوحة المصدر ذات بيانات تدريب معروفة، يميّز InfoTracer بين مقاطع ويكيبيديا الأعضاء وغير الأعضاء بدقة عالية جداً، حتى عندما تتوفر مقتطفات قصيرة فقط. عندما تُجمَع مقاطع متعددة من نفس المصدر، يقترب الأداء بسرعة من فصل تام، وغالباً ما يستغرق ذلك أقل من طول ورقة قصيرة. تفوق الطريقة أيضاً مجموعة من المنافسين المتقدمين، بما في ذلك تلك التي تعتمد على نماذج بديلة لتقريب النظام المستهدف، وتظل فعالة في إعدادات أكثر تطلباً حيث تشترك بيانات التدريب والاختبار في نفس الأسلوب والمواضيع عموماً.
اختبارات التحمل، النماذج الواقعية، والنصوص الطويلة
لمحاكاة إساءة الاستخدام في العالم الحقيقي، يختبر المؤلفون InfoTracer على نصوص طبية حساسة للخصوصية ومحتوى كتب محمية بحقوق النشر، وكذلك مستودعات شيفرة، وعلى عدة أنظمة تجارية كبرى مثل GPT-3.5 وGPT-4o وClaude وGemini وواجهات برمجة تطبيقات أخرى. حتى من دون أي معرفة بهندسة النموذج أو قواميس التدريب، يكتشف InfoTracer بشكل موثوق ما إذا كانت مجموعات بيانات ممثلة من هذه المجالات قد استُخدمت على الأرجح في التدريب، وغالباً بدليل إحصائي قوي من بضعة آلاف كلمة فقط. يثبت الإطار أيضاً متانته عندما يقوم المهاجمون بإعادة كتابة جزئية أو أخذ عينات انتقائية من بيانات التدريب: فعلى الرغم من أن إعادة الكتابة الشديدة قد تضعف الإشارة، إلا أن دقة الطريقة تتعافى إلى حد كبير عندما تتوافر نصوص أكثر. في عرض تجريبي واسع النطاق شمل أكثر من مليون كلمة موزعة على 21 رواية صينية، يميّز InfoTracer بوضوح أعمالاً أقدم ربما دخلت في التدريب عن روايات حديثة من غير المرجح أنها دخلت.
ما الذي يعنيه ذلك لحقوق البيانات
من منظور غير تقني، تُظهر الورقة أنه حتى عندما تكون أنظمة الذكاء الاصطناعي معتمة، يحمل سلوكها بصمات قابلة للقياس من النصوص التي دُرِّبت عليها. من خلال استغلال التفضيلات بين بدائل متقاربة الشكل بذكاء، يحول InfoTracer هذه البصمات إلى دليل يمكن تقديمه أمام المحاكم بأن النموذج قد حفظ مصادر محددة. لا تتطلب الطريقة تعاون مزودي الذكاء الاصطناعي، ولا تُعدِّل البيانات الأصلية، مما يجعلها مناسبة للمؤلفين والمؤسسات والهيئات الرقابية الساعية إلى مراجعة الاستخدام المحتمل المسئ. بينما تركز التجارب الحالية على النص، يجادل المؤلفون بأن أفكاراً مماثلة يمكن أن تمتد إلى الصوت والصور والفيديو. ومع استمرار توسع الذكاء الاصطناعي التوليدي في مجالات حساسة، يمكن أن تصبح أدوات التدقيق للصندوق الأسود هذه حجر أساس لتنفيذ قواعد الخصوصية وحقوق النشر عملياً.
الاستشهاد: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
الكلمات المفتاحية: مراجعة بيانات تدريب الذكاء الاصطناعي, نظائر المعلومات, خصوصية البيانات, الحقوق الفكرية والذكاء الاصطناعي, نماذج اللغة الصندوق الأسود