Clear Sky Science · sv
Revidera obehörig träningsdata från AI-genererat innehåll med hjälp av informationsisotoper
Varför detta är viktigt för vardagliga internetanvändare
Moderna AI-system lär sig från enorma samlingar av människoskapad text—nyhetsartiklar, romaner, kod och till och med inlägg i sociala medier. Men många av dessa material är upphovsrättsskyddade eller djupt personliga, och AI-företag avslöjar sällan exakt vad de använt. Denna artikel presenterar ett praktiskt sätt för vanliga människor, publicister och tillsynsmyndigheter att kontrollera om ett black-box AI-system har tränats på deras data, enbart genom att använda dess utskrifter. Det gör metoden till en potentiell spelväxlare för att skydda integritet och immateriella rättigheter i åldern av kraftfulla chattbotar.
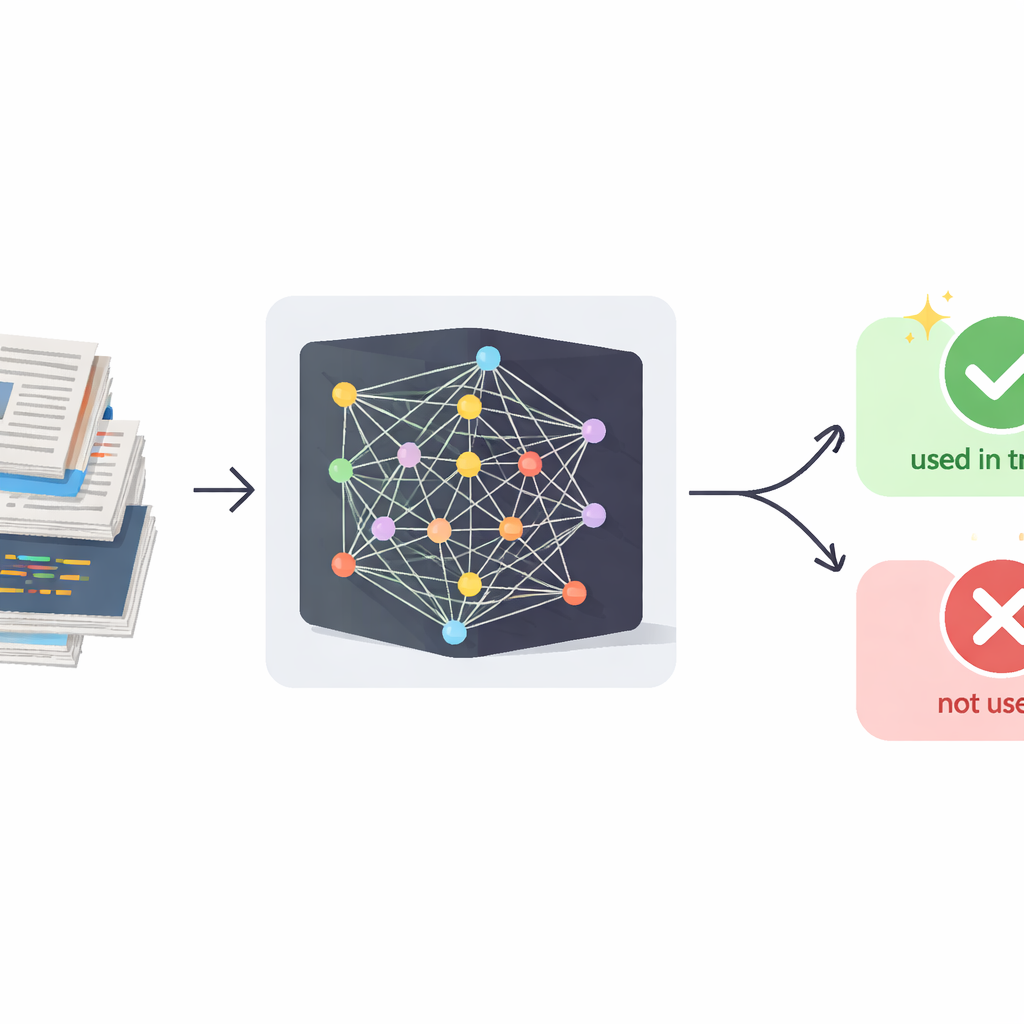
Problemet med dold träningsdata
Dagens stora språkmodeller får sina imponerande färdigheter genom att absorbera stora mängder skrivet material. Mycket av detta innehåll skrapas från den publika internet, där det kan omfattas av strikta licenser eller innehålla känslig information. Till skillnad från traditionella dataintrång återdelar dock AI-utvecklare inte rådata; istället bakas den in i modellens beteende. Kommersiella system exponerar sedan endast genererad text, inte sina interna processer eller träningsuppsättningar. Befintliga rättsmedicinska tekniker för att upptäcka om specifika exempel användes i träningen förlitar sig oftast på interna statistiska mått som token-sannolikheter, vilka inte är tillgängliga för tjänster som GPT-liknande chattbotar. Samtidigt är dessa modeller finjusterade för att undvika att kopiera stycken ordagrant, så enkla likhetskontroller mellan ditt dokument och modellens svar är för svaga för att fungera som pålitliga bevis.
En ny idé: informationsisotoper
Författarna lånar ett begrepp från kemin, där isotoper är något olika varianter av samma grundämne som kan spåras genom reaktioner. I text är ett “semantiskt element” en finfördelad beståndsdel av betydelse—såsom en namngiven entitet, ett verb eller en specifik kodrad. En “informationsisotop” är ett kontext-appropriate alternativ som betyder samma sak men ser annorlunda ut: till exempel “New York”, “NYC” och “The Big Apple”. Den centrala empiriska iakttagelsen är att om en språkmodell såg den ursprungliga formuleringen under träningen utvecklar den en stark preferens för just den formen när den får välja bland flera lika rimliga varianter i samma kontext. För material modellen aldrig tränats på är denna preferens mycket svagare, eftersom den då bara kan lita på generell kunskap snarare än direkt minne.
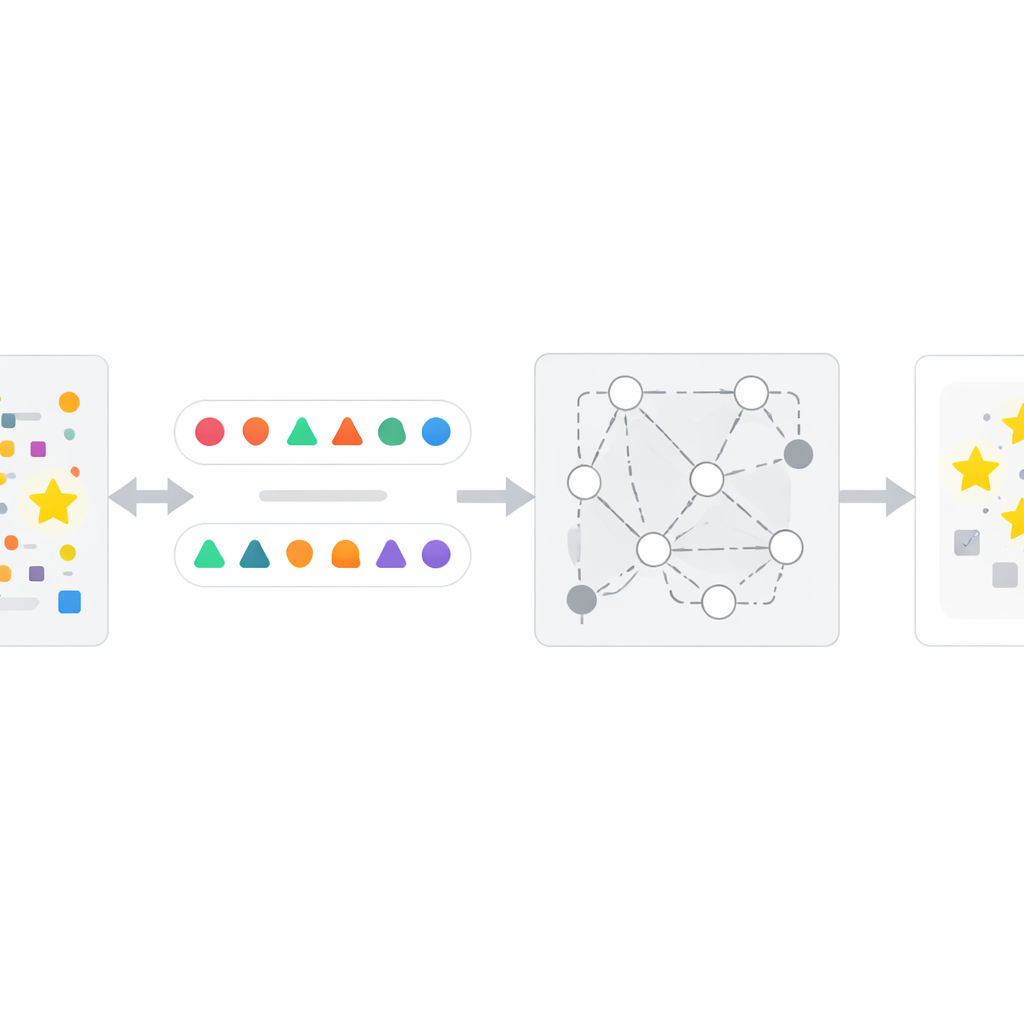
Hur InfoTracer-metoden fungerar
Med utgångspunkt i denna insikt utformar författarna ett fyrastegsramverk kallat InfoTracer. Först skannar det en misstänkt text—som en nyhetsartikel, journalhandling, bokutdrag eller kodfil—och bryter ner den i semantiska element, med fokus på satsdelar och kodrader som sannolikt lämnar ett distinkt minnesspår. För det andra använder man för varje valt element en separat generativ modell för att skapa flera kontextmedvetna isotoper: olika formuleringar eller kodvarianter som fortfarande passar naturligt in i omgivande passage. För det tredje filtrerar man dessa kandidat-”prober” för att behålla endast de där en mänsklig läsare inte lätt kan avgöra vilken option som är bäst enbart utifrån kontexten, vilket säkerställer att en stark preferens som visas av målsystemet sannolikt beror på träningsexponering snarare än sunt förnuft. Slutligen frågar InfoTracer upprepade gånger den svarta lådan med flervals-promptar som maskerar det ursprungliga elementet och ber den välja en fortsättning från isotopuppsättningen. Genom att aggregera hur ofta AI:n väljer ursprungsformuleringen över många prober ger metoden en samlad aktiveringspoäng som signalerar om texten sannolikt ingått i träningsdata.
Sätta tekniken på prov
Forskarna utvärderar InfoTracer på ett brett urval av öppna och kommersiella språkmodeller, med noggrant konstruerade benchmarks där de rimligen kan separera träningsexempel från icke-träningsexempel. På öppen källkod LLaMA-modeller med känd förträningsdata skiljer InfoTracer medlems- från icke-medlemsartiklar från Wikipedia med mycket hög noggrannhet, även när endast korta utdrag finns tillgängliga. När flera utdrag från samma källa kombineras närmar sig prestandan snabbt perfekt separation, ofta med mindre text än längden på en kort vetenskaplig artikel. Metoden överträffar också en rad toppmoderna konkurrenter, inklusive sådana som förlitar sig på surrogatmodeller för att approximera målsystemet, och förblir effektiv i mer krävande uppsättningar där tränings- och testdata delar samma övergripande stil och ämnen.
Stresstester, verkliga modeller och långa texter
För att efterlikna verkligt missbruk testar författarna InfoTracer på integritetskänsliga medicinska texter och upphovsrättsskyddat bokinnehåll, liksom kodförråd, och på flera stora kommersiella system såsom GPT-3.5, GPT-4o, Claude, Gemini och andra API:er. Även utan någon kunskap om modellarkitektur eller träningskorpora upptäcker InfoTracer pålitligt om representativa dataset från dessa domäner sannolikt användes i träningen, ofta med stark statistisk bevisning från endast några tusen ord. Ramverket visar sig också robust när angripare delvis skriver om eller selektivt sampelar träningsdatan: medan kraftig omskrivning kan försvaga signalen återhämtar sig metodens noggrannhet till stor del när mer text finns tillgänglig. I en storskalig demonstration med över en miljon ord som spänner över 21 kinesiska romaner separerar InfoTracer tydligt äldre verk som sannolikt ingick i träningen från nyare romaner som troligen inte gjorde det.
Vad detta betyder för datarättigheter
Ur ett icke-tekniskt perspektiv visar artikeln att även när AI-system är ogenomskinliga bär deras beteende ändå mätbara fingeravtryck av de texter de tränats på. Genom att smart utnyttja preferenser mellan nästan identiska alternativ förvandlar InfoTracer dessa fingeravtryck till domstolsvänliga bevis för att en modell har memoriserat specifika källor. Metoden kräver varken samarbete från AI-leverantörer eller modifiering av ursprungsdata, vilket gör den lämplig för författare, institutioner och tillsynsmyndigheter som vill granska potentiellt missbruk. Medan nuvarande experiment fokuserar på text argumenterar författarna för att liknande idéer kan utsträckas till ljud, bilder och video. När generativ AI fortsätter att expandera in i känsliga domäner kan sådana black-box-revisionsverktyg bli en hörnsten för att verkställa integritets- och upphovsrättsregler i praktiken.
Citering: Qi, T., Yin, J., Cai, D. et al. Auditing unauthorized training data from AI generated content using information isotopes. Nat Commun 17, 3007 (2026). https://doi.org/10.1038/s41467-026-68862-x
Nyckelord: Revision av AI-träningsdata, informationsisotoper, datasekretess, upphovsrätt och AI, black-box språkmodeller