Clear Sky Science · sv
Utvärdering av noggrannheten hos ChatGPT-modellversioner för att ge råd om vårdsökande
Varför denna studie spelar roll för vardagliga hälsoval
Fler och fler vänder sig till verktyg som ChatGPT med en till synes enkel fråga: ”Behöver jag åka till akuten, träffa en läkare, eller kan jag stanna hemma och vänta?” Denna studie sätter 22 versioner av ChatGPT på prov i just det beslutet. Resultaten berör alla som överväger att förlita sig på artificiell intelligens istället för att ringa en mottagning, en sjukvårdsrådgivning eller en betrodd läkare.
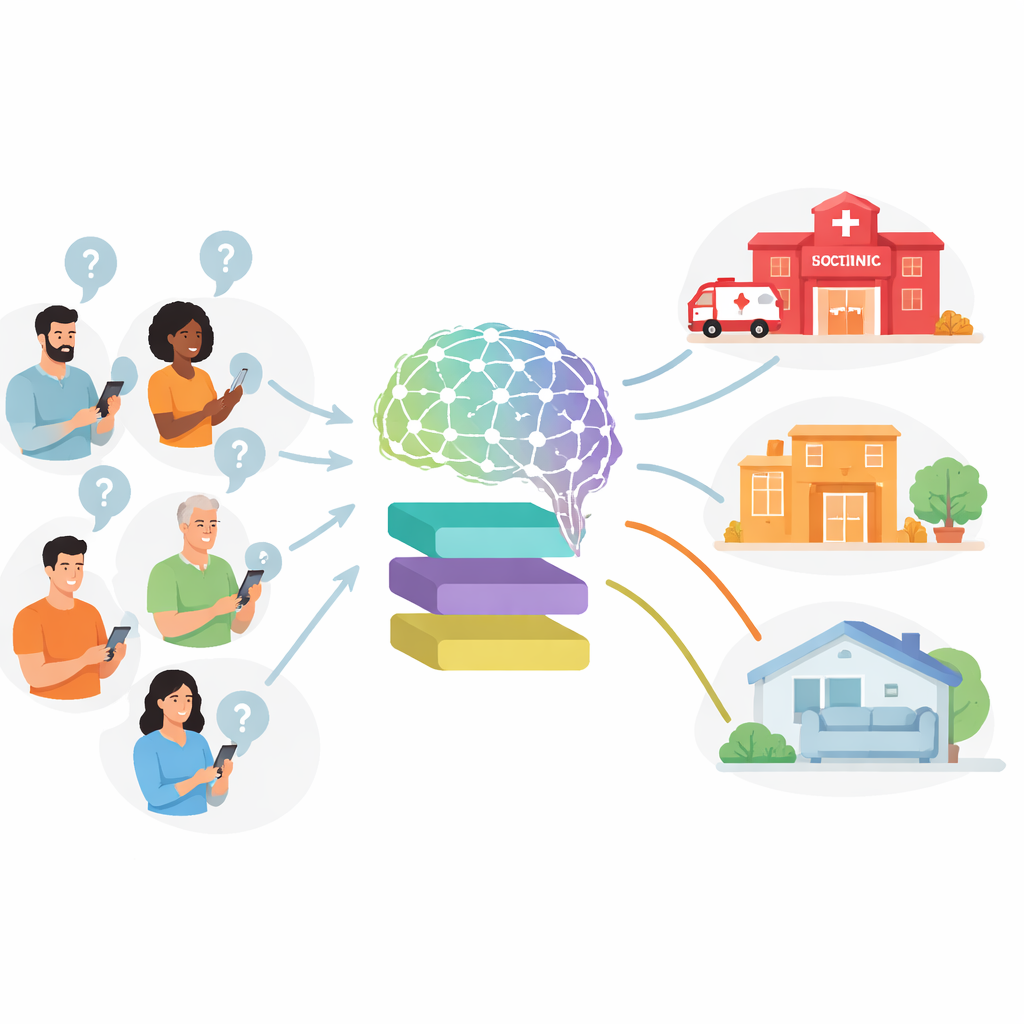
Hur forskarna testade ChatGPT:s medicinska råd
I stället för verkliga patienter använde teamet 45 noggrant utformade patientberättelser, eller vignetter, hämtade från verkliga personer som gått online för att fråga var de borde söka vård. Varje berättelse hade redan bedömts av två läkare, som var överens om huruvida den krävde akut behandling, ett icke-brådskande läkarbesök eller enkel egenvård hemma. Forskarna bad sedan varje tillgänglig ChatGPT-version — inklusive äldre modeller och nyare ”resonerande” modeller — att välja ett av dessa tre alternativ. För att se hur konsekventa modellerna var upprepade de processen tio gånger per fall och per modell, vilket resulterade i 9 900 separata rekommendationer.
Hur träffsäkra var de olika ChatGPT-versionerna?
Den bäst presterande modellen i studien, kallad o1-mini, valde rätt alternativ i ungefär tre fjärdedelar av fallen (74 %). Några mindre eller lättviktigare modeller klarade sig märkbart sämre, med noggrannheten nere på omkring 44 %. Nästan alla modeller var mycket bra på att upptäcka akuta tillstånd; med de begränsade antalet akuta exempel som fanns, föreslog de nästan alltid brådskande vård när det verkligen behövdes. De var också starka för typiska icke-akuta läkarbesök. Den största svårigheten gällde egenvård. Även de bättre modellerna rekommenderade ofta att träffa en läkare när vila, att avvakta symtom och vänta några dagar hade varit lämpligt.
Varför ChatGPT tenderar att ”spela säkert”
Överlag lutade modellerna åt mer brådskande råd än vad läkarna bedömde som nödvändigt. Äldre versioner rekommenderade nästan aldrig för liten vård, och många av de nyare valde fortfarande kraftigt för försiktighet. Ur ett säkerhetsperspektiv kan en försiktighetsinriktning verka betryggande: det är i allmänhet bättre att skicka någon till en läkare än att missa en verklig nödsituation. Men om ett system i princip alltid rekommenderar någon form av medicinskt besök blir dess vägledning mindre användbar för vardagsbeslut — och kan bidra till trängsel på mottagningar och akutmottagningar. Det kan också öka oro hos redan bekymrade personer, genom att lära dem att även lindriga symtom alltid kräver professionell uppmärksamhet.
Att använda inkonsekvens för att förbättra råd
Överraskande nog gav samma ChatGPT-modell inte alltid samma svar när den fick samma patientberättelse. Över flera körningar växlade vissa modeller mellan olika brådskandenivåer för samma fall. I stället för att betrakta denna inkonsekvens enbart som ett fel försökte forskarna utnyttja den. De kombinerade de tio upprepade svaren för varje fall på flera sätt. När de valde det minst brådskande förslaget som dök upp bland de tio körningarna ökade den övergripande noggrannheten med cirka fyra procentenheter, och korrekta rekommendationer om egenvård ökade ännu mer. Med andra ord, när en modell ibland rekommenderade egenvård och ibland ett läkarbesök för samma milda fall, förde tillit till det lägsta brådskande förslaget ofta rådet närmare läkarnas bedömning.
Vad detta betyder för personer som använder AI för hälsobeslut
Studien visar i korthet att nuvarande ChatGPT-modeller kan vara användbara för att känna igen uppenbara akutfall, men de är ännu inte tillräckligt tillförlitliga för att ensamma vägleda beslut om var man ska söka vård — särskilt när valet står mellan att träffa en läkare och att stanna hemma. Nyare ”resonerande” modeller är mer benägna och något bättre på att känna igen när egenvård räcker, men deras prestanda är fortfarande långt från perfekt. Metoder som kombinerar flera svar från samma modell kan hjälpa utvecklare att bygga säkrare verktyg i framtiden. För tillfället bör man betrakta ChatGPT:s triage-liknande råd som ett av flera underlag, inte som en ersättning för lokala akutinstruktioner, professionell medicinsk rådgivning eller eget sunt förnuft.
Citering: Kopka, M., He, L. & Feufel, M.A. Evaluating the accuracy of ChatGPT model versions for giving care-seeking advice. Commun Med 6, 171 (2026). https://doi.org/10.1038/s43856-026-01466-0
Nyckelord: chatgpt, självtriage, akutvård, hälsor råd, artificiell intelligens