Clear Sky Science · sv
Dual asymmetric momentum förbättrar federerat klass‑unlearning i kant‑system
Varför det är viktigt att lära maskiner att glömma
Våra telefoner, klockor och hemapparater lär ständigt av den data vi ger dem, från foton och röstklipp till hälsomätningar. Men vad händer när lagar eller användare kräver att viss information måste raderas, inte bara från lagringen utan också från det beteende som AI‑modellerna uppvisar? Att träna om dessa modeller från början kan vara långsamt, dyrt och ibland orealistiskt på miljontals små enheter. Den här artikeln utforskar ett lättare sätt att få stora, distribuerade inlärningssystem att ”glömma” utvalda uppgifter samtidigt som de fortfarande fungerar bra för allt annat.
Lära tillsammans utan att dela din data
Många moderna system använder federated learning, där en central server koordinerar träningen medan rådata stannar på varje enhet. Telefoner eller sensorer uppdaterar en delad modell med sin lokala data och skickar sedan bara tillbaka modellförändringar. Denna utformning hjälper till att skydda integriteten och sparar bandbredd, men tar inte bort all risk. Modellen kan fortfarande bära spår av vem eller vad den har sett, och forskning visar att skickliga attacker ibland kan avgöra om specifik data användes vid träningen. Växande integritetsregler, som Europas rätt att bli glömd, har därför skapat tryck för ”machine unlearning”-procedurer som minskar en modells beroende av utpekad data, till exempel en klass bilder eller en viss användargrupp.
Varför unlearning i verkligheten är så svårt
I teorin är den renaste lösningen att kasta bort den oönskade datan och träna om modellen från början med enbart resterande information. I praktiken innebär full omträning enorma kommunikationskostnader, upprepad koordinering mellan många klienter och långa körtider, särskilt när data är ojämnt fördelade över enheterna. Dessutom kan försöket att glömma en kunskap försämra prestanda på allt annat, eftersom samma modellparametrar stöder båda. Författarna visar att den interna träningsmaskineriet, särskilt optimizers momentum‑tillstånd som jämnar ut uppdateringar över tid, kan blanda ihop ”glömma”‑ och ”behålla”‑signaler så att försök att radera en klass stör modellens övriga förmågor.
En lätt tilläggs‑head för att glömma
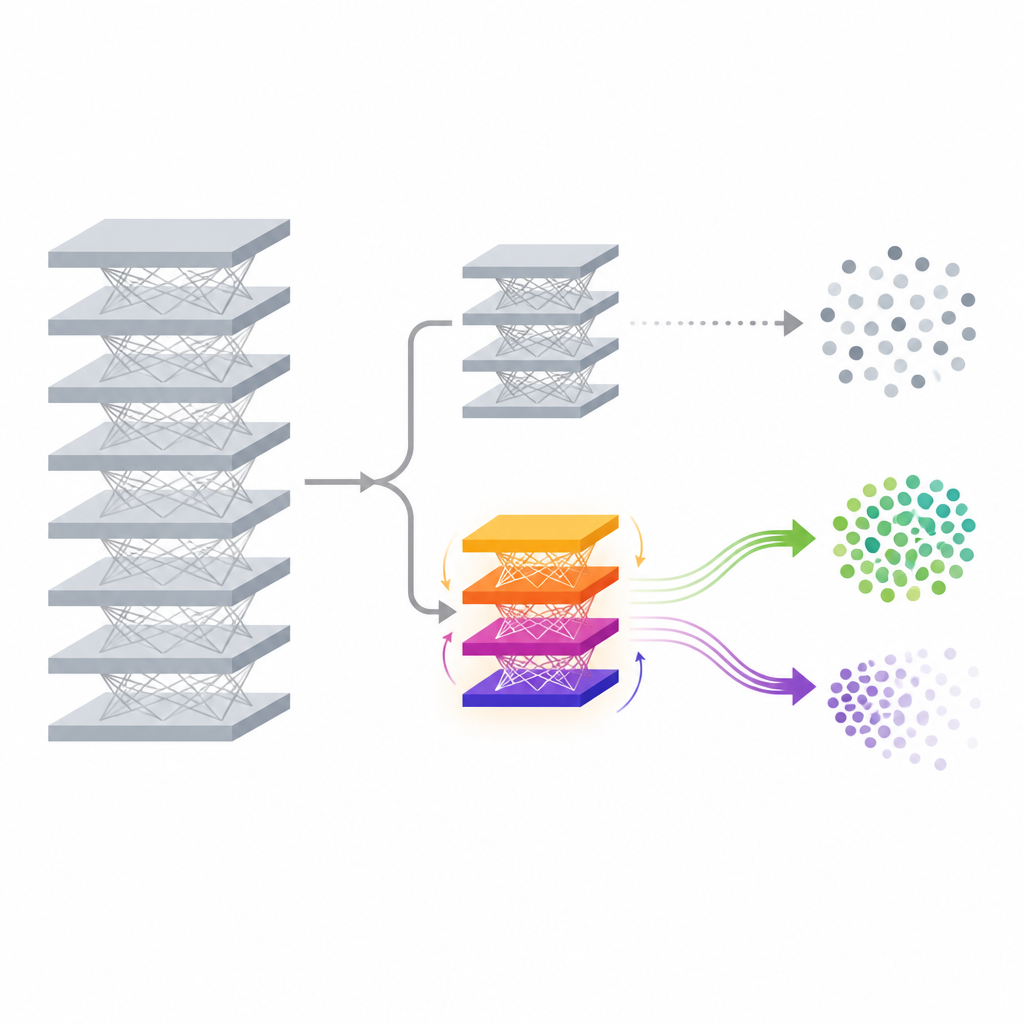
Den föreslagna metoden, kallad FedDAM, tar itu med dessa utmaningar genom att ändra endast en liten del av modellen efter att den redan tränats. Huvudnätverket som extraherar funktioner från data och dess ursprungliga klassificerare fryses på plats. Ovanpå dem lägger författarna till en ny, liten ”auxiliary head” vars uppgift är att finjustera de slutliga prediktionerna på ett kontrollerat sätt. Under unlearning uppdateras och delas endast denna auxiliary head mellan enheterna, vilket kraftigt minskar kommunikation och beräkning jämfört med att träna om hela modellen. Genom att arbeta direkt på nivån för slutpoängen kan metoden flytta beslutsgränser för en målklass medan den djupa feature‑extractorn förblir orörd, vilket gör den attraktiv för resurssvaga telefoner och kant‑enheter.
Två minnesströmmar för att behålla och glömma
Den centrala tekniska idén i FedDAM är att separera de krafter som vill glömma från dem som vill bevara kunskap. Varje deltagande klient delar upp sin lokala data i ”retain” och ”forget”‑set och alternerar sedan uppdateringar baserade på vardera. Istället för att mata båda in i ett enda momentum‑tillstånd behåller metoden två skilda momentum‑buffertar, en för bevarande och en för glömska, och kombinerar dem asymmetriskt när auxiliary head uppdateras. Glömskeuppdateringar får kortare minne och något högre vikt, så modellen reagerar snabbt när den ser data som ska raderas, samtidigt som den fortfarande lyssnar på den tystare dragningen från den behållna datan. Genom experiment visar författarna att denna dubbla ström minskar direkt konflikt mellan de två målen och anpassar uppdateringarna närmare det avsedda glömningsbeteendet.
Hur väl fungerar selektiv glömska i praktiken
Teamet testar FedDAM på standardbildsdatamängder, inklusive CIFAR‑10, CIFAR‑100 och en medelstor ImageNet‑100‑uppställning, under realistiska federerade förhållanden där varje klient bara har en skiva av datan och vissa klienter kanske inte har några exempel som ska glömmas. De jämför sin metod med flera alternativ som antingen använder ett enda delat momentum, projicerar konflikterande gradienter eller rensar överlappande riktningar, samt med komprimerad full omträning av modellen. I dessa studier uppnår FedDAM konsekvent bättre noggrannhet på de behållna klasserna vid liknande nivåer av glömska, med vinster på runt 7 till 9 procentenheter på svårare, mer diversifierade datamängder. Samtidigt använder den mycket mindre kommunikation och körtid än full omträning, även när denna är kraftigt komprimerad.
Vad detta innebär för vardagliga enheter
För icke‑specialister är huvudbudskapet att det är möjligt att utforma inlärningssystem som senare kan ”glömma” vissa kategorier av data mer flexibelt, utan att börja om och utan att alltför mycket skada prestandan på allt annat. FedDAM erbjuder ett praktiskt recept för att göra detta i federerade och kant‑miljöer genom att frysa större delen av modellen, justera endast en liten auxiliary head och noggrant separera influenserna från data vi vill behålla från data vi vill glömma. Medan det inte ger formella integritetsgarantier och inte kan hantera alla typer av borttagningsförfrågningar, erbjuder tillvägagångssättet en användbar mittväg mellan att göra ingenting och att betala hela priset för omträning, och hjälper till att föra idén om machine unlearning närmare verklig användning.
Citering: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Nyckelord: federated learning, machine unlearning, edge computing, privacy in AI, neural networks