Clear Sky Science · he
מומנטום אסימטרי כפול משפר ביטול למידה מקוטבת בפדרציה במערכות קצה
מדוע חשוב ללמד מכונות לשכוח
הטלפונים, השעונים והגאדג'טים הביתיים שלנו לומדים בהתמדה מהנתונים שאנחנו מספקים — מתמונות וקליפים קוליים ועד קריאות בריאות. אבל מה קורה כשחוקים או משתמשים דורשים שמידע מסוים יימחק, לא רק מהאחסון אלא מההתנהגות עצמה של דגמי ה-AI? לאמן מחדש את כל המודלים מאפס יכול להיות איטי, יקר ולעתים לא אפשרי במיליוני מכשירים זעירים. המאמר בוחן דרך קלילה יותר לגרום למערכות למידה מבוזרות וגדולות «לשכוח» מידע נבחר ועדיין לתפקד היטב בכל השאר.
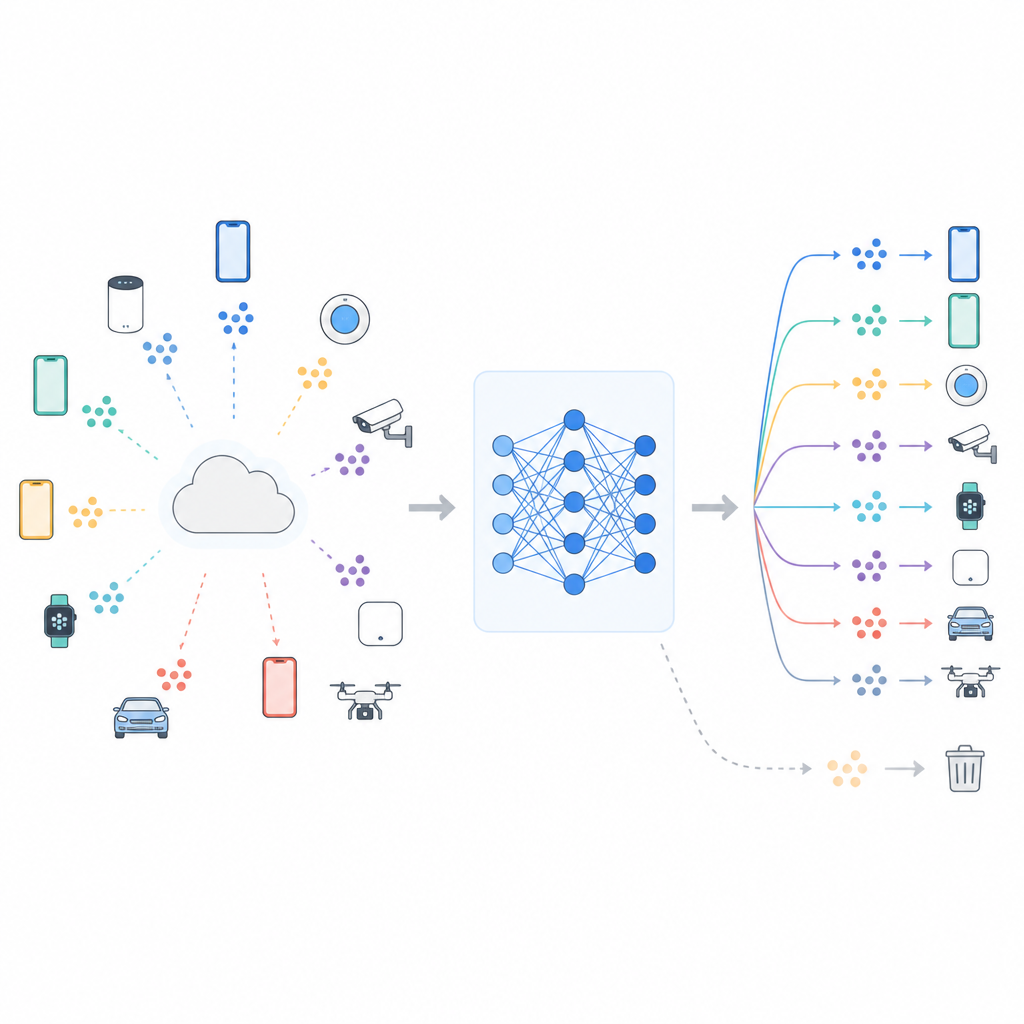
ללמוד יחד בלי לשתף את הנתונים שלך
מערכות מודרניות רבות משתמשות בלמידה פדרטיבית, שבה שרת מרכזי מתאם את האימון בעוד הנתונים הגולמיים נשארים על כל מכשיר. טלפונים או חיישנים מעדכנים מודל משותף באמצעות הנתונים המקומיים שלהם ואז שולחים רק את השינויים במודל בחזרה. הסידור הזה מסייע בהגנת פרטיות וחוסך רוחב פס, אך אינו מבטל את כל הסיכון. המודל עדיין עלול לשאת עקבות של מי או מה נצפה, ומחקר הראה שתקיפות חכמות יכולות לפעמים לגלות האם נתון ספציפי שימש לאימון. כללים מתרחבים לפרטיות כגון הזכות להישכח באירופה יצרו לכן לחץ לפתרונות של ‘‘שכחת מכונה’’ שמפחיתים את תלות המודל בנתונים מסומנים, כמו כיתה של תמונות או קבוצת משתמשים מסוימת.
מדוע השכחה בעולם האמיתי קשה כל כך
בתיאוריה, הפתרון הנקי ביותר הוא למחוק את הנתונים הלא רצויים ולאמן את המודל מחדש מאפס על בסיס המידע הנותר בלבד. בפועל, אימון מלא מחדש משמעותו עלויות תקשורת עצומות, תיאום חוזר בין רבים מהלקוח, וזמני ריצה ארוכים, במיוחד כאשר הנתונים מפוזרים בצורה לא אחידה על פני המכשירים. נוסף על כך, ניסיון ‘‘לשכוח’’ ידע אחד יכול לפגוע בביצועים בכל השאר, כי אותם פרמטרים תומכים בשניהם. המחברים מראים שמנגנון האימון הפנימי, ובמיוחד מצב המומנטום של המיטב (optimizer) שמחליק עדכונים לאורך זמן, יכול לערבב יחד אותות של ‘‘שכחה’’ ו‘‘שימור’’ כך שמאמצים למחיקה יתנגשו עם כישורי המודל האחרים.
תוספת קלה בראש הרשת לשכחה
השיטה המוצעת, המכונה FedDAM, מתמודדת עם האתגרים האלה על ידי שינוי חלק קטן בלבד של המודל לאחר שאומן כבר. רשת התכונות הראשית וממיין המקוריים מוקפאים במקומם. מעליהם מוסיפים המחברים «ראש עזר» קטן חדש שתפקידו לכוונן את התחזיות הסופיות בצורה מבוקרת. במהלך תהליך השכחה רק ראש העזר הוא שמתעדכן ומשותף בין המכשירים, מה שמצמצם משמעותית את התקשורת והחישוב בהשוואה לאימון מלא מחדש. באמצעות עבודה ישירה על רמת הנקודות הסופיות, השיטה יכולה להזיז גבולות החלטה עבור כיתה יעד בזמן שמשאבת המאפיינים העמוקה נשארת ללא שינוי, מה שהופך אותה לאטרקטיבית עבור טלפונים ומכשירי קצה מוגבלי משאבים.
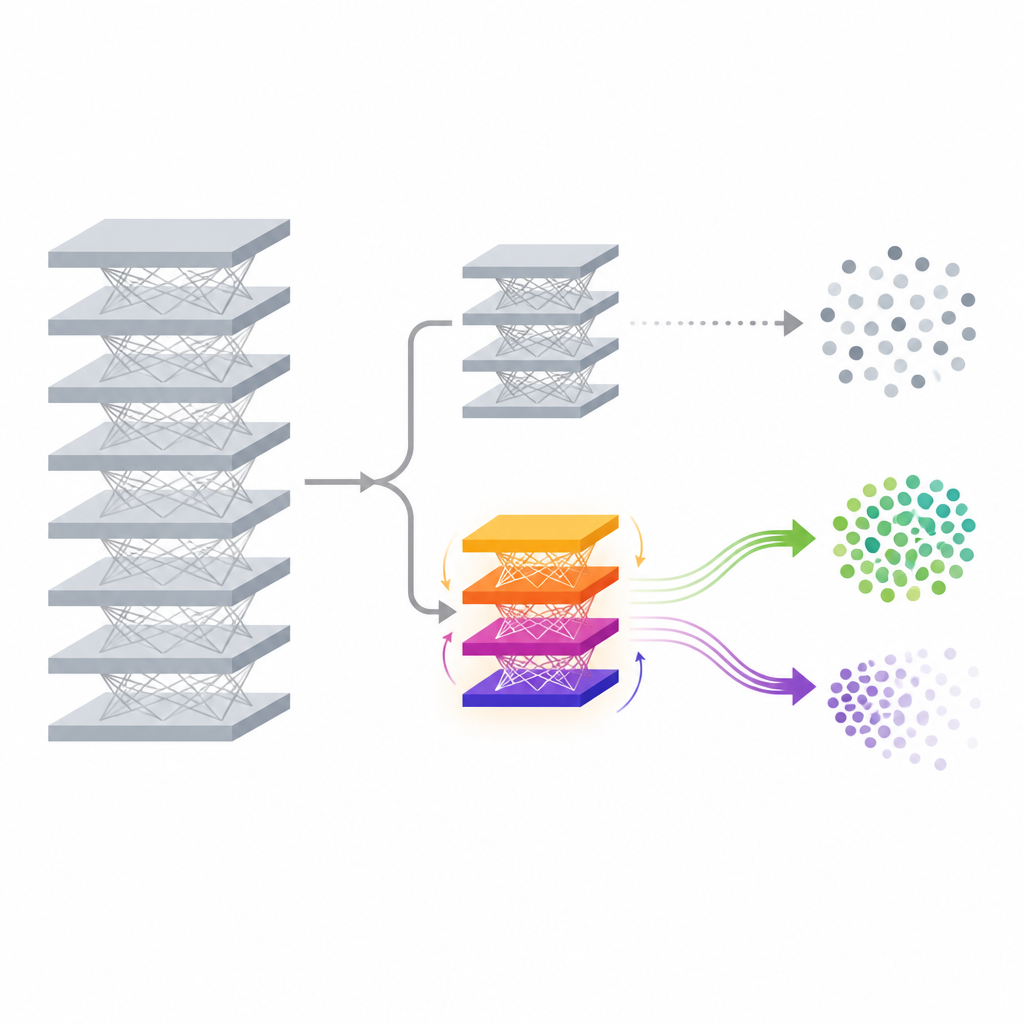
שני זרמים של זיכרון לשימור ולשכחה
הרעיון הטכני המרכזי ב-FedDAM הוא להפריד בין הכוחות שרוצים לשכוח לאלה שרוצים לשמר ידע. כל לקוח משתתף מחלק את נתונים המקומיים שלו לסטים של «לשמר» ו«לשכוח», ואז מחליף עדכונים המבוססים על כל אחד מהם. במקום להזין את שניהם למצב מומנטום יחיד, השיטה שומרת שני מאגרים נפרדים של מומנטום — אחד לשימור ואחד לשכחה — ומשלבת אותם באופן אסימטרי בעת עדכון ראש העזר. לעדכוני השכחה ניתנת זיכרון קצר יותר ומשקל מעט גבוה יותר, כך שהמודל מגיב מהר לראותת נתונים שיש למחוק, ובו בזמן מקשיב למשיכה השקטה של הנתונים הנשמרים. דרך ניסויים המחברים מראים שזרם כפול זה מצמצם קונפליקט ישיר בין שתי המטרות ומיישר את העדכונים ביתר התאמה להתנהגות השכחה הרצויה.
עד כמה שכחה סלקטיבית עובדת בפועל
הצוות בוחן את FedDAM על רפרטוארי תמונות סטנדרטיים, כולל CIFAR-10, CIFAR-100 ותצורת ImageNet-100 בגודל בינוני, בתנאי פדרציה ריאליסטיים שבהם לכל לקוח יש רק חלק מן הנתונים וחלק מהלקוחות עשויים שלא לכלול דוגמאות שיש לשכוח. הם משווים את שיטתם למספר חלופות שמשתמשות במומנטום משותף יחיד, שהופכות גרדיאנטים מתנגשים או מנקות כיוונים חופפים, וכן לאימון מלא מחדש עם דחיסה. בכל המחקרים הללו FedDAM משיג בקביעות דיוק טוב יותר על הכיתות הנשמרות ברמות שכחה דומות, עם שיפורים בסדר גודל של כ-7 עד 9 נקודות אחוז במערכות קשות ומגוונות יותר. באותו זמן, הוא צורך הרבה פחות תקשורת וזמן ריצה מאימון מלא מחדש, גם כאשר זה האחרון מקומפר באופן תוקפני.
מה זה אומר למכשירים יומיומיים
בעבור הקהל הכללי, המסר העיקרי הוא שניתן לתכנן מערכות למידה שיכולות מאוחר יותר ‘‘לשכוח’’ קטגוריות נתונים מסוימות באופן גמיש יותר, בלי להתחיל מאפס ובלי לפגוע יתר על המידה בביצועים על שאר המשימות. FedDAM מציע מתכון מעשי לכך בסביבות פדרטיביות ובקצה על ידי הקפאת רוב המודל, התאמת ראש עזר קטן בלבד והפרדה זהירה של ההשפעות של הנתונים שאנו רוצים לשמור מול אלה שאנו רוצים לשכוח. למרות שאינו מספק הבטחות פורמליות לפרטיות ואינו יכול להתמודד עם כל בקשת הסרה אפשרית, הגישה נותנת אפשרות ביניים שימושית בין לא לעשות כלום לבין לשלם את המחיר המלא של אימון מחדש, ועוזרת לקרב את רעיון שכחת המכונה לפריסה בעולם האמיתי.
ציטוט: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
מילות מפתח: למידה פדרטיבית, שכחת מכונה, חישוב בקצה, פרטיות בבינה מלאכותית, רשתות עצביות