Clear Sky Science · de
Duales asymmetrisches Momentum verbessert föderiertes Klasse-Unlearning in Edge-Systemen
Warum es wichtig ist, Maschinen das Vergessen beizubringen
Unsere Telefone, Uhren und Heimgeräte lernen ständig aus den Daten, die wir ihnen geben, von Fotos und Sprachaufnahmen bis hin zu Gesundheitsmessungen. Aber was passiert, wenn Gesetze oder Nutzer verlangen, dass bestimmte Daten nicht nur aus der Speicherung gelöscht werden, sondern auch aus dem Verhalten der zugrunde liegenden KI-Modelle? Diese Modelle von Grund auf neu zu trainieren, kann langsam, teuer und bei Millionen winziger Geräte oft unrealistisch sein. Dieses Paper untersucht einen leichteren Weg, große verteilte Lernsysteme dazu zu bringen, ausgewählte Informationen zu "vergessen", während sie in anderen Bereichen weiterhin gut funktionieren.
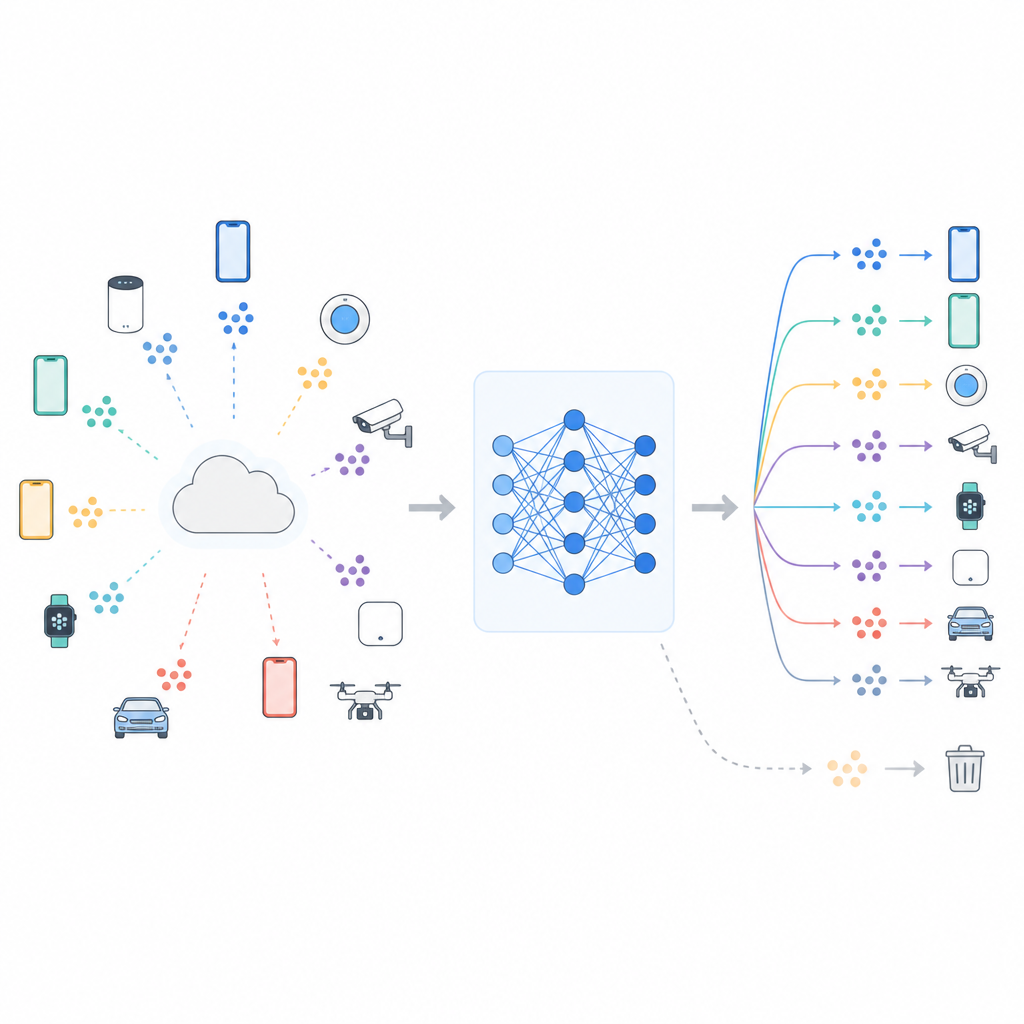
Gemeinsam lernen, ohne Ihre Daten zu teilen
Viele moderne Systeme nutzen föderiertes Lernen, bei dem ein zentraler Server das Training koordiniert, während die Rohdaten auf den einzelnen Geräten verbleiben. Telefone oder Sensoren aktualisieren ein gemeinsames Modell mit ihren lokalen Daten und senden nur die Modelländerungen zurück. Dieses Setup schützt die Privatsphäre und spart Bandbreite, doch es beseitigt nicht alle Risiken. Das Modell kann weiterhin Spuren davon tragen, wen oder was es gesehen hat, und Untersuchungen haben gezeigt, dass clevere Angriffe manchmal erkennen können, ob bestimmte Daten beim Training verwendet wurden. Wachsende Datenschutzregelungen wie das Recht auf Vergessenwerden in Europa erhöhen daher den Druck auf "Machine Unlearning"-Verfahren, die die Abhängigkeit eines Modells von bestimmten Daten—etwa einer Bilderklasse oder einer Nutzergruppe—reduzieren.
Warum Unlearning in der Praxis so schwierig ist
Theoretisch ist die sauberste Lösung, die unerwünschten Daten zu verwerfen und das Modell von Grund auf mit nur den verbleibenden Informationen neu zu trainieren. Praktisch bedeutet vollständiges Retraining jedoch enorme Kommunikationskosten, wiederholte Koordination vieler Clients und lange Laufzeiten, besonders wenn die Daten ungleichmäßig auf Geräte verteilt sind. Außerdem kann der Versuch, ein einzelnes Wissen zu löschen, die Leistung in anderen Bereichen beeinträchtigen, weil dieselben Modellparameter beides unterstützen. Die Autoren zeigen, dass die interne Trainingsmechanik—insbesondere der Momentum-Zustand des Optimierers, der Updates über die Zeit glättet—"Vergessen"- und "Behalten"-Signale vermischen kann, sodass Bemühungen, eine Klasse zu löschen, die übrigen Fähigkeiten des Modells stören.
Ein leichter Zusatzkopf zum Vergessen
Die vorgeschlagene Methode, FedDAM genannt, begegnet diesen Herausforderungen, indem nur ein kleiner Teil des Modells nach dem Training verändert wird. Das Hauptnetzwerk, das Merkmale aus den Daten extrahiert, und sein ursprünglicher Klassifikator bleiben eingefroren. Darauf setzen die Autoren einen neuen, kleinen "auxiliary head", dessen Aufgabe es ist, die finalen Vorhersagen kontrolliert zu justieren. Während des Unlearning wird nur dieser Auxiliary Head aktualisiert und zwischen den Geräten geteilt, was Kommunikation und Rechenaufwand im Vergleich zum vollständigen Retraining stark reduziert. Indem die Methode direkt auf der Ebene der finalen Scores arbeitet, kann sie Entscheidungsgrenzen für eine Zielklasse verschieben, während der tiefe Feature-Extractor unangetastet bleibt—eine attraktive Lösung für ressourcenbeschränkte Telefone und Edge-Geräte.
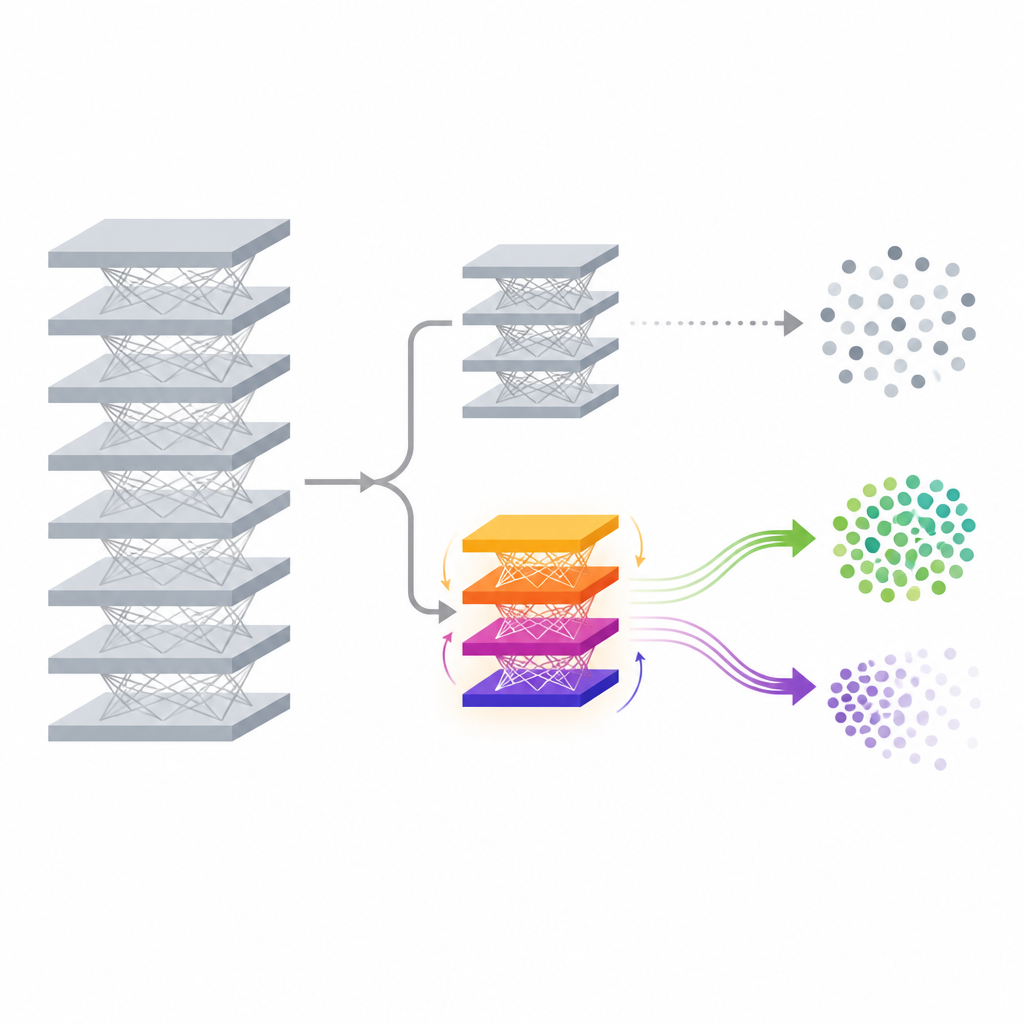
Zwei Gedächtnisströme für Behalten und Vergessen
Die zentrale technische Idee von FedDAM ist, die Kräfte zu trennen, die vergessen wollen, von denen, die Wissen bewahren wollen. Jeder teilnehmende Client teilt seine lokalen Daten in "behalten"- und "vergessen"-Sätze und wechselt dann alternierend zwischen Updates auf Basis beider Sätze. Anstatt beide in einen einzigen Momentum-Zustand einzuspeisen, behält die Methode zwei getrennte Momentum-Puffer bei, einen für das Behalten und einen für das Vergessen, und kombiniert sie asymmetrisch beim Aktualisieren des Auxiliary Head. Vergessens-Updates erhalten ein kürzeres Gedächtnis und ein etwas höheres Gewicht, sodass das Modell schnell reagiert, wenn es Daten sieht, die gelöscht werden sollen, während es gleichzeitig dem leiseren Zug der behaltenen Daten folgt. Durch Experimente zeigen die Autoren, dass dieser doppelte Strom direkte Konflikte zwischen den beiden Zielen reduziert und die Updates näher am beabsichtigten Vergessensverhalten ausrichtet.
Wie gut funktioniert selektives Vergessen in der Praxis
Das Team testet FedDAM an Standard-Bilderdatensätzen, darunter CIFAR-10, CIFAR-100 und eine mittelgroße ImageNet-100-Konfiguration, unter realistischen föderierten Bedingungen, bei denen jeder Client nur einen Ausschnitt der Daten besitzt und einige Clients möglicherweise keine der zu vergessenden Beispiele haben. Sie vergleichen ihre Methode mit mehreren Alternativen, die entweder ein einzelnes gemeinsames Momentum verwenden, widersprüchliche Gradienten projizieren oder überlappende Richtungen bereinigen, sowie mit komprimiertem vollständigem Retraining. In diesen Studien erzielt FedDAM durchweg bessere Genauigkeit bei den behaltenen Klassen bei ähnlichem Vergessensgrad, mit Zuwächsen von etwa 7 bis 9 Prozentpunkten bei schwierigeren, diverseren Datensätzen. Gleichzeitig benötigt es deutlich weniger Kommunikation und Laufzeit als vollständiges Retraining, selbst wenn letzteres aggressiv komprimiert wird.
Was das für Alltagsgeräte bedeutet
Für Nichtfachleute ist die Kernbotschaft, dass es möglich ist, Lernsysteme zu entwerfen, die später bestimmte Datenkategorien flexibler "verlernen" können, ohne von vorn anzufangen und ohne die Gesamtleistung übermäßig zu schädigen. FedDAM bietet ein praktisch anwendbares Rezept für föderierte und Edge-Umgebungen, indem es den Großteil des Modells einfriert, nur einen kleinen Auxiliary Head anpasst und die Einflüsse von zu behaltenden und zu vergessenden Daten sorgfältig trennt. Zwar liefert die Methode keine formalen Datenschutzgarantien und kann nicht jede denkbare Art von Löschanfrage abdecken, dennoch bietet der Ansatz einen nützlichen Mittelweg zwischen Untätigkeit und den vollen Kosten eines Retrainings und rückt das Konzept des Machine Unlearning näher an den realen Einsatz.
Zitation: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Schlüsselwörter: federiertes Lernen, Machine Unlearning, Edge-Computing, Privatsphäre in der KI, Neuronale Netze