Clear Sky Science · ar
التسارع غير المتماثل المزدوج يُحسّن النسيان الفدرالي للطبقات في أنظمة الحافة
لماذا يهم تعليم الآلات كيف تنسى
هواتفنا وساعاتنا وأجهزة المنزل تتعلم باستمرار من البيانات التي نزودها بها، من الصور ومقاطع الصوت إلى قراءات الصحة. لكن ماذا يحدث عندما تطلب القوانين أو المستخدمون أن تُمحى بيانات معينة، ليس فقط من التخزين بل من سلوك نماذج الذكاء الاصطناعي نفسها؟ إعادة تدريب تلك النماذج من الصفر يمكن أن تكون بطيئة ومكلفة وأحيانًا غير واقعية على ملايين الأجهزة الصغيرة. تستعرض هذه الورقة طريقة أخف لجعل أنظمة التعلم الموزعة الكبيرة "تنسى" معلومات مختارة مع الاستمرار في العمل جيدًا على باقي المهام.
التعلّم معًا دون تبادل بياناتك
تستخدم العديد من الأنظمة الحديثة التعلم الفدرالي، حيث ينسق خادم مركزي التدريب بينما تبقى البيانات الخام على كل جهاز. تحدّث الهواتف أو المستشعرات نموذجًا مشتركًا باستخدام بياناتها المحلية، ثم ترسل فقط تغييرات النموذج عائدًا. يساعد هذا الترتيب في حماية الخصوصية وتوفير النطاق الترددي، لكنه لا يزيل كل المخاطر. لا يزال بإمكان النموذج أن يحمل آثارًا عما رآه، وقد أظهرت الأبحاث أن الهجمات الذكية قد تكشف أحيانًا ما إذا كانت بيانات معينة قد استخدمت أثناء التدريب. وقد خلقت قواعد الخصوصية المتزايدة مثل حق النسيان في أوروبا ضغطًا لإجراءات "نسيان الآلة" التي تقلل اعتماد النموذج على بيانات محددة، مثل فئة صور أو مجموعة مستخدمين معينة.
لماذا النسيان في العالم الحقيقي صعب جدًا
نظريًا، أنظف حل هو التخلص من البيانات غير المرغوب فيها وإعادة تدريب النموذج من البداية باستخدام المعلومات المتبقية فقط. عمليًا، يعني إعادة التدريب الكامل تكاليف اتصالات هائلة، وتنسيقًا متكررًا بين العديد من العملاء، وأزمنة تشغيل طويلة، خاصة عندما تكون البيانات موزعة بشكل غير متساو على الأجهزة. علاوة على ذلك، قد يؤذي محاولة نسيان معلومة واحدة الأداء على كل شيء آخر، لأن نفس معلمات النموذج تدعم كلا الأمرين. يوضّح المؤلفون أن آلية التدريب الداخلية، وبشكل خاص حالة الزخم الخاصة بالمُحسِّن التي تُسهل التحديثات عبر الزمن، يمكن أن تمزج إشارات "النسيان" و"الحفظ" معًا بحيث تتداخل محاولات المسح مع مهارات النموذج الأخرى.
رأس إضافي أخف للنسيان
تتعامل الطريقة المقترحة، المسماة FedDAM، مع هذه التحديات بتغيير جزء صغير فقط من النموذج بعد أن يُدرّب بالفعل. يتم تجميد الشبكة الأساسية التي تستخرج الميزات والمصنف الأصلي في مكانهما. وفوقهما، يضيف المؤلفون "رأسًا مساعدًا" صغيرًا جديدًا يكون دوره تعديل التنبؤات النهائية بطريقة مُتحكَّم بها. خلال عملية النسيان، يُحدَّث هذا الرأس المساعد فقط ويُشارك عبر الأجهزة، مما يقلل بشكل كبير من الاتصالات والحساب مقارنة بإعادة تدريب النموذج الكامل. بالعمل مباشرة على مستوى الدرجات النهائية، يمكن للطريقة تحريك حدود القرار لفئة مستهدفة مع ترك مستخرج الميزات العميق دون تغيير، مما يجعلها جذابة للهواتف والأجهزة الحافة محدودة الموارد.
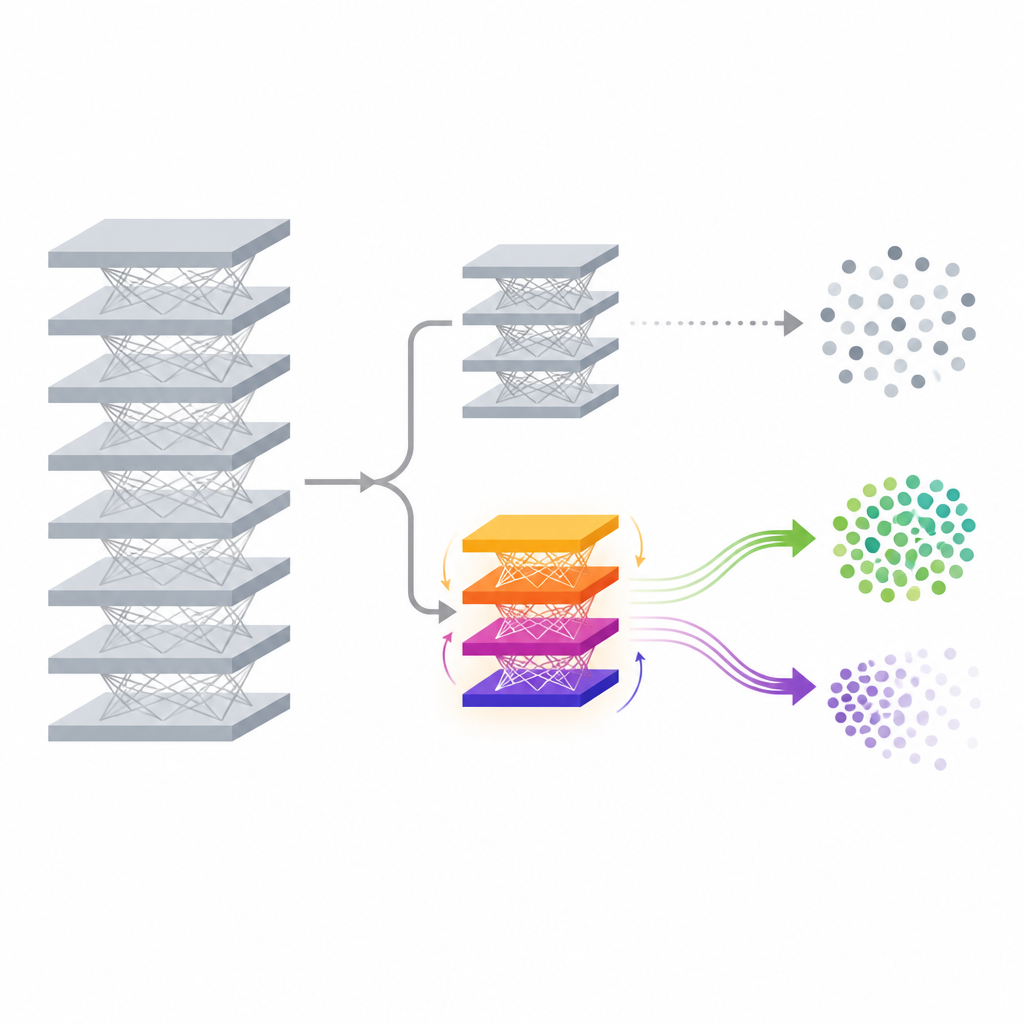
تياران من الذاكرة للحفظ والنسيان
الفكرة التقنية الأساسية في FedDAM هي فصل القوى التي تريد النسيان عن تلك التي تريد الحفاظ على المعرفة. يقسم كل عميل مشارك بياناته المحلية إلى مجموعات "حفظ" و"نسيان"، ثم يبادل التحديثات استنادًا إلى كل منهما. بدلًا من تغذية الاثنين إلى حالة زخم واحدة، يحتفظ الأسلوب ببفرين زخم مميزين، واحد للحفظ وآخر للنسيان، ويجمع بينهما بشكل غير متماثل عند تحديث الرأس المساعد. تُمنح تحديثات النسيان ذاكرة أقصر ووزنًا أعلى قليلًا، لذا يتفاعل النموذج بسرعة عندما يرى بيانات يجب محوها، بينما يستمر في الاستماع إلى جذب البيانات المحتفظ بها الأهدأ. تُظهر التجارب أن هذا التيار المزدوج يقلل الصراع المباشر بين الهدفين ويُوَفّق التحديثات أقرب إلى سلوك النسيان المقصود.
ما مدى فعالية النسيان الانتقائي عمليًا
اختبر الفريق FedDAM على مجموعات صور قياسية، بما في ذلك CIFAR-10 وCIFAR-100 وإعداد ImageNet-100 متوسط الحجم، تحت ظروف فدرالية واقعية حيث يمتلك كل عميل جزءًا فقط من البيانات وبعض العملاء قد لا يمتلكون أي أمثلة يجب نسيانها. قارنوا طريقتهم بعدة بدائل تستخدم إما زخمًا مشتركًا واحدًا، أو تُسقِط التدرجات المتعارضة، أو تمسح الاتجاهات المتداخلة، وكذلك إعادة تدريب النموذج الكامل مع ضغط متقدم. عبر هذه الدراسات، يحقق FedDAM باستمرار دقة أفضل على الفئات المحتفظ بها بمستويات تساويها من النسيان، مع مكاسب تقارب 7 إلى 9 نقاط مئوية على مجموعات أصعب وأكثر تنوعًا. في الوقت نفسه، يستخدم اتصالات وزمن تشغيل أقل بكثير من إعادة التدريب الكامل، حتى عندما يكون الأخير مضغوطًا بشدة.
ماذا يعني هذا لأجهزتنا اليومية
بالنسبة لغير المتخصصين، الرسالة الأساسية أن من الممكن تصميم أنظمة تعلم يمكنها لاحقًا "نسيان" فئات معينة من البيانات بمزيد من المرونة، دون البدء من جديد ودون الإضرار المفرط بالأداء على بقية المهام. يقدم FedDAM وصفة عملية لفعل ذلك في بيئات فدرالية وعلى الحافة عن طريق تجميد معظم النموذج، وتعديل رأس مساعد صغير فقط، وفصل تأثيرات البيانات التي نريد الاحتفاظ بها عن تلك التي نريد نسيانها. ومع أنه لا يقدم ضمانات خصوصية رسمية ولا يستطيع التعامل مع كل نوع من طلبات الإزالة، فإن النهج يوفر وسطًا مفيدًا بين عدم العمل ودفع ثمن إعادة التدريب بالكامل، مما يساعد على تقريب فكرة نسيان الآلة من النشر في العالم الحقيقي.
الاستشهاد: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
الكلمات المفتاحية: التعلم الفدرالي, نسيان الآلة, حوسبة الحافة, الخصوصية في الذكاء الاصطناعي, الشبكات العصبية