Clear Sky Science · pl
Podwójny asymetryczny moment poprawia federacyjne oduczanie klas w systemach brzegowych
Dlaczego uczenie maszyn do zapominania ma znaczenie
Nasze telefony, zegarki i urządzenia domowe stale uczą się na podstawie danych, które im dostarczamy — od zdjęć i nagrań głosowych po pomiary zdrowotne. Co jednak się dzieje, gdy prawo lub użytkownicy żądają, by pewne dane zostały usunięte nie tylko z magazynu, lecz także z zachowania samych modeli sztucznej inteligencji? Ponowne trenowanie takich modeli od zera może być powolne, kosztowne i czasem nierealistyczne dla milionów małych urządzeń. Niniejszy artykuł bada lżejszy sposób na skłonienie dużych, rozproszonych systemów uczących się do „zapomnienia” wybranych informacji przy jednoczesnym utrzymaniu dobrej pracy na pozostałych zadaniach.
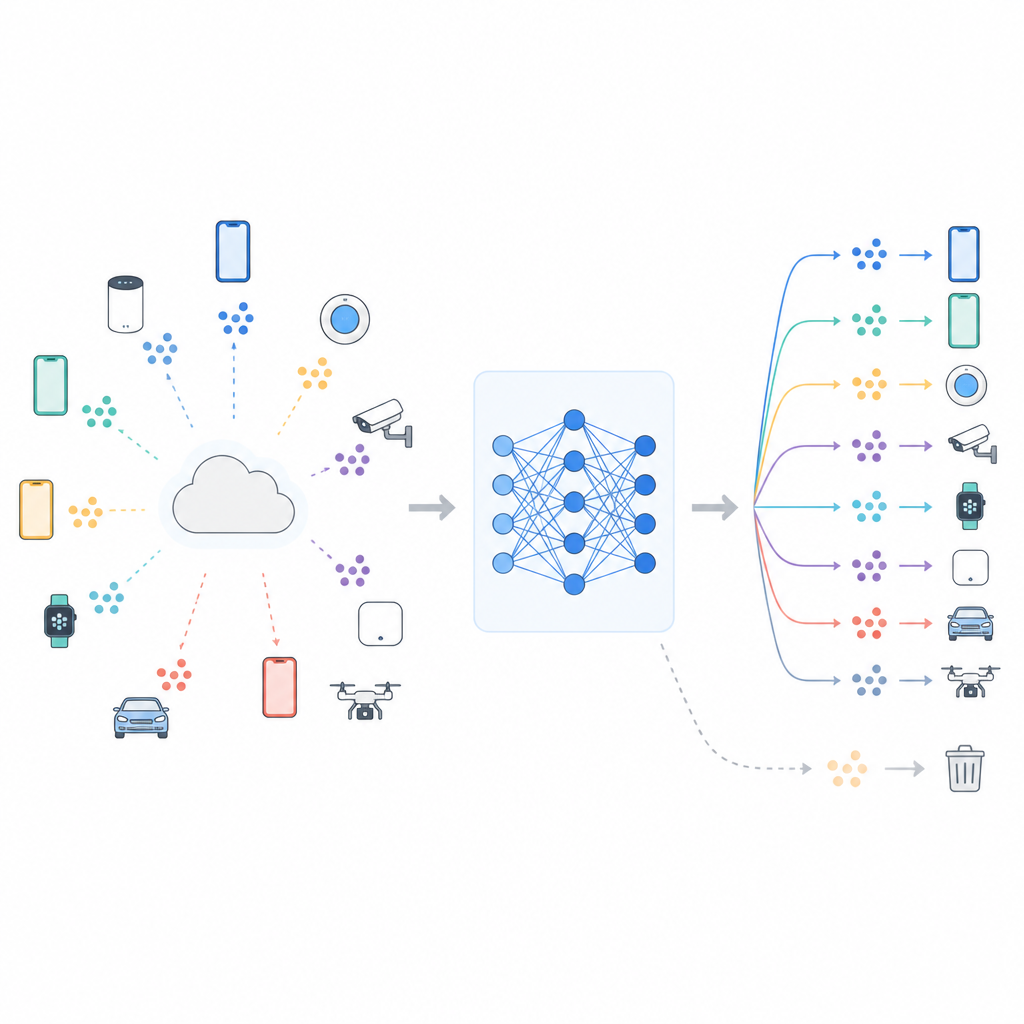
Wspólna nauka bez dzielenia się danymi
Wiele nowoczesnych systemów wykorzystuje uczenie federacyjne, w którym centralny serwer koordynuje trenowanie, a surowe dane pozostają na każdym urządzeniu. Telefony lub czujniki aktualizują współdzielony model za pomocą lokalnych danych, a następnie przesyłają jedynie zmiany modelu z powrotem. Takie rozwiązanie pomaga chronić prywatność i oszczędza przepustowość, ale nie eliminuje wszystkich ryzyk. Model nadal może nosić ślady tego, co widział, a badania wykazały, że sprytne ataki czasem potrafią rozpoznać, czy konkretne dane były użyte podczas treningu. Rosnące regulacje prywatności, takie jak europejskie prawo do bycia zapomnianym, wywierają presję na procedury „oduczania maszyn”, które redukują zależność modelu od wyznaczonych danych, na przykład jednej klasy obrazów lub konkretnej grupy użytkowników.
Dlaczego oduczanie w praktyce jest takie trudne
W teorii najczystszym rozwiązaniem jest wyrzucenie niechcianych danych i ponowne przeszkolenie modelu od początku z wykorzystaniem jedynie pozostałych informacji. W praktyce pełne ponowne trenowanie oznacza ogromne koszty komunikacyjne, wielokrotną koordynację między licznymi klientami i długi czas działania, zwłaszcza gdy dane są nierównomiernie rozproszone między urządzeniami. Dodatkowo próba zapomnienia jednej informacji może zaszkodzić wydajności w innych obszarach, ponieważ te same parametry modelu wspierają obie funkcje. Autorzy pokazują, że wewnętrzne mechanizmy treningowe — w szczególności stan momentu optymalizatora, który wygładza aktualizacje w czasie — mogą mieszać sygnały „zapomnij” i „zachowaj”, tak że próby wymazania jednej klasy zakłócają pozostałe umiejętności modelu.
Lżejszy dodatkowy head do zapominania
Proponowana metoda, nazwana FedDAM, rozwiązuje te wyzwania przez zmianę tylko niewielkiej części modelu po jego uprzednim przetrenowaniu. Główna sieć wyciągająca cechy z danych oraz jej oryginalny klasyfikator zostają zamrożone. Na ich szczycie autorzy dodają nowy, mały „głowicę pomocniczą” (auxiliary head), której zadaniem jest kontrolowane dostosowywanie końcowych predykcji. W trakcie oduczania aktualizowany i wymieniany między urządzeniami jest wyłącznie ten pomocniczy head, co znacząco redukuje komunikację i obliczenia w porównaniu z ponownym trenowaniem pełnego modelu. Działając bezpośrednio na poziomie końcowych wyników, metoda może przesuwać granice decyzji dla docelowej klasy, pozostawiając niezmieniony głęboki ekstraktor cech — co czyni ją atrakcyjną dla zasobooszczędnych telefonów i urządzeń brzegowych.
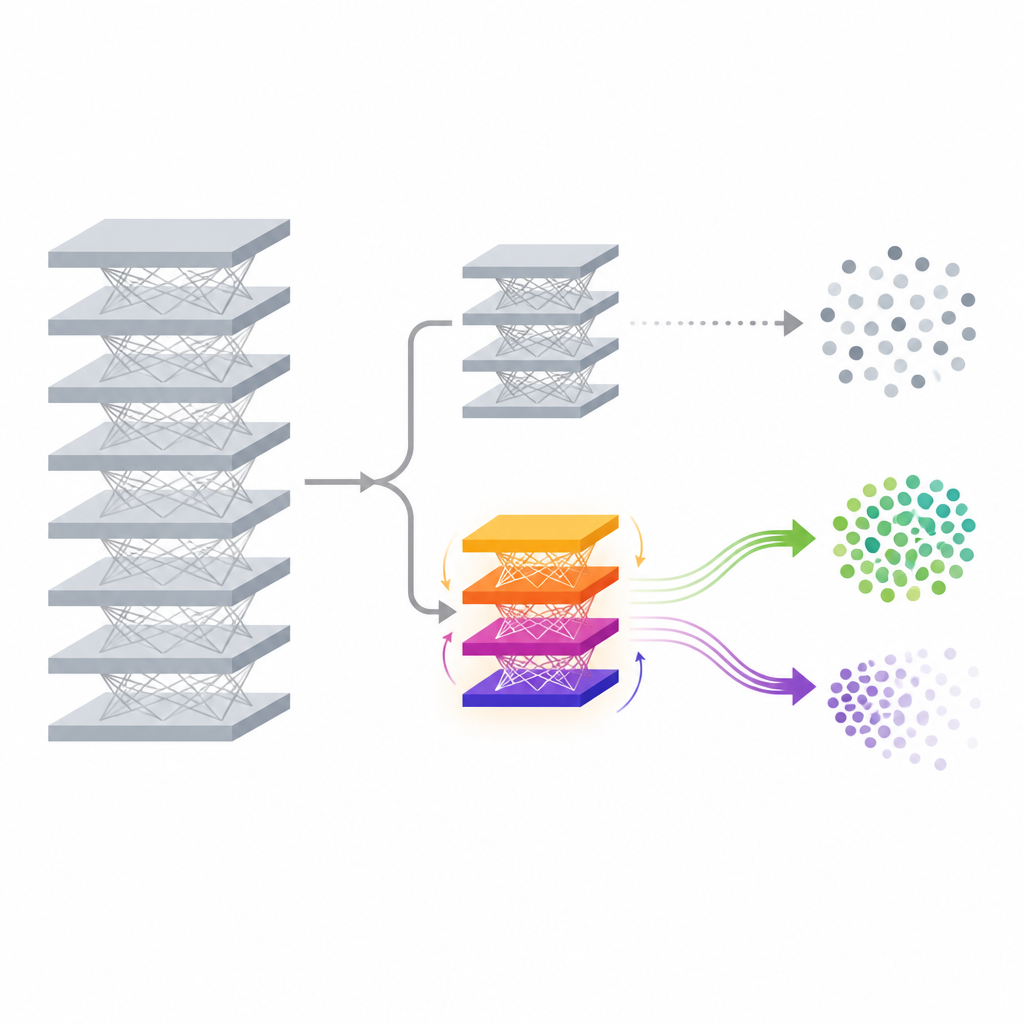
Dwa strumienie pamięci do zachowania i zapomnienia
Kluczowy pomysł techniczny w FedDAM polega na oddzieleniu sił, które chcą zapomnieć, od tych, które pragną zachować wiedzę. Każdy uczestniczący klient dzieli swoje lokalne dane na zbiory „zachowaj” i „zapomnij”, a następnie na przemian wykonuje aktualizacje w oparciu o każdy z nich. Zamiast umieszczać oba w jednym stanie momentu, metoda utrzymuje dwa odrębne buforowe momenty — jeden dla zachowania i jeden dla zapominania — i łączy je asymetrycznie podczas aktualizacji pomocniczego heada. Aktualizacje związane z zapominaniem otrzymują krótszą pamięć i nieco większą wagę, dzięki czemu model reaguje szybko na dane, które powinny zostać usunięte, a jednocześnie pozostaje pod wpływem łagodniejszego oddziaływania danych zachowanych. W eksperymentach autorzy pokazują, że ten podwójny strumień zmniejsza bezpośredni konflikt między tymi dwoma celami i lepiej wyrównuje aktualizacje z zamierzonym zachowaniem oduczania.
Jak dobrze działa selektywne zapominanie w praktyce
Zespół testuje FedDAM na standardowych zbiorach obrazów, w tym CIFAR-10, CIFAR-100 oraz w średniej wielkości konfiguracji ImageNet-100, w realistycznych warunkach federacyjnych, gdzie każdy klient ma tylko wycinek danych, a niektóre klienty mogą w ogóle nie posiadać przykładów przeznaczonych do zapomnienia. Porównują swoją metodę z wieloma alternatywami, które albo używają pojedynczego współdzielonego momentu, rzutują sprzeczne gradienty, albo oczyszczają nachodzące kierunki, jak również z kompresowanym pełnym ponownym trenowaniem. W tych badaniach FedDAM konsekwentnie osiąga lepszą dokładność na klasach zachowanych przy podobnym poziomie zapomnienia, z zyskami rzędu 7–9 punktów procentowych na trudniejszych, bardziej zróżnicowanych zbiorach. Jednocześnie wykorzystuje znacznie mniej komunikacji i czasu działania niż pełne ponowne trenowanie, nawet gdy to ostatnie jest agresywnie kompresowane.
Co to oznacza dla codziennych urządzeń
Dla osób niebędących specjalistami główny przekaz jest taki, że można zaprojektować systemy uczące się, które później mogą elastyczniej „oduczać” określone kategorie danych, bez zaczynania od zera i bez nadmiernego pogarszania wydajności w innych zadaniach. FedDAM oferuje praktyczny przepis na osiągnięcie tego w scenariuszach federacyjnych i brzegowych przez zamrożenie większości modelu, dopasowanie tylko małego pomocniczego heada i staranne oddzielenie wpływów danych, które chcemy zachować, od tych, które chcemy zapomnieć. Chociaż nie dostarcza formalnych gwarancji prywatności i nie poradzi sobie ze wszystkimi możliwymi żądaniami usunięcia, podejście to stanowi przydatny kompromis między brakiem działań a poniesieniem pełnych kosztów ponownego trenowania, przybliżając koncepcję oduczania maszyn do rzeczywistego wdrożenia.
Cytowanie: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Słowa kluczowe: uczenie federacyjne, oduczanie maszynowe, computing brzegowy, prywatność w AI, sieci neuronowe