Clear Sky Science · nl
Dual asymmetrische momentum verbetert gefedereerd klassenvergeten in edge-systemen
Waarom het belangrijk is machines te leren vergeten
Onze telefoons, horloges en huishoudelijke apparaten leren continu van de gegevens die we ze geven, van foto’s en spraakfragmenten tot gezondheidsmetingen. Maar wat gebeurt er wanneer wetgeving of gebruikers eisen dat bepaalde data worden gewist, niet alleen uit opslag maar ook uit het gedrag van de betrokken AI-modellen? Die modellen helemaal opnieuw trainen kan traag, duur en soms onrealistisch zijn op miljoenen kleine apparaten. Dit artikel onderzoekt een lichtere manier om grote, gedistribueerde leersystemen geselecteerde informatie te laten ‘vergeten’ terwijl ze nog steeds goed functioneren op alles wat overblijft.
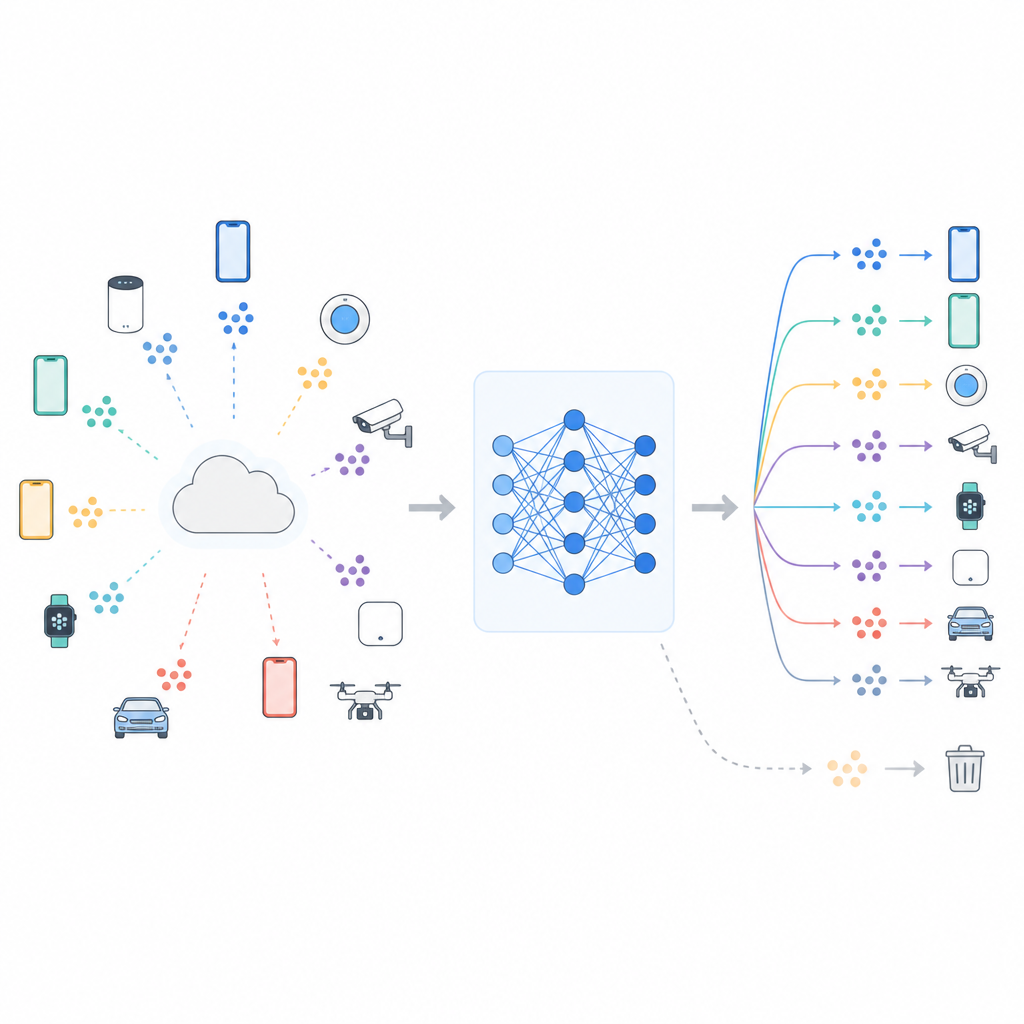
Samen leren zonder je data te delen
Veel moderne systemen gebruiken gefedereerd leren, waarbij een centrale server de training coördineert terwijl de ruwe data op elk apparaat blijven. Telefoons of sensoren werken een gedeeld model bij met hun lokale data en sturen alleen modelupdates terug. Deze opzet helpt de privacy te beschermen en bespaart bandbreedte, maar elimineert niet alle risico’s. Het model kan nog steeds sporen dragen van wie of wat het heeft gezien, en onderzoek heeft aangetoond dat slimme aanvallen soms kunnen bepalen of specifieke data gebruikt zijn tijdens training. Toenemende privacyregels, zoals het recht om vergeten te worden in Europa, creëren daarom druk voor “machine unlearning”-procedures die de afhankelijkheid van een model van aangewezen data verminderen, bijvoorbeeld één klasse beelden of een bepaalde gebruikersgroep.
Waarom unlearning in de praktijk zo moeilijk is
In theorie is de schoonste oplossing de ongewenste data weg te gooien en het model helemaal opnieuw te trainen met alleen de overgebleven informatie. In de praktijk betekent volledig opnieuw trainen enorme communicatiekosten, herhaalde coördinatie tussen veel clients en lange runtimes, vooral wanneer data ongelijk verdeeld zijn over apparaten. Bovendien kan het proberen te vergeten van één stukje kennis de prestaties op alles anders schaden, omdat dezelfde modelparameters beide taken ondersteunen. De auteurs tonen aan dat de interne trainingsmechanismen, in het bijzonder de momentumstaat van de optimizer die updates in de tijd afvlakt, ‘vergeten’- en ‘behouden’-signalen kunnen vermengen, waardoor pogingen om één klasse te wissen de overige vaardigheden van het model hinderen.
Een lichter extra hoofd om te vergeten
De voorgestelde methode, FedDAM genoemd, pakt deze uitdagingen aan door slechts een klein deel van het model te wijzigen nadat het al is getraind. Het hoofdnetwerk dat kenmerken uit data haalt en de originele classifier worden vastgezet. Bovenop deze onderdelen voegen de auteurs een nieuw, klein “auxiliary head” toe dat de uiteindelijke voorspellingen op een gecontroleerde manier bijstuurt. Tijdens het unlearning wordt alleen dit auxiliary head bijgewerkt en gedeeld tussen apparaten, wat communicatie en rekenwerk aanzienlijk vermindert vergeleken met het volledig opnieuw trainen van het model. Doordat de methode direct op het niveau van de eindscores werkt, kan zij beslissingsgrenzen voor een doelklasse verschuiven terwijl de diepe feature-extractor onaangeroerd blijft, wat aantrekkelijk is voor apparaten met beperkte middelen zoals telefoons en edge-apparaten.
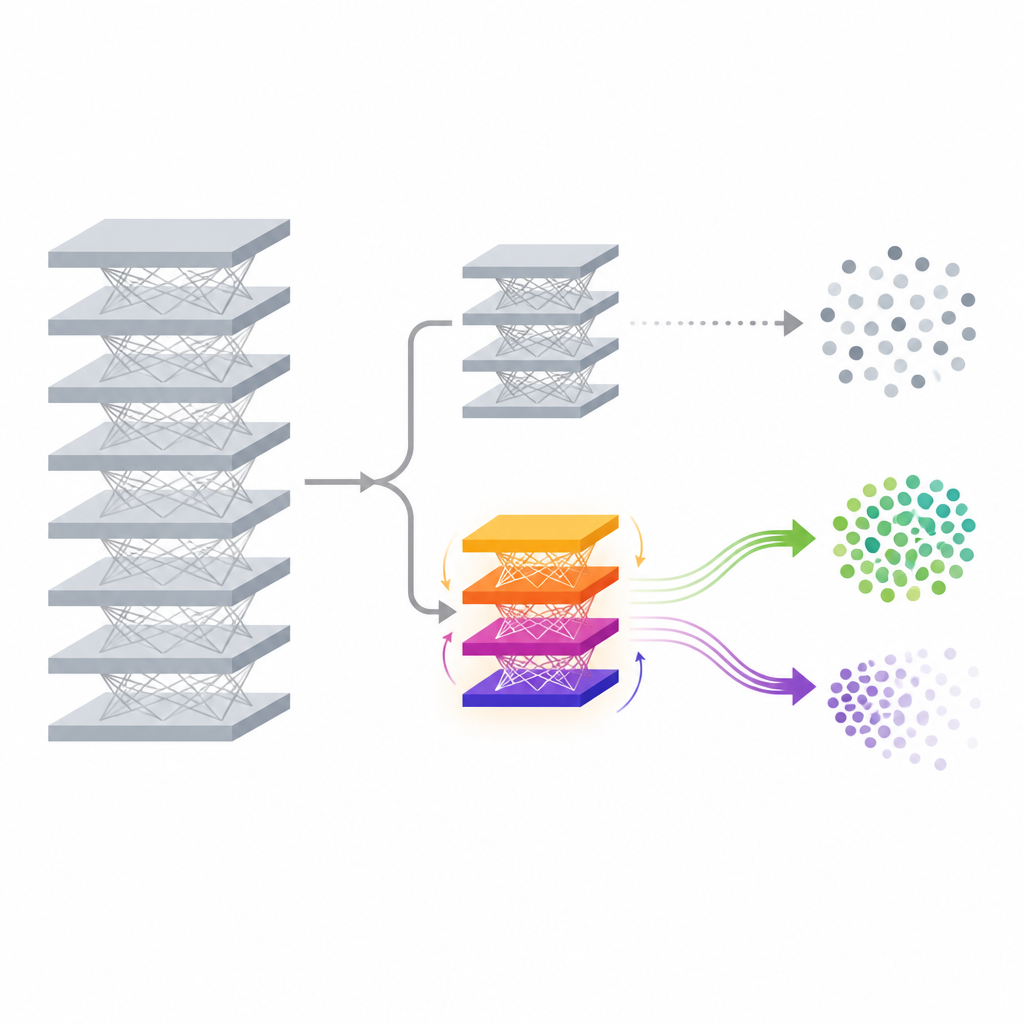
Twee geheugenstromen voor behouden en vergeten
Het kerntechnische idee in FedDAM is de krachten die willen vergeten te scheiden van die willen behouden. Elke deelnemende client verdeelt zijn lokale data in ‘behouden’ en ‘vergeten’ sets en wisselt daaropvolgende updates af die gebaseerd zijn op elk van die sets. In plaats van beide in één momentumstaat te stoppen, houdt de methode twee aparte momentumbuffers bij, één voor behoud en één voor vergeten, en combineert ze asymmetrisch bij het bijwerken van het auxiliary head. Vergeten-updates krijgen een korter geheugen en iets hoger gewicht, zodat het model snel reageert wanneer het data ziet die gewist moeten worden, terwijl het nog steeds luistert naar de zachtere invloed van de behouden data. Met experimenten laten de auteurs zien dat deze dubbele stroom directe conflicten tussen de twee doelen vermindert en updates beter afstemt op het beoogde vergeetgedrag.
Hoe goed werkt selectief vergeten in de praktijk
Het team test FedDAM op standaard beeldverzamelingen, waaronder CIFAR-10, CIFAR-100 en een middelgrote ImageNet-100 opzet, onder realistische gefedereerde omstandigheden waarbij elke client slechts een deel van de data heeft en sommige clients mogelijk geen voorbeelden van de te vergeten klasse bezitten. Ze vergelijken hun methode met verschillende alternatieven die ofwel één gedeeld momentum gebruiken, conflicterende gradiënten projecteren, of overlappende richtingen wissen, evenals met gecomprimeerd volledig opnieuw trainen. Over deze studies heen bereikt FedDAM consequent betere nauwkeurigheid op de behouden klassen bij vergelijkbare niveaus van vergeten, met winst van ongeveer 7 tot 9 procentpunten op moeilijkere, meer diverse datasets. Tegelijkertijd gebruikt het veel minder communicatie en runtime dan volledig opnieuw trainen, zelfs wanneer dat laatste agressief gecomprimeerd is.
Wat dit betekent voor alledaagse apparaten
Voor niet-specialisten is de kernboodschap dat het mogelijk is leersystemen te ontwerpen die later bepaalde categorieën data flexibeler kunnen ‘unlearnen’, zonder opnieuw te beginnen en zonder de prestaties op alles anders onnodig te schaden. FedDAM biedt een praktisch recept om dit in gefedereerde en edge-omgevingen te doen door het grootste deel van het model te bevriezen, slechts een klein auxiliary head aan te passen en voorzichtig de invloeden van data die we willen behouden te scheiden van data die we willen vergeten. Hoewel het geen formele privacygaranties biedt en niet elk type verwijderingsverzoek kan afhandelen, vormt de aanpak een nuttig middenweg tussen niets doen en de volledige prijs van opnieuw trainen betalen, en helpt zij het idee van machine unlearning dichter bij daadwerkelijke inzet in de echte wereld te brengen.
Bronvermelding: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Trefwoorden: gefedereerd leren, machine unlearning, edge computing, privacy in AI, neurale netwerken