Clear Sky Science · es
El momento asimétrico dual mejora el olvido federado de clases en sistemas edge
Por qué enseñar a las máquinas a olvidar importa
Nuestros teléfonos, relojes y dispositivos domésticos aprenden constantemente de los datos que les proporcionamos, desde fotos y clips de voz hasta lecturas de salud. Pero ¿qué ocurre cuando la ley o los usuarios exigen que ciertos datos se borren, no solo del almacenamiento sino del propio comportamiento de los modelos de inteligencia artificial? Volver a entrenar esos modelos desde cero puede ser lento, costoso y a veces poco realista en millones de dispositivos pequeños. Este artículo explora una vía más ligera para hacer que grandes sistemas de aprendizaje distribuidos “olviden” información seleccionada mientras siguen funcionando bien en todo lo demás.
Aprender juntos sin compartir tus datos
Muchos sistemas modernos usan aprendizaje federado, donde un servidor central coordina el entrenamiento mientras los datos brutos permanecen en cada dispositivo. Teléfonos o sensores actualizan un modelo compartido usando sus datos locales y luego envían sólo los cambios del modelo. Esta configuración ayuda a proteger la privacidad y ahorra ancho de banda, pero no elimina todos los riesgos. El modelo aún puede conservar rastros de quién o qué ha visto, y la investigación ha mostrado que ataques ingeniosos pueden a veces determinar si datos específicos se usaron durante el entrenamiento. Normas de privacidad crecientes, como el derecho al olvido en Europa, han creado presión para procedimientos de “olvido de máquinas” que reduzcan la dependencia del modelo respecto a datos designados, como una clase de imágenes o un grupo concreto de usuarios.
Por qué el olvido en el mundo real es tan difícil
En teoría, la solución más limpia es eliminar los datos no deseados y volver a entrenar el modelo desde cero usando solo la información restante. En la práctica, el reentrenamiento completo supone costes de comunicación enormes, coordinación repetida entre muchos clientes y largos tiempos de ejecución, especialmente cuando los datos están repartidos de forma desigual entre los dispositivos. Además, intentar olvidar un conocimiento puede perjudicar el rendimiento en todo lo demás, porque los mismos parámetros del modelo sostienen ambas cosas. Los autores muestran que la maquinaria interna de entrenamiento, en particular el estado de momento del optimizador que suaviza las actualizaciones a lo largo del tiempo, puede mezclar las señales de “olvidar” y “retener” de modo que los esfuerzos por borrar una clase interfieran con las demás capacidades del modelo.
Una ligera cabeza adicional para olvidar
El método propuesto, llamado FedDAM, aborda estos retos cambiando solo una pequeña parte del modelo después de que ya ha sido entrenado. La red principal que extrae características de los datos y su clasificador original permanecen congelados. Sobre ellos, los autores añaden una nueva y pequeña “cabeza auxiliar” cuya función es ajustar las predicciones finales de manera controlada. Durante el proceso de olvido, solo esta cabeza auxiliar se actualiza y se comparte entre los dispositivos, lo que reduce mucho la comunicación y el cómputo en comparación con reentrenar el modelo completo. Al actuar directamente sobre las puntuaciones finales, el método puede desplazar las fronteras de decisión para una clase objetivo dejando intacto el extractor de características profundo, lo que lo hace atractivo para teléfonos y dispositivos edge con recursos limitados.
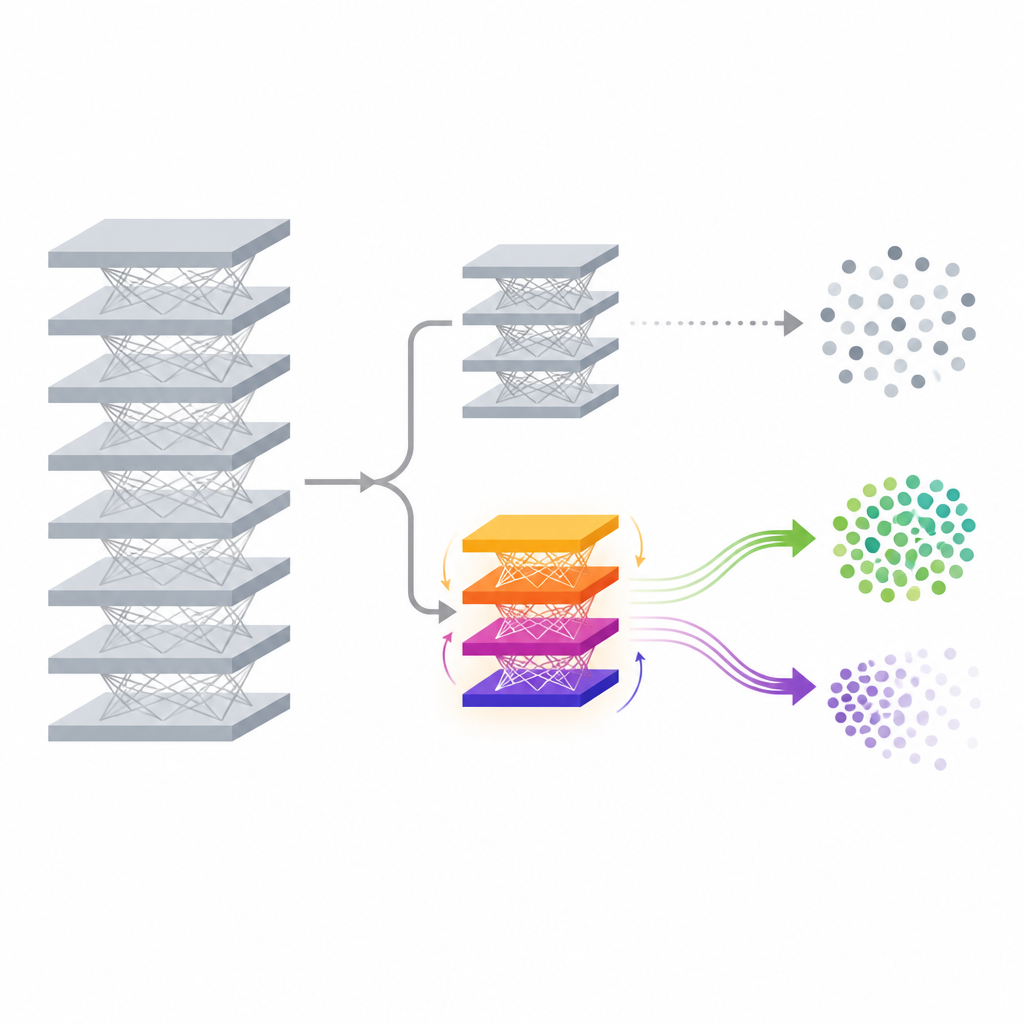
Dos flujos de memoria para guardar y olvidar
La idea técnica clave en FedDAM es separar las fuerzas que quieren olvidar de las que quieren preservar el conocimiento. Cada cliente participante divide sus datos locales en conjuntos de “retención” y “olvido”, y alterna las actualizaciones basadas en cada uno. En lugar de alimentar ambos en un solo estado de momento, el método mantiene dos búferes de momento distintos, uno para retención y otro para olvido, y los combina de forma asimétrica al actualizar la cabeza auxiliar. Las actualizaciones de olvido reciben una memoria más corta y un peso ligeramente mayor, de modo que el modelo reacciona rápidamente ante datos que deben borrarse, mientras sigue atendiendo al tirón más suave de los datos retenidos. Mediante experimentos, los autores muestran que este flujo dual reduce el conflicto directo entre los dos objetivos y alinea las actualizaciones más estrechamente con el comportamiento de olvido deseado.
Qué tan bien funciona el olvido selectivo en la práctica
El equipo prueba FedDAM en colecciones de imágenes estándar, incluyendo CIFAR-10, CIFAR-100 y una versión de tamaño medio de ImageNet-100, bajo condiciones federadas realistas en las que cada cliente tiene solo una porción de los datos y algunos clientes pueden no tener ejemplos de la clase que debe olvidarse. Comparan su método con varias alternativas que usan un solo momento compartido, proyectan gradientes en conflicto o limpian direcciones solapadas, así como con el reentrenamiento completo comprimido. En estos estudios, FedDAM consigue de forma consistente mejor precisión en las clases retenidas a niveles de olvido similares, con ganancias de alrededor de 7 a 9 puntos porcentuales en conjuntos de datos más difíciles y diversos. Al mismo tiempo, usa mucha menos comunicación y tiempo de ejecución que el reentrenamiento completo, incluso cuando este último está comprimido agresivamente.
Qué significa esto para los dispositivos cotidianos
Para los no especialistas, el mensaje principal es que es posible diseñar sistemas de aprendizaje que puedan posteriormente “olvidar” ciertas categorías de datos de forma más flexible, sin empezar de nuevo y sin perjudicar excesivamente el rendimiento en el resto. FedDAM ofrece una receta práctica para hacerlo en entornos federados y edge al congelar la mayor parte del modelo, ajustar solo una pequeña cabeza auxiliar y separar cuidadosamente las influencias de los datos que queremos guardar de los que queremos olvidar. Aunque no proporciona garantías formales de privacidad y no puede manejar todo tipo de solicitudes de eliminación, el enfoque ofrece un término medio útil entre no hacer nada y pagar el coste completo del reentrenamiento, ayudando a acercar la idea del olvido de máquinas al despliegue en el mundo real.
Cita: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Palabras clave: aprendizaje federado, olvido de máquinas, computación en el edge, privacidad en IA, redes neuronales