Clear Sky Science · pt
Momento assimétrico duplo melhora o desaprendizado federado de classes em sistemas de borda
Por que ensinar máquinas a esquecer importa
Nossos telefones, relógios e aparelhos domésticos aprendem constantemente com os dados que fornecemos, desde fotos e gravações de voz até leituras de saúde. Mas o que acontece quando leis ou usuários exigem que certos dados sejam apagados, não apenas do armazenamento, mas do próprio comportamento dos modelos de inteligência artificial envolvidos? Retreinar esses modelos do zero pode ser lento, caro e, às vezes, inviável em milhões de pequenos dispositivos. Este artigo explora uma forma mais leve de fazer grandes sistemas de aprendizado distribuído “esquecerem” informações selecionadas, mantendo bom desempenho no restante.
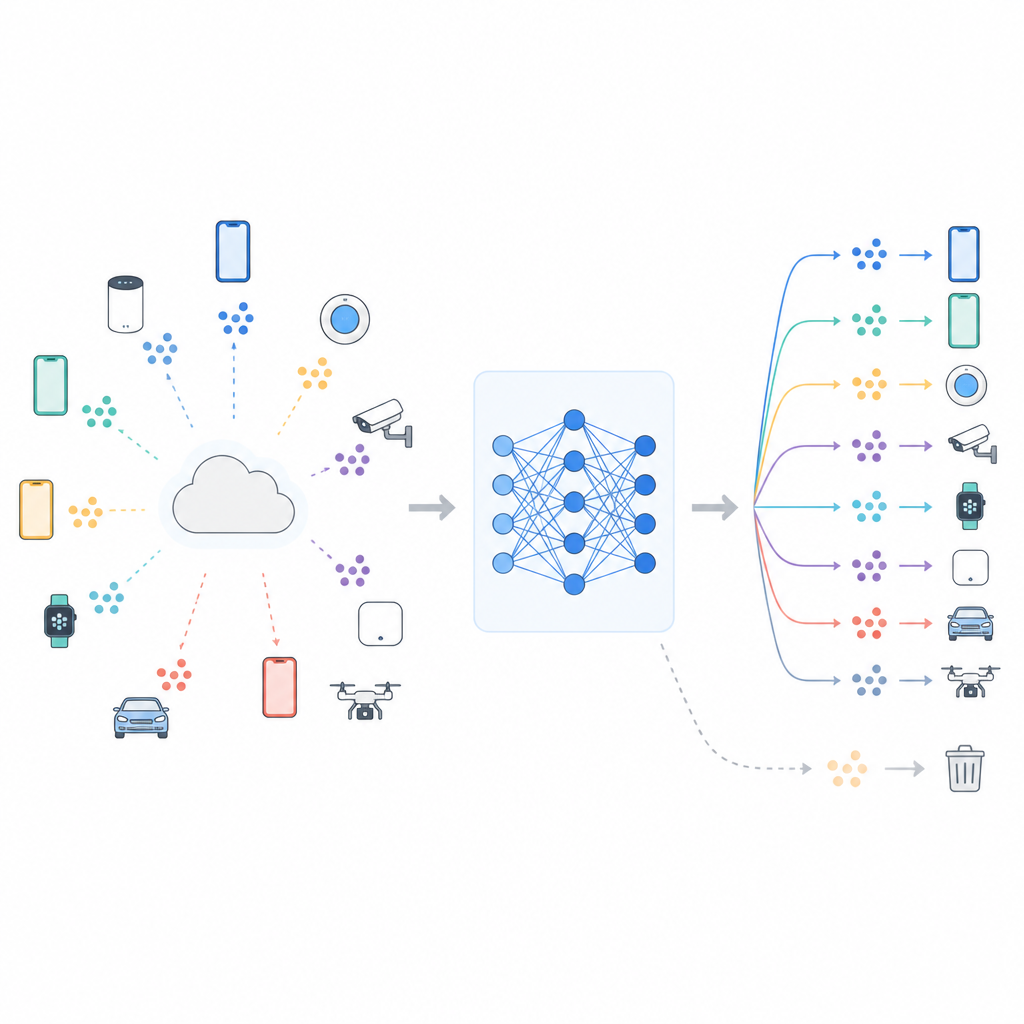
Aprender juntos sem compartilhar seus dados
Muitos sistemas modernos usam aprendizado federado, no qual um servidor central coordena o treinamento enquanto os dados brutos permanecem em cada dispositivo. Telefones ou sensores atualizam um modelo compartilhado usando seus dados locais e enviam apenas as alterações do modelo de volta. Essa configuração ajuda a proteger a privacidade e economizar largura de banda, mas não elimina todos os riscos. O modelo ainda pode guardar vestígios de quem ou o que viu, e pesquisas mostram que ataques sofisticados às vezes conseguem inferir se dados específicos foram usados durante o treinamento. Regras de privacidade em crescimento, como o direito ao esquecimento na Europa, criaram portanto pressão por procedimentos de “desaprendizado de máquina” que reduzam a dependência do modelo em dados designados, como uma classe de imagens ou um grupo específico de usuários.
Por que o desaprendizado no mundo real é tão difícil
Na teoria, a solução mais limpa é descartar os dados indesejados e retreinar o modelo desde o início usando apenas as informações restantes. Na prática, o retreinamento completo significa custos de comunicação enormes, coordenação repetida entre muitos clientes e longos tempos de execução, especialmente quando os dados estão distribuídos de forma desigual entre os dispositivos. Além disso, tentar esquecer um conhecimento pode prejudicar o desempenho no restante, porque os mesmos parâmetros do modelo sustentam ambos. Os autores mostram que a maquinaria interna do treinamento, em particular o estado de momento do otimizador que suaviza atualizações ao longo do tempo, pode misturar sinais de “esquecer” e de “manter”, fazendo com que esforços para apagar uma classe interfiram nas demais habilidades do modelo.
Uma pequena cabeça adicional para o esquecimento
O método proposto, chamado FedDAM, enfrenta esses desafios alterando apenas uma pequena parte do modelo após o treinamento inicial. A rede principal que extrai características dos dados e seu classificador original são congelados. Sobre eles, os autores adicionam uma nova e pequena “cabeça auxiliar” cuja função é ajustar as previsões finais de forma controlada. Durante o desaprendizado, apenas essa cabeça auxiliar é atualizada e compartilhada entre os dispositivos, o que reduz muito a comunicação e o custo computacional em comparação com o retreinamento do modelo inteiro. Ao atuar diretamente no nível das pontuações finais, o método pode deslocar fronteiras de decisão para uma classe-alvo sem tocar no extrator profundo de características, tornando-o atraente para telefones e dispositivos de borda com recursos limitados.
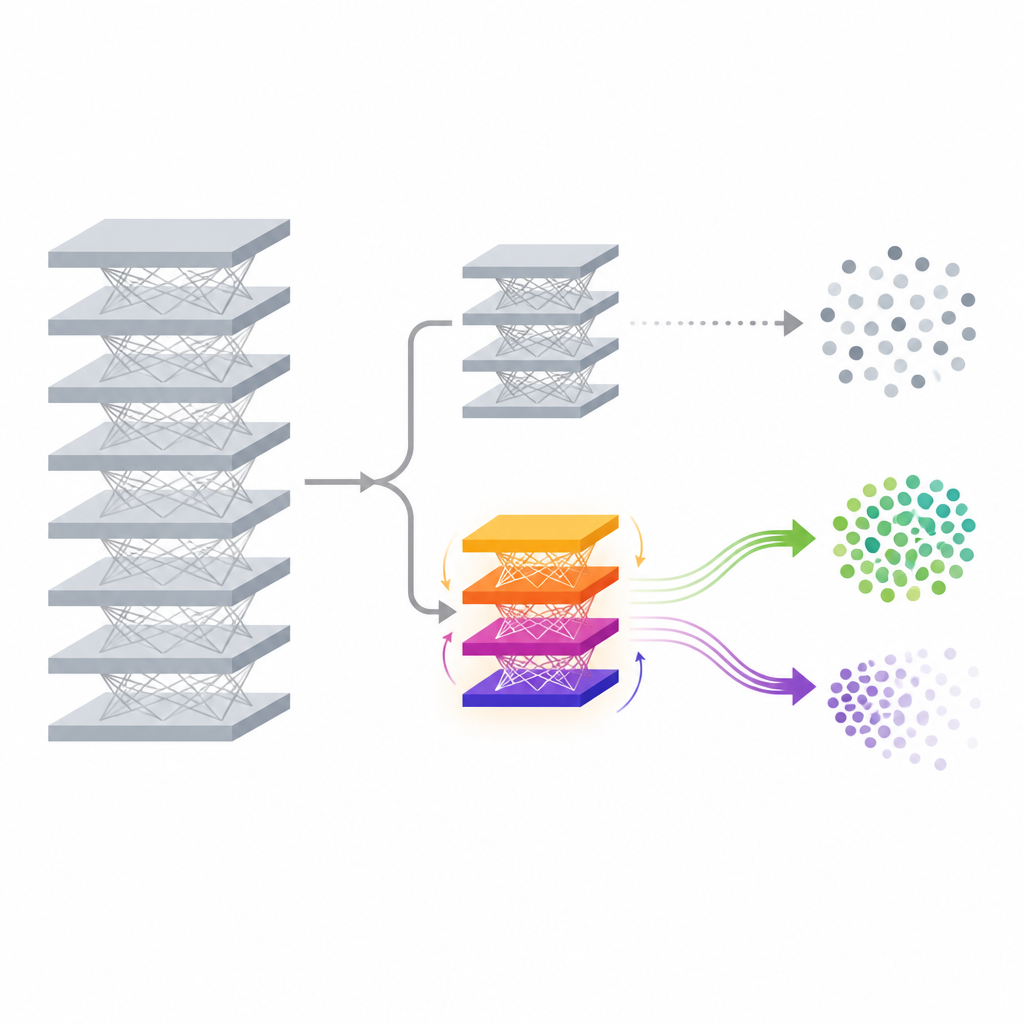
Dois fluxos de memória para manter e esquecer
A ideia técnica chave do FedDAM é separar as forças que querem esquecer daquelas que querem preservar o conhecimento. Cada cliente participante divide seus dados locais em conjuntos de “manter” e “esquecer” e alterna atualizações com base em cada um. Em vez de alimentar ambos em um único estado de momento, o método mantém dois buffers de momento distintos, um para retenção e outro para esquecimento, e os combina de forma assimétrica ao atualizar a cabeça auxiliar. Atualizações de esquecimento recebem memória mais curta e peso ligeiramente maior, para que o modelo reaja rápido ao ver dados que devem ser apagados, enquanto ainda responde à influência mais tênue dos dados retidos. Por meio de experimentos, os autores mostram que esse fluxo duplo reduz o conflito direto entre os dois objetivos e alinha as atualizações mais de perto ao comportamento de esquecimento pretendido.
Quão bem o esquecimento seletivo funciona na prática
A equipe testa o FedDAM em coleções de imagens padrão, incluindo CIFAR-10, CIFAR-100 e uma versão intermediária do ImageNet com 100 classes, em condições federadas realistas onde cada cliente possui apenas uma fatia dos dados e alguns clientes podem não ter nenhum exemplo a ser esquecido. Eles comparam seu método com várias alternativas que usam um único momento compartilhado, projetam gradientes conflitantes ou removem direções sobrepostas, além de retreinamento completo do modelo com compressão. Nesses estudos, o FedDAM consistentemente alcança melhor acurácia nas classes retidas em níveis semelhantes de esquecimento, com ganhos na faixa de 7 a 9 pontos percentuais em conjuntos mais difíceis e diversos. Ao mesmo tempo, usa muito menos comunicação e tempo de execução do que o retreinamento completo, mesmo quando este é fortemente comprimido.
O que isso significa para dispositivos do dia a dia
Para não especialistas, a mensagem principal é que é possível projetar sistemas de aprendizado que, posteriormente, possam “desaprender” certas categorias de dados de forma mais flexível, sem recomeçar e sem prejudicar excessivamente o desempenho no restante. O FedDAM oferece uma receita prática para fazer isso em cenários federados e de borda, congelando a maior parte do modelo, ajustando apenas uma pequena cabeça auxiliar e separando cuidadosamente as influências dos dados que queremos manter das que queremos esquecer. Embora não forneça garantias formais de privacidade nem consiga lidar com todo tipo de solicitação de remoção, a abordagem oferece um meio-termo útil entre não fazer nada e pagar o custo total do retreinamento, ajudando a aproximar a ideia de desaprendizado de máquina da implantação no mundo real.
Citação: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Palavras-chave: aprendizado federado, desaprendizado de máquina, computação de borda, privacidade em IA, redes neurais