Clear Sky Science · fr
Un double moment asymétrique améliore l’« unlearning » fédéré dans les systèmes edge
Pourquoi apprendre aux machines à oublier est important
Nos téléphones, montres et appareils domestiques apprennent en permanence à partir des données que nous leur fournissons, des photos et enregistrements vocaux aux mesures de santé. Mais que se passe-t-il lorsque des lois ou des utilisateurs exigent que certaines données soient effacées, non seulement du stockage mais aussi du comportement même des modèles d’intelligence artificielle concernés ? Réentraîner ces modèles depuis zéro peut être lent, coûteux et parfois irréaliste sur des millions de petits appareils. Cet article explore une façon plus légère d’amener de larges systèmes d’apprentissage distribués à « oublier » des informations sélectionnées tout en continuant à bien fonctionner pour le reste.
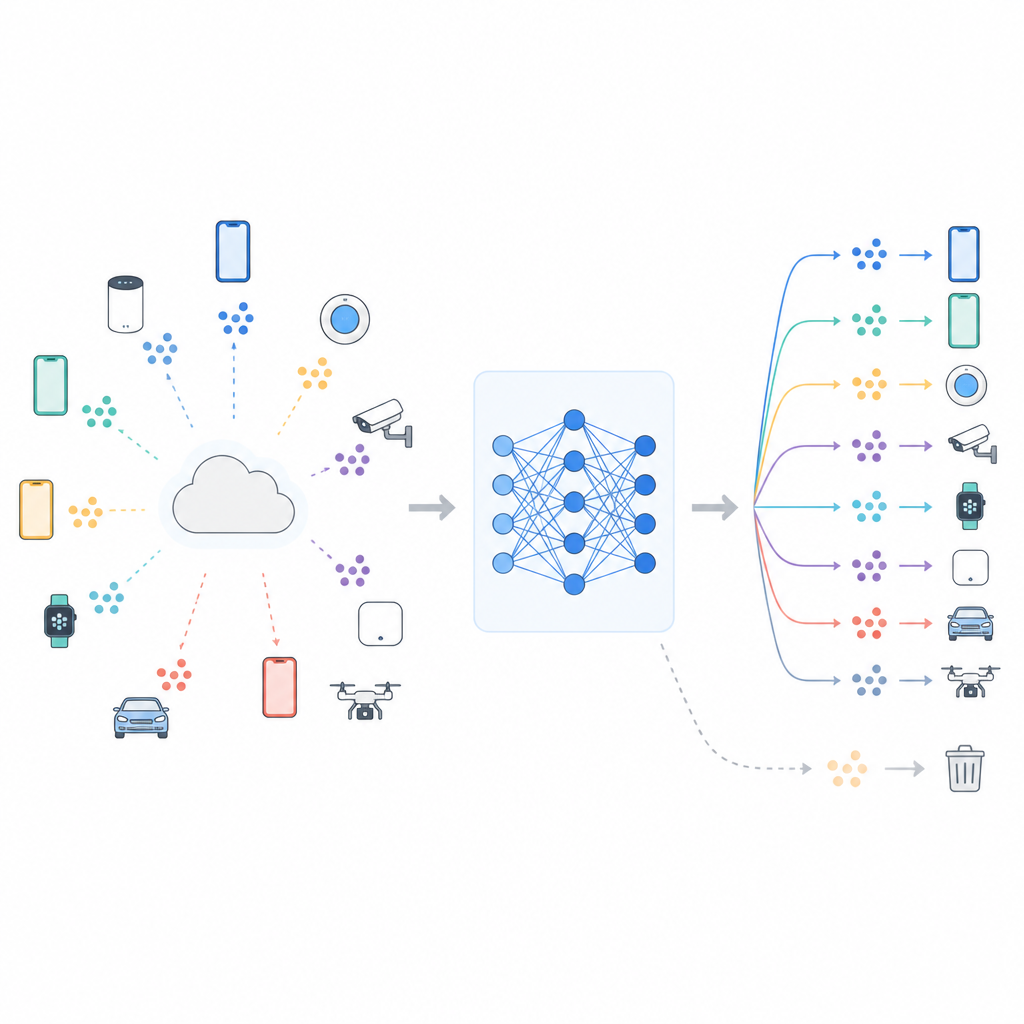
Apprendre ensemble sans partager vos données
Beaucoup de systèmes modernes utilisent l’apprentissage fédéré, où un serveur central coordonne l’entraînement tandis que les données brutes restent sur chaque appareil. Les téléphones ou capteurs mettent à jour un modèle partagé avec leurs données locales, puis n’envoient que des modifications de modèle. Cette configuration aide à protéger la confidentialité et économise la bande passante, mais n’élimine pas tous les risques. Le modèle peut toujours porter des traces de ce qu’il a vu, et des études montrent que des attaques ingénieuses peuvent parfois déterminer si des données spécifiques ont servi à l’entraînement. Des règles de confidentialité croissantes, comme le droit à l’oubli en Europe, ont donc créé une pression pour des procédures de « désapprentissage » qui réduisent la dépendance d’un modèle à des données ciblées, par exemple une certaine classe d’images ou un groupe d’utilisateurs.
Pourquoi le désapprentissage est si difficile en pratique
En théorie, la solution la plus propre est de jeter les données indésirables et de réentraîner le modèle depuis le début en n’utilisant que l’information restante. En pratique, réentraîner complètement implique d’énormes coûts de communication, une coordination répétée entre de nombreux clients et des temps d’exécution longs, surtout lorsque les données sont réparties de façon inégale entre les appareils. De plus, tenter d’oublier une connaissance peut nuire aux performances sur le reste, car les mêmes paramètres du modèle soutiennent les deux. Les auteurs montrent que la mécanique interne de l’entraînement, en particulier l’état de momentum de l’optimiseur qui lisse les mises à jour dans le temps, peut mélanger les signaux « oublier » et « retenir » de sorte que les efforts pour effacer une classe interfèrent avec les autres compétences du modèle.
Une petite tête additionnelle pour oublier
La méthode proposée, appelée FedDAM, relève ces défis en ne modifiant qu’une petite partie du modèle après qu’il ait été entraîné. Le réseau principal qui extrait les caractéristiques des données et son classificateur d’origine sont gelés. Au‑dessus d’eux, les auteurs ajoutent une nouvelle « tête auxiliaire » compacte dont le rôle est d’ajuster les prédictions finales de manière contrôlée. Pendant le désapprentissage, seule cette tête auxiliaire est mise à jour et partagée entre les appareils, ce qui réduit fortement la communication et le calcul par rapport au réentraînement du modèle complet. En agissant directement sur les scores finaux, la méthode peut déplacer les frontières de décision pour la classe cible tout en laissant intact l’extracteur de caractéristiques profondes, ce qui la rend attrayante pour des téléphones et dispositifs edge aux ressources limitées.
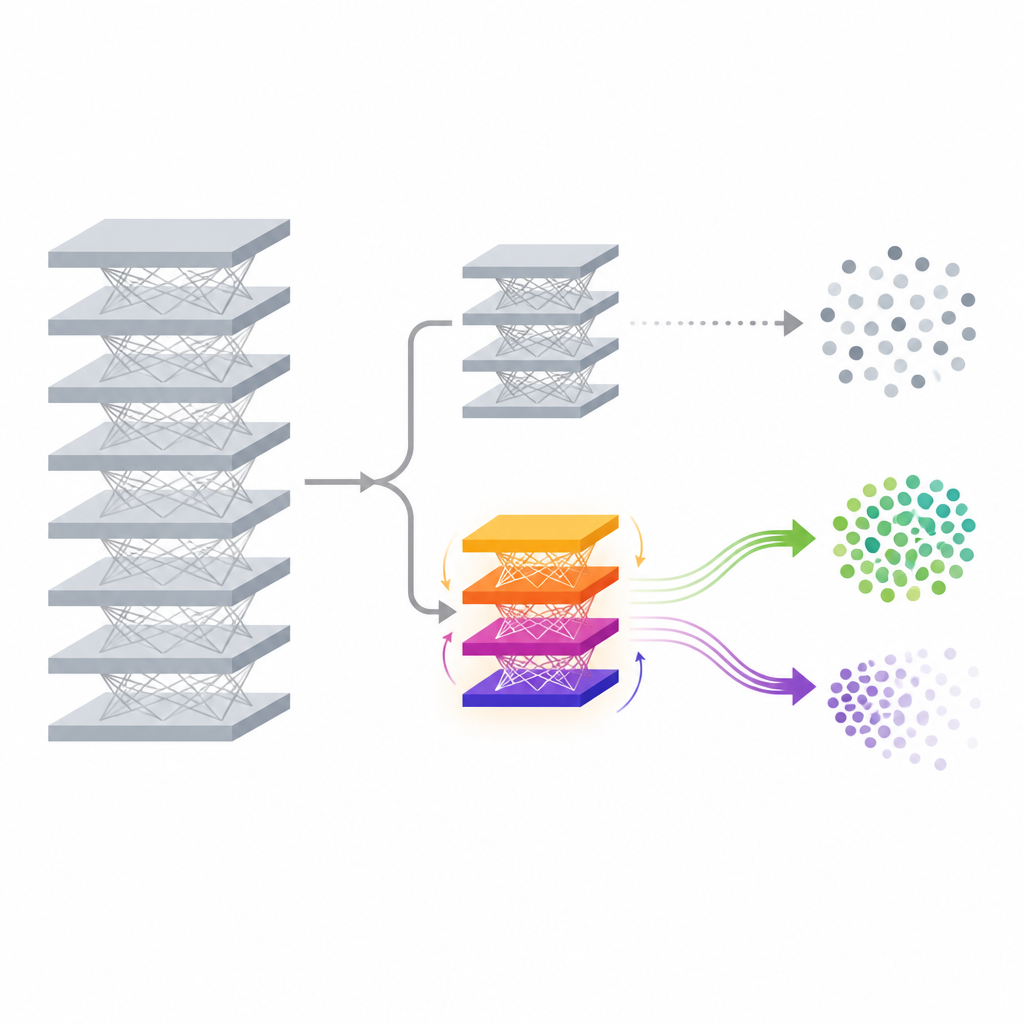
Deux flux de mémoire pour conserver et effacer
L’idée technique clé de FedDAM est de séparer les forces qui veulent oublier de celles qui veulent préserver le savoir. Chaque client participant divise ses données locales en ensembles « retenir » et « oublier », puis alterne les mises à jour basées sur chacun. Au lieu d’alimenter les deux dans un seul état de momentum, la méthode conserve deux tampons de momentum distincts, un pour la rétention et un pour l’oubli, et les combine de façon asymétrique lors de la mise à jour de la tête auxiliaire. Les mises à jour d’oubli ont une mémoire plus courte et un poids légèrement plus élevé, de sorte que le modèle réagit rapidement quand il voit des données à effacer, tout en continuant d’entendre la traction plus discrète des données retenues. Par des expériences, les auteurs montrent que ce double flux réduit le conflit direct entre les deux objectifs et aligne mieux les mises à jour sur le comportement d’oubli souhaité.
Quel est le niveau d’efficacité du désapprentissage sélectif en pratique
Les chercheurs testent FedDAM sur des jeux d’images standards, notamment CIFAR‑10, CIFAR‑100 et une version ImageNet 100 de taille moyenne, dans des conditions fédérées réalistes où chaque client ne possède qu’une tranche des données et où certains clients peuvent ne pas contenir d’exemples à oublier. Ils comparent leur méthode à plusieurs alternatives qui utilisent soit un unique momentum partagé, projettent des gradients conflictuels ou suppriment des directions chevauchantes, ainsi qu’au réentraînement complet du modèle avec compression. Dans ces études, FedDAM obtient systématiquement une meilleure précision sur les classes retenues à niveau d’oubli comparable, avec des gains d’environ 7 à 9 points de pourcentage sur des jeux plus difficiles et diversifiés. En même temps, elle consomme beaucoup moins de communication et de temps d’exécution que le réentraînement complet, même lorsque ce dernier est fortement compressé.
Ce que cela signifie pour les appareils du quotidien
Pour les non‑spécialistes, le message principal est qu’il est possible de concevoir des systèmes d’apprentissage capables ensuite de « désapprendre » certaines catégories de données de manière plus flexible, sans repartir de zéro et sans pénaliser excessivement les performances sur le reste. FedDAM propose une recette pratique pour y parvenir en contexte fédéré et edge : geler la majeure partie du modèle, n’ajuster qu’une petite tête auxiliaire et séparer soigneusement les influences des données à conserver de celles à oublier. Bien que la méthode n’offre pas de garanties formelles de confidentialité et ne puisse pas traiter tous les types de demandes de suppression, elle constitue un compromis utile entre l’inaction et le coût total du réentraînement, rapprochant l’idée du désapprentissage automatique d’un déploiement réel.
Citation: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Mots-clés: apprentissage fédéré, désapprentissage automatique, edge computing, confidentialité en IA, réseaux de neurones