Clear Sky Science · ru
Двойной асимметричный момент улучшает федеративное забывание классов в периферийных системах
Почему важно научить машины забывать
Наши телефоны, часы и домашние гаджеты постоянно учатся на данных, которые мы им даём — от фотографий и голосовых фрагментов до показаний здоровья. Но что происходит, когда законы или пользователи требуют, чтобы определённые данные были удалены не только из хранилища, но и из самого поведения моделей искусственного интеллекта? Переобучение моделей с нуля может быть медленным, затратным и иногда нереалистичным на миллионах мелких устройств. В этой статье рассматривается более лёгкий способ заставить большие распределённые системы обучения «забыть» выбранную информацию, одновременно сохраняя работоспособность по остальным задачам.
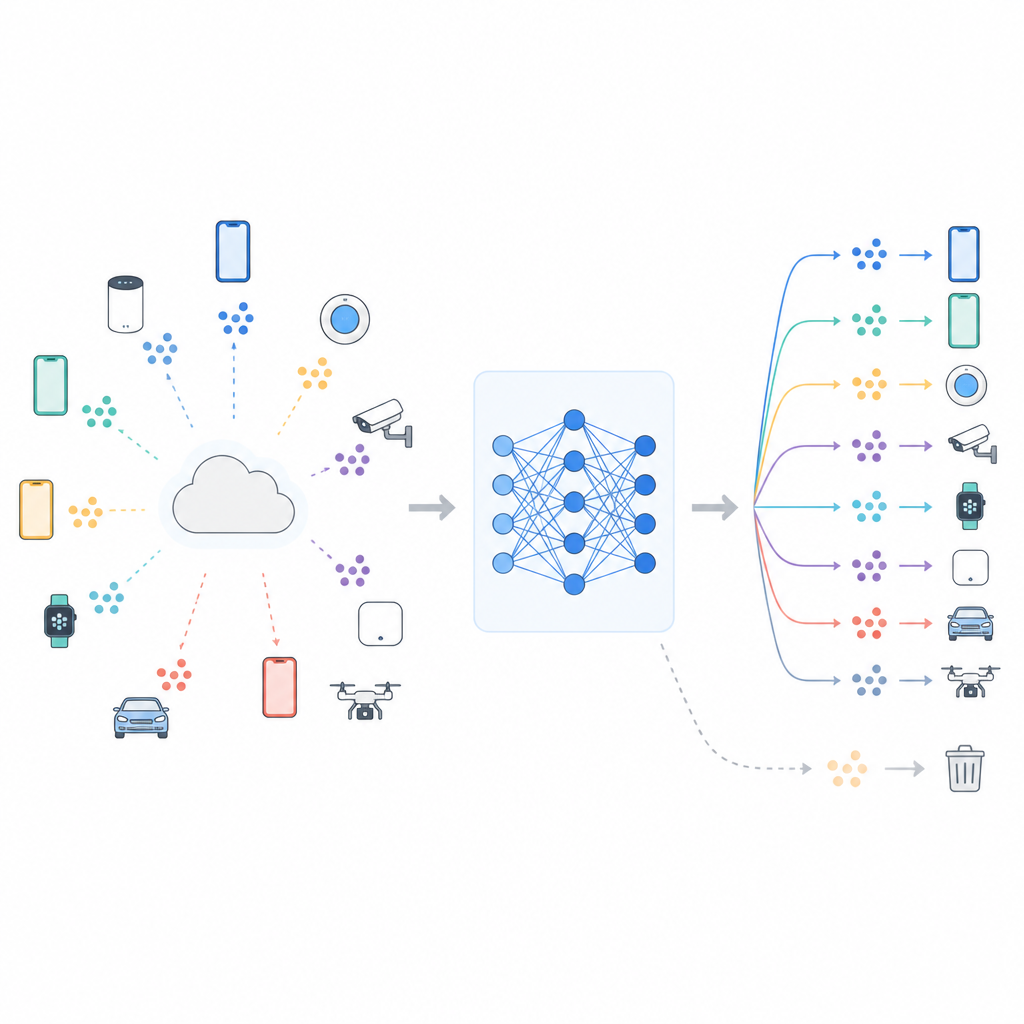
Обучаться вместе, не делясь данными
Во многих современных системах используется федеративное обучение, при котором центральный сервер координирует тренировку, а исходные данные остаются на каждом устройстве. Телефоны или сенсоры обновляют общую модель на основе локальных данных и отправляют назад только изменения модели. Такая схема помогает защищать приватность и экономит трафик, но полностью устраняет риски не может. Модель всё ещё может содержать следы того, кого или что она видела, и исследования показывают, что умелые атаки иногда позволяют определить, были ли конкретные данные использованы при обучении. Усиление правил о приватности, например европейское право на забвение, создало спрос на процедуры «машинного забывания», уменьшающие зависимость модели от назначенных данных, например одного класса изображений или группы пользователей.
Почему забывание в реальном мире так трудно
В теории самым чистым решением является удаление нежелательных данных и повторное обучение модели с нуля только на оставшейся информации. На практике полное переобучение влечёт за собой огромные коммуникационные расходы, постоянную координацию множества клиентов и длительные временные затраты, особенно когда данные неравномерно распределены по устройствам. К тому же попытки забыть одну часть знания могут навредить производительности по остальным задачам, потому что одни и те же параметры модели поддерживают оба поведения. Авторы показывают, что внутренние механизмы обучения, в частности состояние момента оптимизатора, которое сглаживает обновления во времени, могут смешивать сигналы «забыть» и «сохранить», поэтому попытки стереть один класс мешают остальным навыкам модели.
Лёгкая добавочная голова для забывания
Предложенный метод, называемый FedDAM, решает эти задачи, меняя только небольшую часть модели после того, как она уже обучена. Основная сеть, извлекающая признаки, и её первоначальный классификатор фиксируются. Поверх них авторы добавляют новую, небольшую «вспомогательную голову», задача которой — тонко корректировать итоговые предсказания. Во время процесса забывания обновляется и передаётся между устройствами только эта вспомогательная голова, что существенно снижает коммуникацию и вычислительные затраты по сравнению с переобучением всей модели. Работая напрямую с итоговыми оценками, метод может смещать границы принятия решений для целевого класса, оставляя неизменным глубокий извлекатель признаков, что делает подход привлекательным для устройств с ограниченными ресурсами.
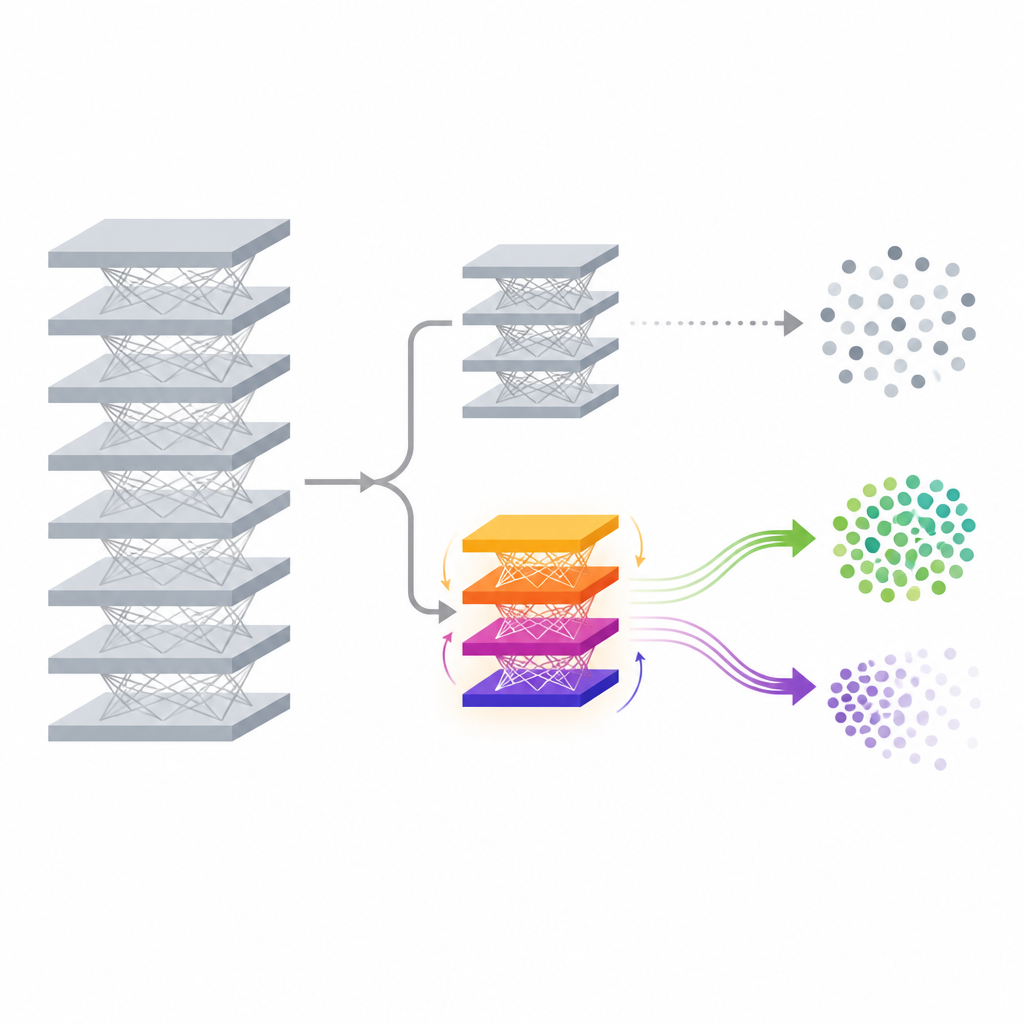
Два потока памяти для сохранения и забывания
Ключевая техническая идея FedDAM — разделить силы, стремящиеся забыть, и те, что стремятся сохранить знание. Каждый участвующий клиент делит свои локальные данные на множества «сохранить» и «забыть», затем попеременно обновляет модель на основе каждого из них. Вместо того чтобы смешивать оба потока в одном состоянии момента, метод хранит два отдельных буфера момента — один для сохранения, другой для забывания — и комбинирует их асимметрично при обновлении вспомогательной головы. Обновления, направленные на забывание, получают более короткую «память» и немного больший вес, поэтому модель быстро реагирует на данные, которые нужно стереть, при этом продолжая учитывать более спокойное влияние сохраняемых данных. В экспериментах авторы показывают, что такой двойной поток уменьшает прямой конфликт между двумя целями и делает обновления ближе к желаемому поведению забывания.
Насколько хорошо работает избирательное забывание на практике
Команда проверила FedDAM на стандартных наборах изображений, включая CIFAR-10, CIFAR-100 и средний по размеру набор ImageNet-100, в реалистичных федеративных условиях, где каждый клиент имеет лишь часть данных, а некоторые клиенты могут не иметь примеров, которые нужно забыть. Они сравнили свой метод с несколькими альтернативами, которые используют один общий момент, проецируют конфликтующие градиенты или вычищают пересекающиеся направления, а также с сжатым полным переобучением модели. Во всех исследованиях FedDAM стабильно обеспечивает лучшую точность по сохраняемым классам при сопоставимом уровне забывания, с приростами примерно на 7–9 процентных пунктов на более сложных и разнообразных наборах. При этом он использует значительно меньше коммуникаций и времени работы по сравнению с полным переобучением, даже когда последнее агрессивно сжато.
Что это значит для повседневных устройств
Для неспециалистов главный вывод в том, что возможно построить системы обучения, которые в дальнейшем смогут более гибко «забывать» определённые категории данных, не начиная всё заново и не нанося чрезмерного вреда общей производительности. FedDAM предлагает практический рецепт для этого в федеративных и периферийных сценариях: зафиксировать большую часть модели, откорректировать лишь небольшую вспомогательную голову и аккуратно разделить влияние данных, которые нужно сохранить, и тех, что нужно забыть. Хотя метод не даёт формальных гарантий приватности и не справится со всеми возможными запросами на удаление, он предлагает полезный компромисс между бездействием и полной ценой переобучения, приближая идею машинного забывания к реальному развертыванию.
Цитирование: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Ключевые слова: федеративное обучение, машинное забывание, edge-вычисления, конфиденциальность в ИИ, нейронные сети